本章将和大家分享如何通过 Elasticsearch 实现自动补全查询功能。
一、自动补全-安装拼音分词器
1、自动补全需求说明
当用户在搜索框输入字符时,我们应该提示出与该字符有关的搜索项,如图:

2、使用拼音分词
要实现根据字母做补全,就必须对文档按照拼音分词。在 GitHub 上恰好有 Elasticsearch 的拼音分词插件。地址:https://github.com/infinilabs/analysis-pinyin
安装方式与IK分词器一样,分三步:
1)解压
2)上传到 Elasticsearch 的 plugins 目录下
3)重启 Elasticsearch
4)测试
首先从 GitHub 上下载 Elasticsearch 的拼音分词插件,如下所示:

下载完成后,将其解压出来,然后将解压后的文件夹名称重命名为 “py” ,最后把它复制到 Elasticsearch 的 plugins 目录下,如下所示:


安装完成后,需要重启一下 Elasticsearch ,如下所示:

可以发现拼音分词器插件安装成功了。
最后我们来测试一下:
# 测试拼音分词 POST /_analyze { "text": "如家酒店还不错", "analyzer": "pinyin" }

运行结果如下:
{ "tokens" : [ { "token" : "ru", "start_offset" : 0, "end_offset" : 0, "type" : "word", "position" : 0 }, { "token" : "rjjdhbc", "start_offset" : 0, "end_offset" : 0, "type" : "word", "position" : 0 }, { "token" : "jia", "start_offset" : 0, "end_offset" : 0, "type" : "word", "position" : 1 }, { "token" : "jiu", "start_offset" : 0, "end_offset" : 0, "type" : "word", "position" : 2 }, { "token" : "dian", "start_offset" : 0, "end_offset" : 0, "type" : "word", "position" : 3 }, { "token" : "hai", "start_offset" : 0, "end_offset" : 0, "type" : "word", "position" : 4 }, { "token" : "bu", "start_offset" : 0, "end_offset" : 0, "type" : "word", "position" : 5 }, { "token" : "cuo", "start_offset" : 0, "end_offset" : 0, "type" : "word", "position" : 6 } ] }
从该查询结果可以看出拼音分词器存在的一些问题:
1)第一个问题是拼音分词器它不会分词。
2)第二个问题是它把一句话里面的每一个字都形成了拼音,这对我们来说不仅没什么用,而且还会占用空间。
3)第三个问题是拼音分词结果中没有汉字只剩下了拼音,而实际上我们用拼音搜索的情况是占少数的,大多数情况下其实我们是想通过中文去搜索的,所以说有拼音是锦上添花,但是不能把汉字给扔了,汉字也得保留。
这是我们拼音分词器目前所面临的几个问题,因此我们就必须得对拼音分词器做一些配置或者叫做自定义了,那么怎么样才能实现自定义分词器呢?
二、自动补全-自定义分词器
Elasticsearch中分词器(analyzer)的组成包含三部分:
- character filters:在tokenizer之前对文本进行处理。例如:删除字符、替换字符。
- tokenizer:将文本按照一定的规则切割成词条(term)。例如:keyword 就是不分词、还有ik_smart 。
- tokenizer filter:对tokenizer输出的词条做进一步的处理。例如:大小写转换、同义词处理、拼音处理等。

我们可以在创建索引库时,通过settings来配置自定义的analyzer(分词器):
PUT /test { "settings": { "analysis": { "analyzer": { //自定义分词器 "my_analyzer": { //自定义分词器的名称 "tokenizer": "ik_max_word", "filter": "pinyin" } } } } }
上面这个只是解决了拼音分词器分词的问题,因此还需要对拼音分词器做进一步的定制,如下所示:
# 自定义拼音分词器 PUT /test { "settings": { "analysis": { "analyzer": { //自定义分词器 "my_analyzer": { //自定义分词器名称 "tokenizer": "ik_max_word", "filter": "py" //过滤器名称,可以是自定义的过滤器 } }, "filter": { //自定义tokenizer filter "py": { //自定义过滤器的名称,可随意取 "type": "pinyin", //过滤器类型,这里是pinyin "keep_full_pinyin": false, //修改可选参数,具体可参考拼音分词器GitHub官网 "keep_joined_full_pinyin": true, "keep_original": true, "limit_first_letter_length": 16, "remove_duplicated_term": true, "none_chinese_pinyin_tokenize": false } } } }, "mappings": { "properties": { "name": { "type": "text", "analyzer": "my_analyzer" //使用自定义分词器 } } } }
拼音分词器更多可选参数可参考GitHub官网:https://github.com/infinilabs/analysis-pinyin
test索引库创建完成后,下面我们来测试下:
# 测试自定义分词器 POST /test/_analyze { "text": [ "如家酒店还不错" ], "analyzer": "my_analyzer" }
注意:在test索引库中自定义的分词器也只能在test索引库中使用。
运行结果如下:

