端到端视觉里程计与传统视觉里程计的区别
相较于传统的视觉里程计,端到端的方法可以认为是把特征提取、匹配、位姿估计等模块用深度学习模型进行了替代。不同于那种用深度学习模型取代里程计框架一部分的算法,端到端的视觉里程计是直接将整个任务替换为深度学习,输入依然是图像流,结果也依然是位姿,区别在于中间过程发生了完全性的变化。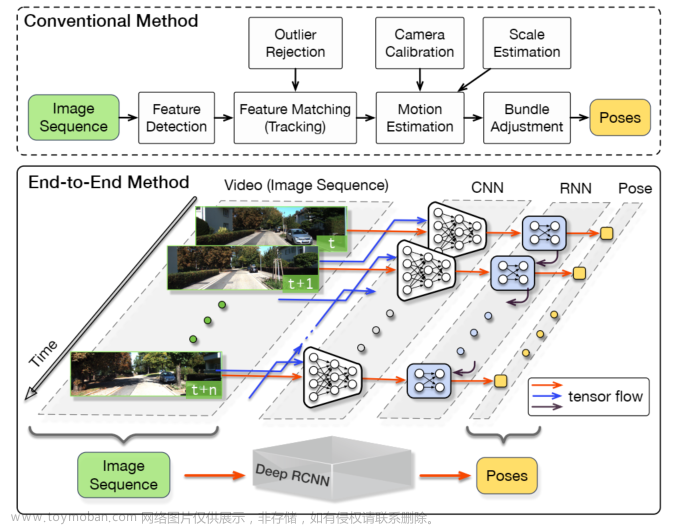
模型结构设计

不同于一般视觉里程计或者SLAM框架的结构,DeepVO完全遵循了深度学习框架的套路。输入是两张3通道RGB图像的叠加,模型可以分为两部分:CNN进行特征提取,RNN进行推理。
CNN 特征提取
在特征提取的部分,由于视觉里程计任务本身依赖于几何特征,而非外形特征或者说图像的上下文特征,所以DeepVO采用了传统的CNN模型进行特征提取,以保证提取出来的特征更偏向于几何特征。这一点在一些SLAM框架里面也有体现,就是用深度学习模型来代替传统手工设计的特征提取方法,这种方法本身都是采用一些指标提取特征,但区别在于人工设计的特征基本是通过像素的差异来检测,本身是从人可理解的角度出发的,换句话说,特征的提取过程完全是有迹可循的,使用深度学习提取特征也无外乎采用一些指标做筛选,但是这个过程是模型进行的,提取的方法以及提取的结果对于人来说可能较难理解。
图中CNN的部分一共设计了九层,每一层的结构以及设计如下:
除了最后一层,每一层输出之后都会跟一个线性激活层(ReLU),随着层数的增加,感受野(卷积核大小)也会逐渐变小,以此来提取更加细节的特征。
RNN 推理
提取出的CNN特征被送入后续推理的RNN部分。首先,为什么推理过程要用RNN,这本质是因为里程计这个东西,不是一个相互独立的任务,一个图像序列,其中的每个图像都是相互关联的,拿视觉SLAM来说,前面帧建立的地图元素,在后续的帧的位姿估计中也是照样要用的,这也就要求推理的模型能够与前面的过程产生一定的时序上的联系。

因此在DeepVO的后半部分采用了RNN来引入时序上的约束。之前完全没了解过RNN,这里参考b站大佬的视频补了一下。一个传统的CNN模型,隐含层的每个神经元的输入,完全是来自于前面的神经元,究其根本依然是来自于输入层的信息,所以这种结构导致了两次输入之间完全是相互独立互不干扰的。

而在一些特殊的任务中,不仅仅输入起到作用,上下文的环境也会对推理结果产生影响,这种情况下就需要一些结构,将上次推理的内容向下传递,用于这一次的推理中,补充了这类结构的CNN就成了RNN。图中橙色的线就是用于在时间序列之间进行传递的连接。引入这一结构之后,模型在推理过程就会有上一次推理的隐含层信息加入,公式变为:
其中Ws为橙色边的权重,St-1为上一个时刻隐含层的值,所以这一个结构也变相要求需要额外的数据结构来存储上一次推理的隐含层,同时模型的参数量也会有很大的增加。在RNN中,这种结构能够让短期的记忆传递到下一层,但是长久来看,这种传输并不是稳定的,一些很久之前的内容会逐渐消失。
针对这一点,RNN又延伸出LSTM,也就是DeepVO里面使用的用于传递信息的结构。相较于RNN,LSTM增加了“日记本”这一概念,可以把这个结构理解为一个额外的数据库,用来存储过去的重要的事情。每次进行推理时,都会对日记本进行删除和增加,以此来忘记无关紧要的事情,同时补充新的重要的事情。
在增加了LSTM之后,每个神经元的输入依然是当前时刻的输入以及上一时刻的隐含层,但是区别在于,日记本在这一时刻结束时,对上一时刻的隐含层做一个叠加运算,以此来将长期记忆与短期记忆相结合,从而让模型能够想起来很久之前的事情。这也就是LSTM的巧妙之处。
在DeepVO中,为了学习高级表示模型选择了堆叠两个LSTM模型,前一个的输出是后一个的输入,其中每个LSTM中包含有1000个隐含状态,也就是有1000个隐藏层的神经元。
损失函数与优化
作为一个深度学习模型,本身必然离不开损失函数用来梯度下降计算参数值。在构建损失函数的时候,DeepVO一开始选择了概率的表示方法:

利用SLAM中的概念,也可以将这个最大化问题转换为最小化MSE的问题,转换后为:
在这个公式中,P是位置信息;φ是欧拉角表示的旋转信息,作者提到用四元数会让精度下降;κ是一个尺度,用于在优化函数中平衡旋转和位置信息的重要性;N为样本数量。所以按照这个优化函数,DeepVO实际上就是在尝试计算一组包括了CNN和RNN的参数,让模型推测出来的六自由度位姿信息与真值尽可能接近。文章来源:https://www.toymoban.com/news/detail-841111.html
参考链接
DeepVO论文翻译
RNN讲解1
RNN讲解2
RNN讲解3文章来源地址https://www.toymoban.com/news/detail-841111.html
到了这里,关于【论文阅读】DeepVO: Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[文章阅读] EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object ...](https://imgs.yssmx.com/Uploads/2024/02/435594-1.png)






