什么是机器学习编译器/AI编译?
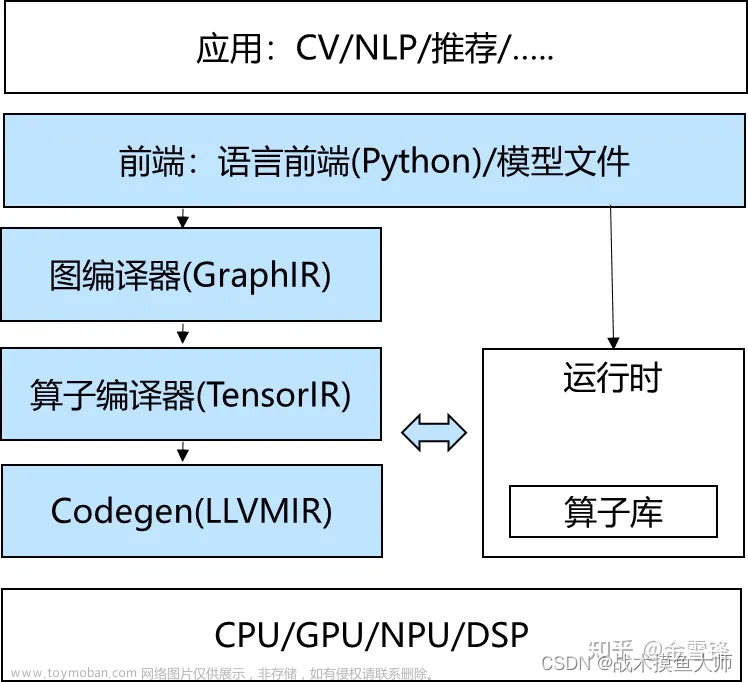
图片来自知乎大佬的文章
机器学习编译是指:将模型从训练形式转变为部署模式
- 训练模式:使用训练框架定义的模型
- 部署模式:部署所需要的模式,包括模型每个步骤的实现代码,管理资源的控制器,与应用程序开发环境的接口。
这个行为和传统的编译很像,所以称为机器学习编译,但是这里的编译和传统编译不完全一样,这里的输入是网络模型,输出可能是网络模型,也可能是生成的对于推理库函数的调用代码。
机器学习的三个目标:
- 集成与最小化依赖:将必要的元素组合成一个程序,尽量减小应用大小,并且减小对外部环境依赖,使得模型可以部署到更多环境。
- 利用硬件加速:
- 通用优化
为什么学AI编译

AI发展越来越快,各种模型不断更新,像以前那种手写plugin去实现算子的时代估计很快就会过去,这就像以往人们手工提取数据特征一样,过去的特征工程,在大模型时代也逐渐落寞,而prompt变得更加重要。我们现在处在AI时代的黎明,目前AI还没有和各行各业相结合,有效推动社会生产力的发展,我们还可以容忍低效部署,等到将来,AI编译,端到端部署一定会取代人手工写算子,所以学AI编译非常有必要。
AI编译的要素
- 数据类型/张量:输入,输出,中间变量的存储
- 算子/张量函数:网络模型中的计算称为张量函数,张量函数不一定非要和模型中的算子定义完全一致,可以进行融合或者优化。

AI编译要做的事情也围绕这两个要素展开,优化张量函数,把张量函数的一种实现替换为另一种实现【张量函数不一定非要对应模型中的一个算子,多个算子也可以一起实现,总之,模型是一个计算图,在不影响结果的情况下,内部实现可以与模型定义不完全一致。】
模型是计算的抽象,我们使用抽象 (Abstraction)来表示我们用来表示相同张量函数的方式。不同的抽象可能会指定一些细节,而忽略其他实现(Implementations)细节,对于一个模型,我们可以抽象为左边这种,将relu和线性层分隔开,也可以定义成中间这样,将两个结合到一起,这些都是抽象,与实现无关,只要能确保实现和抽象的结果一致即可,抽象是指定做什么,实现是具体怎么做,二者没有具体的界限,因为怎么做也可以理解为一种抽象,然后再向下细分怎么做,就比如循环本身是一个实现,也可以是一种抽象,底层用并行实现。
MLC 实际上是在相同或不同抽象下转换和组装张量函数的过程。我们将研究张量函数的不同抽象类型,以及它们如何协同工作以解决机器学习部署中的挑战。
TensorIR抽象
安装TVM:
python3 -m pip install mlc-ai-nightly -f https://mlc.ai/wheels
上面提的抽象啦,实现啦,都是为了这个做铺垫,IR,中间层表示。学过编译原理的应该非常熟悉,对的,刚才讲的就是这个意思,把网络模型翻译成一种统一的程序抽象:TensorIR,然后具体实现由backend来完成,刚才提到的实现也是一种抽象也是在为下面做铺垫,因为IR也可以分为high IR,middle IR,hardware IR,依次向下,对于下一层的IR来说,上一层就是抽象,这种IR分层的好处是可以把专用优化和通用优化分离开,根据硬件平台进行最大程度实现模型优化。
关于抽象于实现的关系,以及抽象之间的转化,实战代码:文章来源:https://www.toymoban.com/news/detail-841088.html
import numpy as np
import tvm
from tvm.ir.module import IRModule
from tvm.script import tir as T
dtype = "float32"
a_np = np.random.rand(128, 128).astype(dtype)
b_np = np.random.rand(128, 128).astype(dtype)
# a @ b is equivalent to np.matmul(a, b)
c_mm_relu = np.maximum(a_np @ b_np, 0)
# Numpy底层调用OpenBLAS等底层库以及自己的一些C语言实现来执行计算
# 等效实现
def lnumpy_m_relu(A:np.ndarray,B:np.ndarray,C:np.ndarray):
Y = np.empty(A.shape,dtype='float32')
for i in range(128):
for j in range(128):
for k in range(128):
if k == 0:
Y[i,j] = 0
Y[i,j] += A[i,k] * B[k,j]
C[i,j] = max(Y[i,j],0)
c_np = np.empty((128, 128), dtype=dtype)
lnumpy_m_relu(a_np, b_np, c_np)
np.testing.assert_allclose(c_np, c_mm_relu, rtol=1e-5)