{ "tokens" : [ { "token" : "如家", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0 }, { "token" : "rujia", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0 }, { "token" : "rj", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0 }, { "token" : "酒店", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 1 }, { "token" : "jiudian", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 1 }, { "token" : "jd", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 1 }, { "token" : "还不", "start_offset" : 4, "end_offset" : 6, "type" : "CN_WORD", "position" : 2 }, { "token" : "haibu", "start_offset" : 4, "end_offset" : 6, "type" : "CN_WORD", "position" : 2 }, { "token" : "hb", "start_offset" : 4, "end_offset" : 6, "type" : "CN_WORD", "position" : 2 }, { "token" : "不错", "start_offset" : 5, "end_offset" : 7, "type" : "CN_WORD", "position" : 3 }, { "token" : "bucuo", "start_offset" : 5, "end_offset" : 7, "type" : "CN_WORD", "position" : 3 }, { "token" : "bc", "start_offset" : 5, "end_offset" : 7, "type" : "CN_WORD", "position" : 3 } ] }
可以看出,搜索结果中既有汉字、又有拼音、还有分词,这完全符合我们的预期。
但是需要特别注意的是:拼音分词器适合在创建倒排索引的时候使用,不适合在搜索的时候使用。下面我们通过一个例子来说明:
往test索引库中加入2条测试数据,如下所示:
POST /test/_doc/1 { "id": 1, "name": "狮子" } POST /test/_doc/2 { "id": 2, "name": "虱子" }
接着我们搜索“掉入狮子笼咋办”,如下所示:
GET /test/_search { "query": { "match": { "name": "掉入狮子笼咋办" } } }
运行结果如下:

可以发现,其实我们是想找“狮子”,但是它把同音字“虱子” 也搜索出来了。下面我们通过一张图来了解一下这个过程,如下所示:

