引言
Apache Kafka作为一个高度可扩展且具有高效性的消息中间件,已经成为现代大数据生态系统中的核心组件之一。在本文中,我们将专注于Kafka中的一个重要角色——生产者(Producer),探讨其核心功能、工作原理及其关键配置项,旨在帮助读者更好地理解和优化Kafka生产者的使用。
一、Kafka生产者概述
Apache Kafka生产者是数据源端的重要组件,负责将消息有效地推送到Kafka集群中的指定主题(Topic)。生产者实现了将不同格式的数据序列化后发送到Kafka,支持灵活的分区策略以确保消息均匀分布或者按照业务逻辑路由。
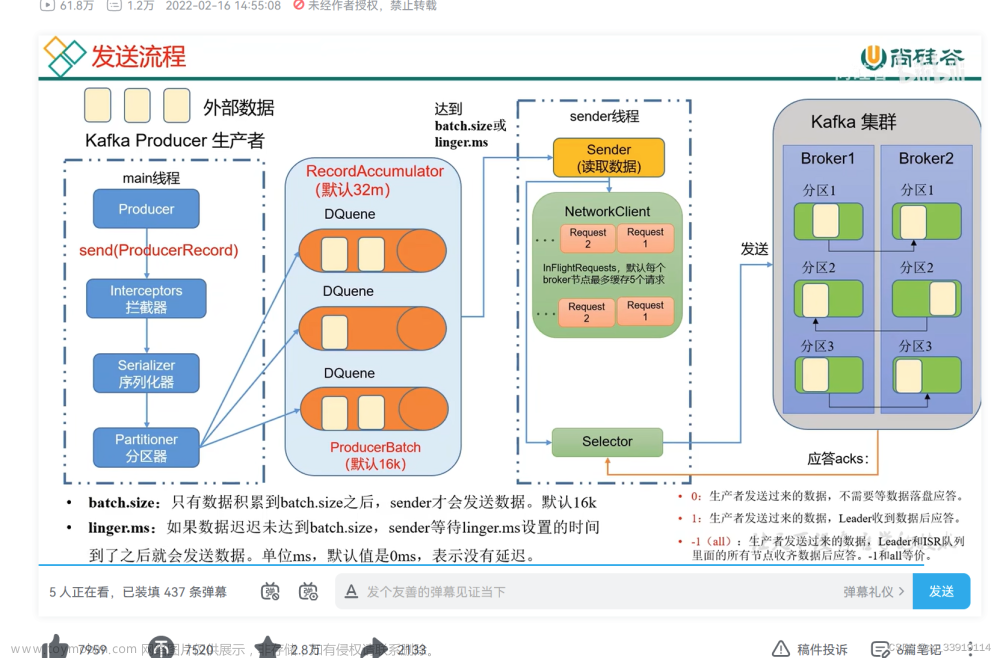
二、生产者工作流程
1. 消息序列化:
生产者需要设置相应的序列化器,例如`StringSerializer`、`ByteArraySerializer`或其他自定义序列化类,用于将消息内容转换为字节流,以便在网络上传输。例如,配置属性`ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG`用于指定值的序列化方式。
2. 分区选择:
生产者可以根据消息键(Key)通过不同的分区策略(如默认的“轮询”策略、基于Key的哈希策略等)确定消息应该进入哪个分区。这种设计有利于数据的分散存储和并行处理。
3. 批处理与压缩:
生产者支持批处理消息,通过设置`batch.size`和`linger.ms`参数来优化网络I/O和提升性能。当满足一定条件时,多个消息会被一起发送,同时还可以启用GZIP、Snappy或LZ4等压缩算法,进一步减少网络带宽占用。
4. 幂等性与事务性保证:
Kafka生产者提供了幂等性和事务性两种模式以增强数据一致性。在幂等模式下,生产者能够确保同一消息仅被投递一次;而在事务性模式下,生产者能在一个事务内保证一组消息要么全部成功投递,要么全部失败。
三、生产者高级配置与优化
1. 内存管理:
优化内存池参数是提升生产者性能的关键步骤之一。适当增大`batchSize`和`linger.ms`可以允许消息在内存中等待更长时间,形成较大的批次进行发送,从而减少网络开销。同时,合理设置`max.block.ms`可以防止生产者阻塞过久,确保消息不会在内存中积压。
2. 错误处理与重试:
生产者具备自动重试机制,对于网络故障或Broker不可用等情况,可以重新尝试发送失败的消息。通过配置重试策略以及背压(backpressure)机制,生产者可以在保持稳定性的同时适应突发流量。
四、实战示例与最佳实践
在实际应用中,一个典型的Kafka生产者实例创建代码片段如下:文章来源:https://www.toymoban.com/news/detail-840929.html
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.ACKS_CONFIG, "all"); // 确保所有副本都已接收到消息
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384); // 设置批处理大小
props.put(ProducerConfig.LINGER_MS_CONFIG, 100); // 延迟提交以形成更大的批次
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 发送消息
ProducerRecord<String, String> record = new ProducerRecord<>("my-topic", "key", "value");
producer.send(record);
// 关闭生产者
producer.close();总结,掌握Kafka生产者的特性和优化方法对于构建高效可靠的数据管道至关重要。通过对生产者的精细化配置和管理,不仅能有效提高系统的吞吐量,还能确保在复杂环境下数据的一致性和完整性。在实际应用中,不断监控和调整生产者的各项参数,结合具体业务需求持续优化,方能使Kafka发挥出最大价值。文章来源地址https://www.toymoban.com/news/detail-840929.html
到了这里,关于深入解析 Kafka生产者:关键特性与最佳实践的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!