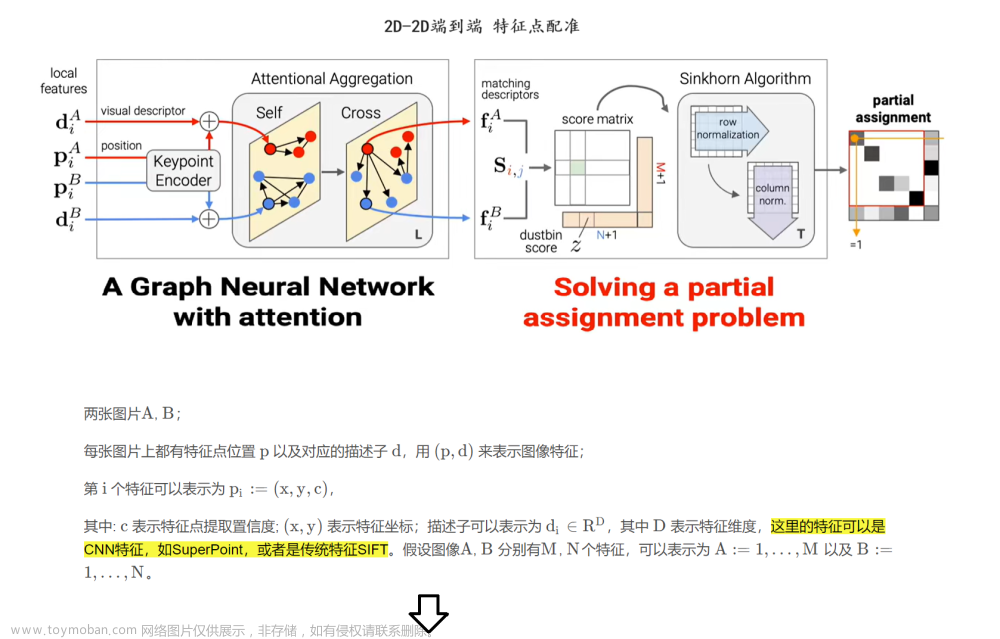
1,另一个ssfomer
我在找论文时发现,把自己的分割模型命名为ssformer的有两个:,一个论文SSformer: A Lightweight Transformer for Semantic Segmentation中提出的一种轻量级Transformer模型,结构如下

这个结构很简单,就是在用MLP层处理一下不同层的swin transformer block特征,然后融合。
这个没什么太多好说的。
2,我们要说的ssformer
我们要重点说的ssformer是Stepwise Feature Fusion: Local Guides Global这篇。
这篇论文的模型采用金字塔Transformer作为编码器,并提出了一种全新的解码器PLD。
整体结构如下:

3,编码器分支
编码器采用了PVTv2(Pyramid Vision Transformer v2)的设计,该设计在Segformer中也有所使用。PVTv2是一种用于图像识别任务的Transformer架构,它通过使用卷积操作来替代传统Transformer中的位置上的嵌入(PE)操作,以保持空间信息的一致性并提供出色的性能和稳定性。
4,解码器分支PLD
PLD的设计旨在解决Transformer模型在处理密集预测任务时可能出现的注意力分散问题,并强调局部特征以改善细节处理能力。
PLD由局部强调模块LE和渐进式特征聚合模块(SFA)组成。
LE模块使用卷积操作来混合每个补丁周围的特征,从而增加相邻补丁与中心补丁之间的关联权重,强调局部特征。由于不同深度的特征流具有不同类型的特征,LE模块在特征金字塔的不同层级上使用不同的卷积权重。
5,实验结果文章来源:https://www.toymoban.com/news/detail-840671.html
 文章来源地址https://www.toymoban.com/news/detail-840671.html
文章来源地址https://www.toymoban.com/news/detail-840671.html
到了这里,关于论文阅读 Stepwise Feature Fusion: Local Guides Global的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[论文阅读] Revisiting Feature Propagation and Aggregation in Polyp Segmentation](https://imgs.yssmx.com/Uploads/2024/02/786537-1.jpeg)