Linux安裝docker以及部署prometheus+node_exporter+mysqld-exporter+grafana+cadvisor+Alertmanager(告警)
1、官方安裝脚本自动安装docker
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
2、启动docker
systemctl start docker
3、搜索镜像-例如搜索prometheus
docker search prom/prometheus
4、拉取镜像--这里仅列出我部署的镜像(如需拉取其他镜像请参考其他文档,尽量选择拉取数最多的进行拉取)
docker pull prom/prometheus
docker pull prom/node-exporter
docker pull grafana/grafana
docker pull prom/mysqld-exporter
docker pull google/cadvisor
5、如需要删除镜像-OPTIONS 是可选参数-可使用-f强制删除镜像(即使在运行中),在命令后指定镜像名称或ID
docker rmi [OPTIONS] IMAGE [IMAGE...]
6、查看已拉取的镜像,-a 命令是列出所有镜像,包括中间映像层
docker images -a
7、运行所需容器
docker run -itd -p 9090:9090 --name prometheus prom/prometheus
docker run -itd -p 9100:9100 --name node-exporter prom/node-exporter
docker run -itd -p 3000:3000 --name grafana grafana/grafana
docker run -d --name mysqld_exporter --restart=always -p 9104:9104 -e DATA_SOURCE_NAME="admin:admin@(IP:3306)/" prom/mysqld-exporter
docker run -v /:/rootfs:ro -v /var/run:/var/run:rw -v /sys:/sys:ro -v /var/lib/docker/:/var/lib/docker:ro -v /dev/disk/:/dev/disk:ro -p 8080:8080 -d --name=cadvisor --restart=always google/cadvisor:latest如上第4条运行容器语法各部分释义;
docker run:这是Docker命令行工具中用于运行一个新的Docker容器的命令
-d:这表示以后台模式运行容器
--name mysqld_exporter:这为新创建的容器指定一个名称,名称是mysqld_exporter
--restart=always:这表示当容器退出时,总是自动重启
-p 9104:9104:这是端口映射配置,将宿主机器的9104端口映射到容器的9104端口
-e DATA_SOURCE_NAME="admin:admin@(IP:3306)/":这设置了一个环境变量DATA_SOURCE_NAME,值为admin:admin@(IP:3306)/ 其中IP:3306是MySQL数据库的地址和端口
prom/mysqld-exporter:这是要运行的Docker镜像的名称
8、进入容器将配置文件copy出来,路径根据自己情况选择(/opt/prometheus)这是我放的路径
docker exec -it <container_id> /bin/sh (如sh不行则换成bash)
docker cp <container_id>:/etc/prometheus/prometheus.yml /opt/prometheus
9、停止容器和删除容器
docker stop <container_id>
docker rm <container_id>
10、对copy出来的配置文件重新进行配置,可自行复制(文件名:prometheus.yml)

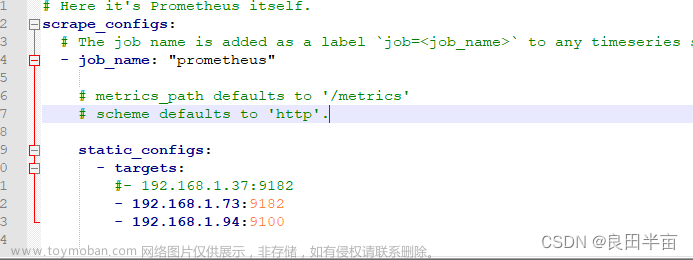
重点配置如下,可自行copy

# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
#alerting: #后续用到解开
# alertmanagers: #后续用到解开
# - static_configs: #后续用到解开
# - targets: #后续用到解开
# - IP:9093 #后续用到解开
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
#rule_files: #后续用到解开
# - "/etc/prometheus/rules.yml" #后续用到解开,这里指定容器中告警规则文件路径
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: "node-exporter"
static_configs:
- targets: ['localhost:9100'] #将localhost换成自己IP
labels:
instance: exporter
- job_name: "cadvisor"
static_configs:
- targets: ['localhost:8080']
labels:
instance: cAdvisor11、重新运行映射配置文件到容器
docker run -d -p 9090:9090 --name prometheus -v /opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus12、访问grafana--prometheus--node-exporter-cAdvisor
localhost最好换成自己的IP
http://localhost:3000

http://localhost:9090


http://localhost:9100


http://localhost:8080

13、登录grafana(默认账密为admin admin,可自行更改默认密码),配置prometheus源,type选择prometheus,输入URL后点击save & test,出现绿色提示则成功

14、导入本机仪表盘模版



15、出现如下图说明配置成功(可能会遇到 Node Exporter Dashboard 或者其他的 dashboard 出现监控数据为空的问题)最大可能性是数据未收集上来,可将时间改为最后5分钟,到此已经全部配置完成,如需配置告警规则,请继续阅读