由此可见,拼音分词器适合在创建倒排索引的时候使用,但不能在搜索的时候使用。
正确的做法是:字段在创建倒排索引时应该用my_analyzer分词器,而字段在搜索时应该使用ik_smart分词器。如下所示:
# 自定义拼音分词器 PUT /test { "settings": { "analysis": { "analyzer": { //自定义分词器 "my_analyzer": { //自定义分词器名称 "tokenizer": "ik_max_word", "filter": "py" //过滤器名称,可以是自定义的过滤器 } }, "filter": { //自定义tokenizer filter "py": { //自定义过滤器的名称,可随意取 "type": "pinyin", //过滤器类型,这里是pinyin "keep_full_pinyin": false, //修改可选参数,具体可参考拼音分词器GitHub官网 "keep_joined_full_pinyin": true, "keep_original": true, "limit_first_letter_length": 16, "remove_duplicated_term": true, "none_chinese_pinyin_tokenize": false } } } }, "mappings": { "properties": { "name": { "type": "text", "analyzer": "my_analyzer", //创建倒排索引时使用自定义分词器 "search_analyzer": "ik_smart" //搜索时应该使用ik_smart分词器 } } } }
总结:
1、如何使用拼音分词器?
- 下载 pinyin 分词器
- 解压并放到 Elasticsearch 的 plugins 目录
- 重启即可
2、如何自定义分词器?
- 创建索引库时,在 settings 中配置,可以包含三部分
- character filter
- tokenizer
- filter
3、拼音分词器注意事项?
- 为了避免搜索到同音字,搜索时不要使用拼音分词器。
三、自动补全-DSL实现自动补全查询
Elasticsearch 提供了 Completion Suggester 查询来实现自动补全功能。官方文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.6/search-suggesters.html#completion-suggester
这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
- 参与补全查询的字段必须是completion类型。
- 字段的内容一般是用来补全的多个词条形成的数组。
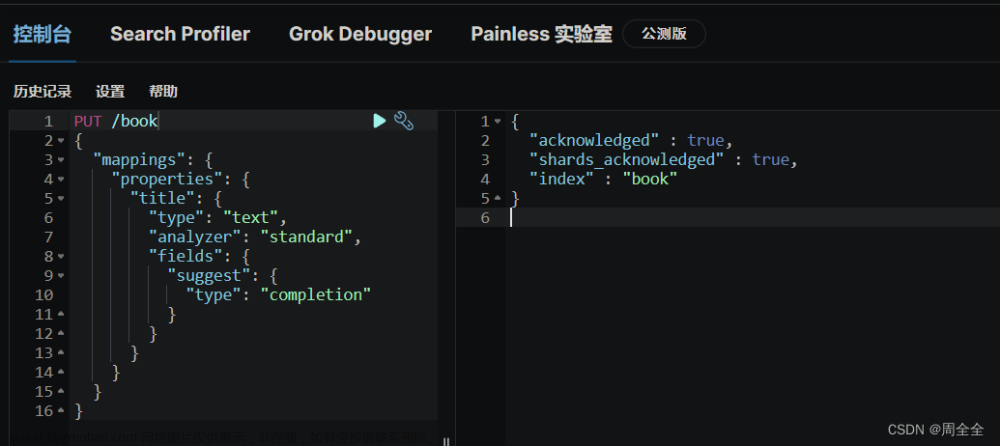
# 创建索引库 PUT test { "mappings": { "properties": { "title": { "type": "completion" } } } }
# 示例数据 POST test/_doc { "title": [ "Sony", "WH-1000XM3" ] } POST test/_doc { "title": [ "SK-II", "PITERA" ] } POST test/_doc { "title": [ "Nintendo", "switch" ] }
查询语法如下:
# 自动补全查询 GET /test/_search { "suggest": { "title_suggest": { //自动补全查询的名称(自定义的名称) "text": "s", //搜索关键字 "completion": { "field": "title", //自动补全查询的字段 "skip_duplicates": true, //跳过重复的 "size": 10 //获取前10条结果 } } } }
查询结果如下:

