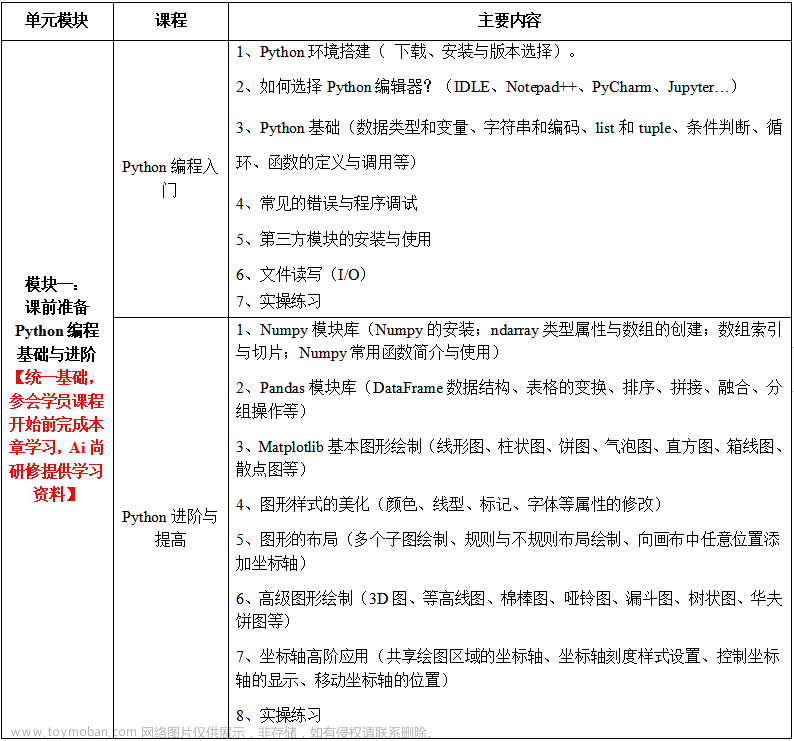
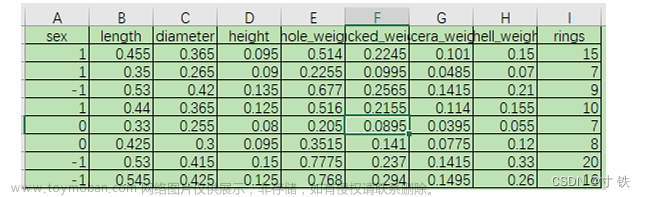
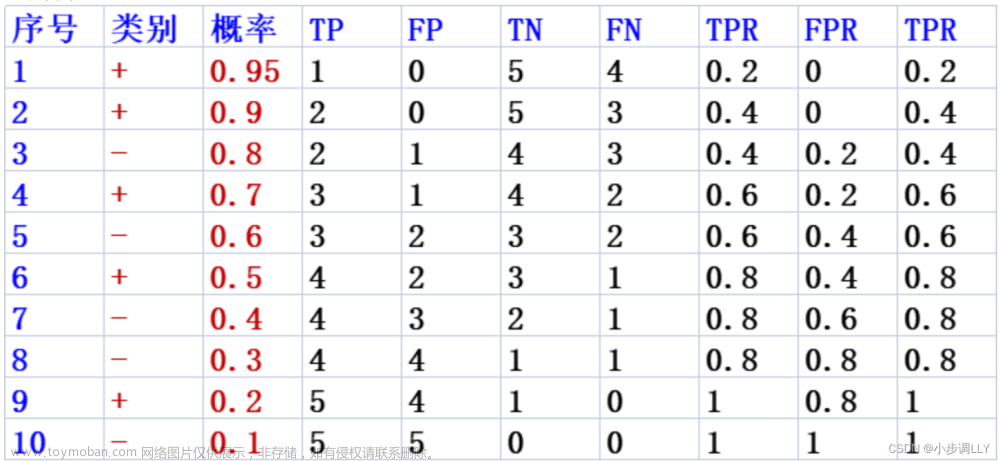
在数据挖掘的实践中,各种机器学习算法都扮演着重要的角色,它们能够从数据中学习规律和模式,并用于预测、分类、聚类等任务。以下是几种常见的机器学习算法以及它们在数据挖掘任务中的应用场景和优缺点。
1. 决策树(Decision Trees):
- 应用场景:决策树广泛应用于分类和回归问题,尤其适用于特征离散、数据具有可解释性的场景,如医学诊断、客户分群等。
- 优点:易于理解和解释,能够处理非线性关系和大规模数据集。
- 缺点:容易过拟合,对数据中的噪声和异常值敏感。
示例:在医学诊断中,决策树可以根据患者的症状和检查结果,快速准确地诊断疾病类型,帮助医生制定治疗方案。
2. 逻辑回归(Logistic Regression):
- 应用场景:逻辑回归常用于二分类问题,如信用评分、广告点击预测等场景。
- 优点:计算简单,易于实现和解释,能够输出类别概率。
- 缺点:对特征之间的相关性敏感,不能很好地处理非线性关系。
示例:在广告点击预测中,逻辑回归可以根据用户的个人信息、浏览历史等特征,预测用户是否会点击某个广告,从而为广告投放提供参考。
3. 支持向量机(Support Vector Machines,SVM):
- 应用场景:支持向量机适用于分类和回归问题,尤其在高维空间和非线性问题中表现优异,如图像分类、文本分类等。
- 优点:能够处理高维数据,具有较好的泛化能力,对于小样本数据效果较好。
- 缺点:计算复杂度较高,对参数选择和核函数选择敏感。
示例:在图像分类中,支持向量机可以根据图像的特征向量,将不同类别的图像分割开来,实现自动化的图像分类任务。文章来源:https://www.toymoban.com/news/detail-840995.html
这些示例说明了机器学习算法在实际数据挖掘项目中的应用。通过选择合适的算法,并针对具体问题进行调优和优化,可以充分发挥机器学习算法的效能,从而实现更精准、高效的数据挖掘和预测。文章来源地址https://www.toymoban.com/news/detail-840995.html
到了这里,关于机器学习算法在数据挖掘中的应用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!