使用grafana导入docker容器可视化监控面板,仪表盘ID:推荐(11277、193)二选一,可自行查阅其他资料获取仪表盘ID



16、接下来配置alertmanager告警
1、拉取alertmanager
docker pull prom/alertmanager
2、启动alertmanager
docker run -itd --name alertmanager prom/alertmanager
3、将容器中的配置文件copy出来,也可不用copy出来,直接在本地使用touch创建一个alertmanager.yml文件,将以下第6条中的配置文件信息copy进去,自己记住文件路径
docker cp <container_id>:/etc/alertmanager/alertmanager.yml /opt/alertmanager
4、删除alertmanager容器 -f 强制删除
docker rm -f <container_id>
5、运行容器
docker run -itd -p 9093:9093 --name alertmanager -v /opt/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml prom/alertmanager
6、配置alertmanager.yml文件-可自行复制,如下 ?号处需自行填写,以下仅演示QQ,也可配置其他邮箱(如需配置自定义告警模版,请自行搜索或留言)
global: # 全局配置
resolve_timeout: 5m # 处理超时时间,默认为5min
smtp_from: '?' # 邮件发送地址(自行配置)
smtp_smarthost: 'smtp.qq.com:465' # 邮箱SMTP 服务地址
smtp_auth_username: '?' # 邮件发送地址用户名(邮箱地址)
smtp_auth_password: '?' # 邮件发送地址授权码(自行查看qq邮箱SMTP或POP3的授权码,百度可查如何配置)
smtp_require_tls: false
route: # 设置报警的分发策略
group_by: ['alertname']
group_wait: 20s # 最初即第一次等待多久时间发送一组警报的通知
group_interval: 20m # 在发送新警报前的等待时间
repeat_interval: 10m # 发送重复警报的周期 对于email配置中,此项不可以设置过低,否则将会由于邮件发送太多频繁,被smtp服务器拒绝
receiver: 'email'
receivers: # 配置告警消息接受者信息
- name: 'email'
email_configs:
- to: '?' # #邮件接收地址(自行配置)
send_resolved: true
inhibit_rules: # 抑制规则配置
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']7、配置告警规则-此规则需要映射到prometheus容器中,自行copy,将rules.yml文件最好放置在宿主机prometheus.yml的同级目录下(如需要试验发送邮件功能,将以下内存告警规则 >80 改为 >5,试验完成后还原)
vim rules.yml
groups:
- name: Warning
rules:
- alert: NodeMemoryUsage
expr: 100 - (node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes) / node_memory_MemTotal_bytes*100 > 80
for: 1m
labels:
status: Warning
annotations:
summary: "{{$labels.instance}}: 内存使用率过高"
description: "{{$labels.instance}}: 内存使用率大于 80% (当前值: {{ $value }})"
- alert: NodeCpuUsage
expr: (1-((sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)) / (sum(increase(node_cpu_seconds_total[1m])) by (instance)))) * 100 > 70
for: 1m
labels:
status: Warning
annotations:
summary: "{{$labels.instance}}: CPU使用率过高"
description: "{{$labels.instance}}: CPU使用率大于 70% (当前值: {{ $value }})"
- alert: NodeDiskUsage
expr: 100 - node_filesystem_free_bytes{fstype=~"xfs|ext4"} / node_filesystem_size_bytes{fstype=~"xfs|ext4"} * 100 > 80
for: 1m
labels:
status: Warning
annotations:
summary: "{{$labels.instance}}: 分区使用率过高"
description: "{{$labels.instance}}: 分区使用大于 80% (当前值: {{ $value }})"
- alert: Node-UP
expr: up{job='node-exporter'} == 0
for: 1m
labels:
status: Warning
annotations:
summary: "{{$labels.instance}}: 服务宕机"
description: "{{$labels.instance}}: 服务中断超过1分钟"
- alert: TCP
expr: node_netstat_Tcp_CurrEstab > 1000
for: 1m
labels:
status: Warning
annotations:
summary: "{{$labels.instance}}: TCP连接过高"
description: "{{$labels.instance}}: 连接大于1000 (当前值: {{$value}})"
- alert: IO
expr: 100 - (avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60
for: 1m
labels:
status: Warning
annotations:
summary: "{{$labels.instance}}: 流入磁盘IO使用率过高"
description: "{{$labels.instance}}:流入磁盘IO大于60% (当前值:{{$value}})"
8、删除prometheus容器(需要时执行)
docker rm <container_id>
9、运行prometheus容器,这样就将prometheus文件夹中的prometheus.yml和rules.yml文件同时映射到容器中
docker run -d -p 9090:9090 --name prometheus -v /opt/prometheus:/etc/prometheus prom/prometheus
10、后续在本地更改配置文件后可直接重启容器,无需重复删除和运行,出现问题首先检查日志(日志:docker logs -f <container_id>)
重启:docker restart <container_id>
11、访问alertmanager,出现如下图则成功
http://localhost:9093

12、在prometheus.yml中配置告警规则文件,如下图两处,配置完成后重启prometheus容器,在上面是注释的状态,现在配置告警需要将这两处解开,具体的文件路径根据实际情况来,我这只是我自己文件的示例

13、等待几分钟会收到告警邮件,默认模版如下,可自行配置邮件模版
 文章来源:https://www.toymoban.com/news/detail-840418.html
文章来源:https://www.toymoban.com/news/detail-840418.html
以上内容根据多方资源和实际操作整理,如有疑问随时提出私信或评论文章来源地址https://www.toymoban.com/news/detail-840418.html
到了这里,关于Linux部署docker以及prometheus+node_exporter+mysqld-exporter+grafana+cadvisor+Alertmanager(告警)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!