{ "took" : 0, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 0, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "suggest" : { "title_suggest" : [ { "text" : "s", "offset" : 0, "length" : 1, "options" : [ { "text" : "SK-II", "_index" : "test", "_type" : "_doc", "_id" : "2CJaPY4Bne6OHhy3cho1", "_score" : 1.0, "_source" : { "title" : [ "SK-II", "PITERA" ] } }, { "text" : "Sony", "_index" : "test", "_type" : "_doc", "_id" : "1yJaPY4Bne6OHhy3WBoZ", "_score" : 1.0, "_source" : { "title" : [ "Sony", "WH-1000XM3" ] } }, { "text" : "switch", "_index" : "test", "_type" : "_doc", "_id" : "2SJaPY4Bne6OHhy3fBod", "_score" : 1.0, "_source" : { "title" : [ "Nintendo", "switch" ] } } ] } ] } }
自动补全对字段的要求:
- 类型是completion类型
- 字段值是多词条的数组
四、自动补全-酒店数据自动补全(案例)
案例:实现hotel索引库的自动补全、拼音搜索功能
实现思路如下:
1、修改hotel索引库结构,设置自定义拼音分词器。
2、修改索引库的name、all字段,使用自定义分词器。
3、索引库添加一个新字段suggestion,类型为completion类型,使用自定义的分词器。
4、给HotelDoc类添加suggestion字段,内容包含brand、business 。
5、重新导入数据到hotel索引库
注意:name、all是可分词的,自动补全的brand、business是不可分词的,要使用不同的分词器组合。
# 创建酒店数据索引库 PUT /hotel { "settings": { "analysis": { "analyzer": { "text_anlyzer": { //自定义分词器,在创建倒排索引时使用 "tokenizer": "ik_max_word", "filter": "py" //自定义过滤器py }, "completion_analyzer": { //自定义分词器,用于实现自动补全 "tokenizer": "keyword", //不分词 "filter": "py" //自定义过滤器py } }, "filter": { //自定义tokenizer filter "py": { //自定义过滤器的名称,可随意取 "type": "pinyin", "keep_full_pinyin": false, //可选参数配置,具体可参考拼音分词器Github官网 "keep_joined_full_pinyin": true, "keep_original": true, "limit_first_letter_length": 16, "remove_duplicated_term": true, "none_chinese_pinyin_tokenize": false } } } }, "mappings": { "properties": { "id": { "type": "keyword" //不分词 }, "name": { "type": "text", //分词 "analyzer": "text_anlyzer", //在创建倒排索引时使用自定义分词器text_anlyzer "search_analyzer": "ik_smart", //在搜索时使用ik_smart "copy_to": "all" //拷贝到all字段 }, "address": { "type": "keyword", "index": false //不创建倒排索引,不参与搜索 }, "price": { "type": "integer" }, "score": { "type": "integer" }, "brand": { "type": "keyword", "copy_to": "all" //拷贝到all字段 }, "city": { "type": "keyword" }, "starName": { "type": "keyword" }, "business": { "type": "keyword", "copy_to": "all" //拷贝到all字段 }, "location": { "type": "geo_point" //geo_point地理坐标类型 }, "pic": { "type": "keyword", "index": false //不创建倒排索引,不参与搜索 }, "all": { //该字段主要用于搜索,没有实际意义,且在搜索结果的原始文档中你是看不到该字段的 "type": "text", "analyzer": "text_anlyzer", //在创建倒排索引时使用自定义分词器text_anlyzer "search_analyzer": "ik_smart" //在搜索时使用ik_smart }, "suggestion": { //自动补全搜索字段 "type": "completion", //completion为自动补全类型 "analyzer": "completion_analyzer" //自动补全使用自定义分词器completion_analyzer } } } }
由于hotel索引库发生了变更,因此我们需要重新初始化一下ES的数据,此处我采用了.net代码实现了将酒店数据批量导入到ES中,关键代码如下所示:
Hotel类(酒店数据):