# 使用TVM的TensorIR来实现
# TVM的TensorIR是一种用于表示计算的中间表示,它是一种低级的表示,用于表示计算的数据流和计算的依赖关系
# 它是由TVMScript语言来实现的,这是一种嵌入在Python AST中的DSL,用于表示TVM的中间表示
@tvm.script.ir_module # 修饰器,用于声明MyModule是一个TVM的IRModule,IRModule是在机器学习编译中保存张量函数集合的容器。
class MyModule:
@T.prim_func # 修饰器,用于声明一个TVM的primitive function
def mm_relu(
A:T.Buffer((128, 128), dtype="float32"),
B:T.Buffer((128, 128), dtype="float32"),
C:T.Buffer((128, 128), dtype="float32")):
T.func_attr({"global_symbol": "mm_relu","tir.noalias": True})
# T.func_attr是一个语法糖,用来声明函数的属性,global_symbol对应函数名,tir.noalias表示所有的缓冲存储器都是不重叠的。
Y = T.alloc_buffer((128, 128), "float32")
for i,j,k in T.grid(128,128,128): # T.grid()返回的是一个生成器,可以用for循环来遍历,是TensorIR的一个语法糖
with T.block("Y"): # T.block()是一个语法糖,用来定义一个block,这个block可以包含多个axis以及围绕这些axis的计算
vi = T.axis.spatial(128, i) # 定义了一个空间轴,表示i的范围是[0,128),声明了轴的属性spatial,表示这是一个空间轴
vj = T.axis.spatial(128, j)
vk = T.axis.reduce(128, k) # 还有一种属性是reduce,表示这是一个规约轴
with T.init():
Y[vi, vj] = T.float32(0)
Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]
for i,j in T.grid(128,128):
with T.block("C"):
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j)
C[vi, vj] = T.max(Y[vi, vj], T.float32(0))
# 块设计有助于我们进行机器学习编译分析,我们总是在空间轴上做并行化,但是在规约轴上做并行化需要考虑数据依赖关系
# 每个块轴直接映射到外部循环迭代器的情况下,我们可以使用 T.axis.remap 在一行中声明所有块轴。
@tvm.script.ir_module
class MyModuleWithAxisRemapSugar:
@T.prim_func
def mm_relu(
A:T.Buffer((128, 128), dtype="float32"),
B:T.Buffer((128, 128), dtype="float32"),
C:T.Buffer((128, 128), dtype="float32")):
T.func_attr({"global_symbol": "mm_relu","tir.noalias": True})
Y = T.alloc_buffer((128, 128), "float32")
for i,j,k in T.grid(128,128,128):
with T.block("Y"):
vi, vj, vk = T.axis.remap("SSR", [i, j, k])
with T.init():
Y[vi, vj] = T.float32(0)
Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]
for i,j in T.grid(128,128):
with T.block("C"):
vi, vj = T.axis.remap("SS", [i, j])
C[vi, vj] = T.max(Y[vi, vj], T.float32(0))
# IRModule可以包含多个张量函数
@tvm.script.ir_module
class MyModuleWithTwoFunctions:
@T.prim_func
def mm(A:T.Buffer((128, 128), dtype="float32"),
B:T.Buffer((128, 128), dtype="float32"),
Y:T.Buffer((128, 128), dtype="float32")):
