安装前准备
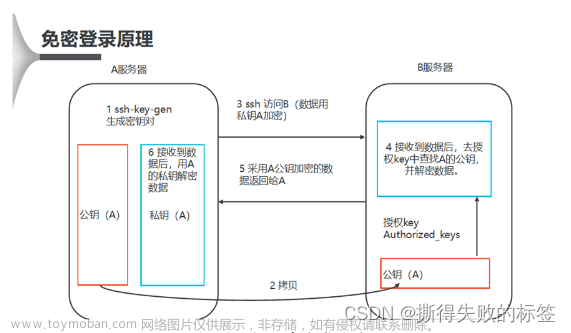
一、设置ssh免密登录
1.编辑hosts文件,添加主机名映射内容
vim /etc/hosts
添加内容:
172.17.0.2 master
172.17.0.3 slave1
172.17.0.4 slave2
2.生成公钥和私钥
ssh-keygen –t rsa
然后按三次回车
3.复制公钥到其他容器(包括自己)
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
填入yes回车,然后输入root密码即可
4.测试是否能免密登录
ssh master
ssh slave1
ssh slave2
若回显登录界面,则设置成功
(另外两个节点重复以上操作)
二、java安装及环境变量配置
1.解压jdk安装包到/opt/module中
tar –zxvf jdk安装包名 –C /opt/module
cd /opt/module
mv jdk1.8.0_192 jdk1.8(非必须)
(为了之后便利,可把jdk名改简单点,下面都以jdk1.8来写)
2.配置JAVA环境变量,编辑文件/etc/profile,添加内容,输入命令,使添加配置生效
vim /etc/profile
添加以下内容
export JAVA_HOME=/opt/module/jdk1.8(该处填入jdk路径)
export PATH=$PATH:$JAVA_HOME/bin
使配置生效
source /etc/profile
3.验证java环境变量是否配置成功
java –version
javac
若正常回显结果则代表安装配置正确
hadoop平台搭建
一、hadoop安装及环境变量配置
1.解压hadoop安装包到/opt/module中
cd /opt/software
tar -zxvf hadoop包名 -C /opt/module
cd /opt/module
mv hadoop-3.2.3 hadoop3(非必须)
2.配置hadoop环境变量,编辑文件/etc/profile,添加内容,输入命令使其生效
vim /etc/profile
添加内容
export HADOOP_HOME=/opt/module/hadoop3
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使配置生效
source /etc/profile
3.验证hadoop环境变量是否配置成功
hadoop version
slave1、slave2使用scp命令分发到slave1、slave2
scp传输文件命令:scp -r 要传输的目录 主机名:传输到的位置
-r传输目录,传送文件可不加
scp -r module slave1:/opt
scp -r module slave2:/opt
scp /etc/profile slave1:/etc/profile
scp /etc/profile slave2:/etc/profile
二、Hadoop集群配置
集群部署规划
注意:
- Namenode和secondarynamenode不要安装在同一台服务器
- Resourcemanagery也很消耗内存,不要和namenode、secondarynamenode配置在同一台机器上
| master |
slave1 |
slave2 |
|
| HDFS |
Namenode Datanode |
datanode |
Secondarynamenode datanode |
| YARN |
nodemanager |
Resourcemanager nodemanager |
nodemanager |
1.进入到/opt/module/hadoop3/etc/hadoop目录下
cd /opt/module/hadoop3/etc/hadoop
2.修改core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml四个配置文件
(hadoop默认配置文件在/opt/module/hadoop3/share/hadoop中)
核心配置文件core-site.xml
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9820</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
(hadoop.tmp.dir是Hadoop文件系统依赖的基础配置,默认存放在/tmp/{$user}下。但是存放在/tmp下是不安全的,因为系统重启后文件有可能被删除,所以会指向另外的路径)
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop3/data</value>
</property>
</configuration>
HDFS配置文件hdfs-site.xml
<configuration>
<!-- 指定NameNode的web端访问地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!-- 指定SecondaryNameNode的web端访问地址 -->(该部分可能不需要)
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:9868</value>
</property>
</configuration>
YARN配置文件yarn-site.xml
<configuration>
<!-- 设置ResourceManager -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
<!-- 配置yarn的shuffle服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
MapReduce配置文件mapred-site.xml
<configuration>
<!-- 指定MapReduce作业执行时,使用YARN进行资源调度-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3.修改hadoop-env.sh文件
vim hadoop-env.sh
添加内容
export JAVA_HOME=/opt/module/jdk1.8
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
4.修改workers文件
vim workers
删除原来的localhost修改为
master
slave1
slave2
5.用scp分发第一、二步的文件到所以节点
cd /opt/module
scp –r hadoop3 slave1:/opt/module
scp –r hadoop3 slave2:/opt/module
6.在master节点初始化namenode
hdfs namenode -format
7.启动hadoop集群
start-dfs.sh
start-yarn.sh(yarn在哪个节点,就在哪个节点启动)
或
start-all.sh
8.查看java进程
jps
9.检查是否成功启动hadoop集群
打开网址http://master:9870(成功打开则说明启动成功)
扩展一、历史服务器配置
1.配置mapred-site.xml
添加内容:
<!--历史服务器端地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!—历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
2.分发配置到其他节点文章来源:https://www.toymoban.com/news/detail-840817.html
3.启动历史服务器
mapred --daemon start historyserver
扩展二、日志聚集功能配置
1.配置yarn-site.xml
添加内容
<!—开启日志聚集功能-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!—设置日志聚集服务器地址-->
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs</value>
</property>
<!—设置日志保留时间为7天-->
<property>
<name>yarn.log-aggregation.retain</name>
<value>604800</value>
</property>
2.分发配置到其他节点
3.重启yarn、historyserser文章来源地址https://www.toymoban.com/news/detail-840817.html
到了这里,关于hadoop平台完全分布式搭建的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!