using SqlSugar; namespace Demo.Domain.Entities { /// <summary> /// 酒店数据 /// </summary> [SugarTable("tb_hotel")] //指定数据库表名 public class Hotel { /// <summary> /// 酒店id /// </summary> [SugarColumn(IsPrimaryKey = true)] //数据库是主键需要加上IsPrimaryKey public long id { get; set; } /// <summary> /// 酒店名称 /// </summary> public string name { get; set; } /// <summary> /// 酒店地址 /// </summary> public string address { get; set; } /// <summary> /// 酒店价格 /// </summary> public int price { get; set; } /// <summary> /// 酒店评分 /// </summary> public int score { get; set; } /// <summary> /// 酒店品牌 /// </summary> public string brand { get; set; } /// <summary> /// 所在城市 /// </summary> public string city { get; set; } /// <summary> /// 酒店星级 /// </summary> [SugarColumn(ColumnName = "star_name")] //指定数据库表字段 public string starName { get; set; } /// <summary> /// 商圈 /// </summary> public string business { get; set; } /// <summary> /// 纬度 /// </summary> public string latitude { get; set; } /// <summary> /// 经度 /// </summary> public string longitude { get; set; } /// <summary> /// 酒店图片 /// </summary> public string pic { get; set; } } }
HotelDoc类(酒店数据对应的ES文档):
using System; namespace Demo.Domain.Docs { /// <summary> /// 酒店数据对应的ES文档 /// </summary> public class HotelDoc { /// <summary> /// 酒店id /// </summary> public long id { get; set; } /// <summary> /// 酒店名称 /// </summary> public string name { get; set; } /// <summary> /// 酒店地址 /// </summary> public string address { get; set; } /// <summary> /// 酒店价格 /// </summary> public int price { get; set; } /// <summary> /// 酒店评分 /// </summary> public int score { get; set; } /// <summary> /// 酒店品牌 /// </summary> public string brand { get; set; } /// <summary> /// 所在城市 /// </summary> public string city { get; set; } /// <summary> /// 酒店星级 /// </summary> public string starName { get; set; } /// <summary> /// 商圈 /// </summary> public string business { get; set; } /// <summary> /// 纬度 /// </summary> //public string latitude { get; set; } /// <summary> /// 经度 /// </summary> //public string longitude { get; set; } /// <summary> /// 地理坐标字段(将经度和纬度字段合并成一个地理坐标字段) /// 将经度和纬度的字段值用英文逗号拼在一起,例如:"40.048969, 116.619566" /// </summary> public string location { get; set; } /// <summary> /// 酒店图片 /// </summary> public string pic { get; set; } /// <summary> /// 自动补全搜索字段 /// </summary> public List<string> suggestion { get; set; } } }
Hotel类 和 HotelDoc类 二者的映射关系:
using AutoMapper; using Demo.Domain.Docs; using Demo.Domain.Entities; namespace Demo.Domain.AutoMapperConfigs { public class MyProfile : Profile { public MyProfile() { // 配置 mapping 规则 CreateMap<Hotel, HotelDoc>() .AfterMap((tbl, doc) => { #region 地理坐标字段处理 if (!string.IsNullOrEmpty(tbl.latitude) && !string.IsNullOrEmpty(tbl.longitude)) { //将经度和纬度的字段值用英文逗号拼在一起,例如:"40.048969, 116.619566" doc.location = string.Format(@"{0}, {1}", tbl.latitude, tbl.longitude); } #endregion #region 自动补全搜索字段处理 var suggestionList = new List<string>(); if (!string.IsNullOrEmpty(tbl.brand)) { //品牌 suggestionList.Add(tbl.brand); } if (!string.IsNullOrEmpty(tbl.business)) { //商圈 if (tbl.business.Contains("/")) { suggestionList.AddRange(tbl.business.Split('/')); } else { suggestionList.Add(tbl.business); } } doc.suggestion = suggestionList; #endregion }); } } }