T.func_attr({"global_symbol": "mm","tir.noalias": True})
for i,j,k in T.grid(128,128,128):
with T.block("Y"):
vi,vj,vk = T.axis.remap("SSR",[i,j,k])
with T.init():
Y[vi,vj] = T.float32(0)
Y[vi,vj] = Y[vi,vj] + A[vi,vk] * B[vk,vj]
@T.prim_func
def relu(A: T.Buffer((128, 128), "float32"),
B: T.Buffer((128, 128), "float32")):
T.func_attr({"global_symbol": "relu", "tir.noalias": True})
for i, j in T.grid(128, 128):
with T.block("B"):
vi, vj = T.axis.remap("SS", [i, j])
B[vi, vj] = T.max(A[vi, vj], T.float32(0))
# 张量函数的变换
# 张量函数的变换是指对张量函数的变换,包括对块轴的变换,对块的变换,对循环迭代器的变换等
def lnumpy_mm_relu_v2(A:np.ndarray,B:np.ndarray,C:np.ndarray):
Y = np.empty(A.shape,dtype='float32')
for i in range(128):
for j0 in range(32):
for k in range(128):
for j1 in range(4):
j = j0*4+j1
if k == 0:
Y[i,j] = 0
Y[i,j] += A[i,k] * B[k,j]
for i in range(128):
for j in range(128):
C[i,j] = max(Y[i,j],0)
c_np_v2 = np.empty((128, 128), dtype=dtype)
lnumpy_mm_relu_v2(a_np, b_np, c_np_v2)
np.testing.assert_allclose(c_np_v2, c_mm_relu, rtol=1e-5)
# 进行张量函数变换
sch = tvm.tir.Schedule(MyModule)
# 创建一个辅助的Schedule对象,用于对张量函数进行变换
block_Y = sch.get_block("Y", func_name="mm_relu")
i,j,k = sch.get_loops(block_Y)
# 获得块和循环的引用
j0,j1 = sch.split(j, factors=[None,4])
# 将j轴分裂为j0和j1两个轴,j0的范围是[0,32),j1的范围是[0,4)
sch.reorder(i,j0,k,j1)
# 重新排列块轴的顺序
block_C = sch.get_block("C", func_name="mm_relu")
sch.reverse_compute_at(block_C, j0)
# 将C块的计算位置移动到j0轴
sch.decompose_reduction(block_Y, k)
# 将Y的元素初始化和计算分解开
#最后变换后的实现等价于lnumpy_mm_relu_v3
def lnumpy_mm_relu_v3(A: np.ndarray, B: np.ndarray, C: np.ndarray):
Y = np.empty((128, 128), dtype="float32")
for i in range(128):
for j0 in range(32):
# Y_init
for j1 in range(4):
j = j0 * 4 + j1
Y[i, j] = 0
# Y_update
for k in range(128):
for j1 in range(4):
j = j0 * 4 + j1
Y[i, j] = Y[i, j] + A[i, k] * B[k, j]
# C
for j1 in range(4):
j = j0 * 4 + j1
C[i, j] = max(Y[i, j], 0)
c_np = np.empty((128, 128), dtype=dtype)
lnumpy_mm_relu_v3(a_np, b_np, c_np)
np.testing.assert_allclose(c_mm_relu, c_np, rtol=1e-5)
本文是 机器编译课程的学习笔记。文章来源地址https://www.toymoban.com/news/detail-841088.html
到了这里,关于深度学习模型部署-番外-TVM机器学习编译的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!