将酒店数据批量插入到ES中:
using Microsoft.AspNetCore.Mvc; using AutoMapper; using Demo.Domain.Docs; using Demo.Domain.Entities; using Demo.Infrastructure.Repositories; using TianYaSharpCore.Elasticsearch; namespace Demo.MVC.Controllers { public class HomeController : Controller { private readonly HotelRepository _hotelRepository; private readonly IElasticClientProvider _elasticClientProvider; private readonly IMapper _mapper; public HomeController(HotelRepository hotelRepository, IElasticClientProvider elasticClientProvider, IMapper mapper) { _hotelRepository = hotelRepository; _elasticClientProvider = elasticClientProvider; _mapper = mapper; } public async Task<IActionResult> Index() { //从数据库中查出所有的酒店数据 var hotelList = await _hotelRepository._sqlSugarClient.Queryable<Hotel>().ToListAsync(); //实体转换 var hotelDocList = _mapper.Map<List<HotelDoc>>(hotelList); //使用Nest将酒店数据批量插入到ES中 var asyncBulkIndexResponse = await _elasticClientProvider.ElasticLinqClient.BulkAsync(bulk => bulk .Index("hotel") .IndexMany(hotelDocList) ); return View(); } } }
ES数据初始化完成后,最后我们再去试一下酒店数据的自动补全查询,如下所示:
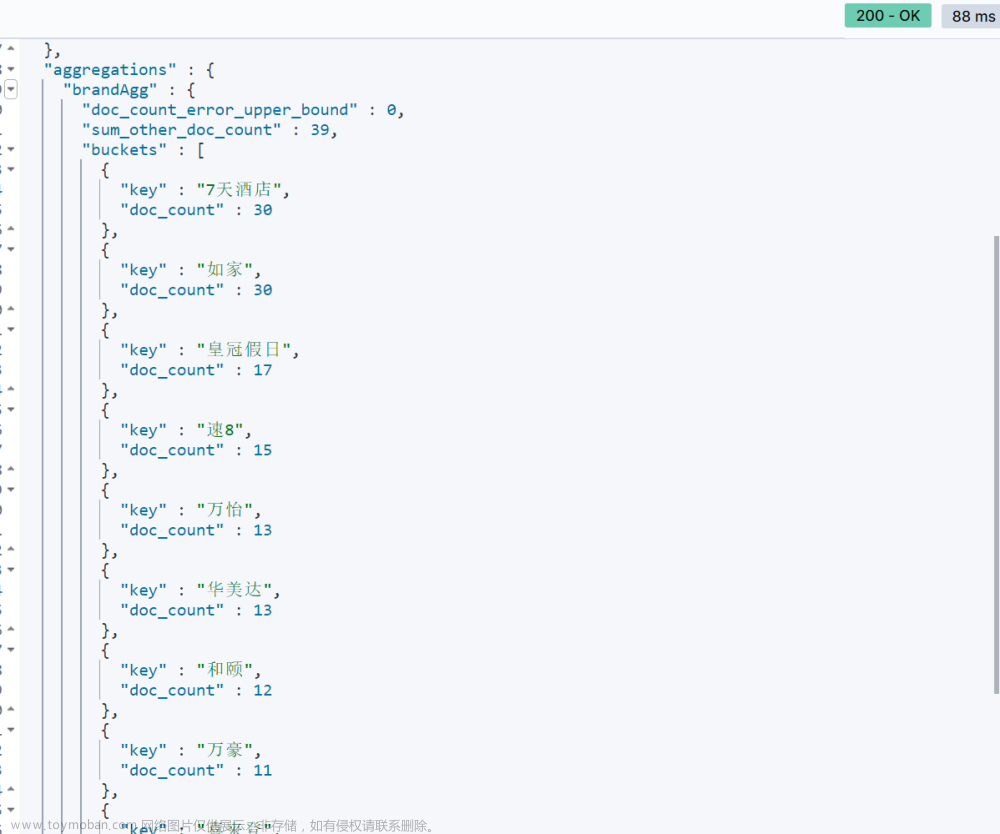
# 自动补全查询 GET /hotel/_search { "suggest": { "mySuggestion": { "text": "sd", "completion": { "field": "suggestion", "skip_duplicates": true, "size": 10 } } } }
运行结果如下所示:
{ "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 0, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "suggest" : { "mySuggestion" : [ { "text" : "sd", "offset" : 0, "length" : 2, "options" : [ { "text" : "上地产业园", "_index" : "hotel", "_type" : "_doc", "_id" : "2359697", "_score" : 1.0, "_source" : { "id" : 2359697, "name" : "如家酒店(北京上地安宁庄东路店)", "address" : "清河小营安宁庄东路18号20号楼", "price" : 420, "score" : 46, "brand" : "如家", "city" : "北京", "starName" : "二钻", "business" : "上地产业园/西三旗", "location" : "40.041322, 116.333316", "pic" : "https://m.tuniucdn.com/fb3/s1/2n9c/2wj2f8mo9WZQCmzm51cwkZ9zvyp8_w200_h200_c1_t0.jpg", "suggestion" : [ "如家", "上地产业园", "西三旗" ] } }, { "text" : "首都机场", "_index" : "hotel", "_type" : "_doc", "_id" : "395702", "_score" : 1.0, "_source" : { "id" : 395702, "name" : "北京首都机场希尔顿酒店", "address" : "首都机场3号航站楼三经路1号", "price" : 222, "score" : 46, "brand" : "希尔顿", "city" : "北京", "starName" : "五钻", "business" : "首都机场/新国展地区", "location" : "40.048969, 116.619566", "pic" : "https://m.tuniucdn.com/fb2/t1/G6/M00/52/10/Cii-U13ePtuIMRSjAAFZ58NGQrMAAGKMgADZ1QAAVn_167_w200_h200_c1_t0.jpg", "suggestion" : [ "希尔顿", "首都机场", "新国展地区" ] } } ] } ] } }
至此本文就全部介绍完了,如果觉得对您有所启发请记得点个赞哦!!!
Demo源码:
链接:https://pan.baidu.com/s/1HohQqo1Mnycij7la07zZGw 提取码:q807
此文由博主精心撰写转载请保留此原文链接:https://www.cnblogs.com/xyh9039/p/18063462文章来源:https://www.toymoban.com/news/detail-840916.html
版权声明:如有雷同纯属巧合,如有侵权请及时联系本人修改,谢谢!!!文章来源地址https://www.toymoban.com/news/detail-840916.html
到了这里,关于Elasticsearch 系列(四)- DSL实现自动补全查询的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![elasticsearch[四]-数据聚合排序查询、搜索框自动补全、数据同步、集群](https://imgs.yssmx.com/Uploads/2024/01/805161-1.png)