转自知乎:叫我Alonzo就好了
前言
背景——Sora和Stable Diffusion 3
近期,OpenAI和Stability两大AI巨头公司在同期分别发布了它们的新作品——Sora和Stable Diffusion 3。神奇的是,这两家公司的研究团队不约而同地采用了Diffusion Transformer这一架构。Diffusion Transformer这个词倒是并不陌生,回想在DiT[3]刚挂出arXiv的时候,当时我只是下意识地认为这篇工作不过是为扩散模型家族提供了一个额外的选项,并没有特别在意。但今天从Sora和Stable Diffusion 3这两个热点出发回顾Diffusion Transformer,AI巨头的动作为我们又重新提供了一些启发。
一些题外话——我的一些早期胡思乱想
在Stable Diffusion进入公众视野之前,我对扩散模型的认识还存在很严重的刻板印象,认为扩散模型不过就是一个充满“学术界风格”的模型。尤为记得当时自己为了在一个测试集上试一试DDPM的效果,第一时间读完DDPM的论文,下模型、debug、准备测试集,一气呵成,结果发现采样一张图还需要好几分钟,一度弄得焦头烂额。
在Stable Diffusion[4]被CVPR接收之后,我才开始重新改进自己对扩散模型的看法,但当时更加看好的是以Taming Transformer、MaskGit、Muse为代表的、基于Transformer的技术,主要是因为Transformer自2017年以来给计算机视觉社区带来的影响已经渗透各个子领域,不经意间已经确定了Transformer在心目中的神坛位置。后来,ChatGPT的出现更进一步固定了Transformer的地位,我甚至开始天马行空:Transformer结构已经在自然语言处理领域取得巨大成功,基于Transformer的多模态大一统时代是不是很快就要来了?从今天来看这个提问确实是天马行空了,但也足以证明Transformer确有可取之处。
前置知识
那么,所谓的Diffusion Transformer究竟是什么呢?为便于理解,在介绍它之前我们很有必要了解它的一些前置知识。Diffusion Transformer顾名思义,可以简单拆分为:Diffusion Transformer = Diffusion + Transformer。于是也就对应了我们下面要介绍的主流扩散模型(隐空间扩散模型,latent diffusion models)和Transformer模型。
Latent Diffusion Models
关于扩散模型(diffusion models) 是什么,某乎上的其他大佬已经有过很详尽的解释了,大家可以自行搜索。简单说就是模型通过“加入噪声”来污染图片的像素,从而学习“去除噪声”这一过程,在生成图片时,模型通过将完全体的高斯噪声逐步去噪,一步一步地恢复,直至模型输出图片中的每一个像素都不再带有噪声,也就是我们期望得到的干净图像。
隐扩散模型(latent diffusion models) 是什么呢?顾名思义,即扩散模型去除噪声的对象从“像素”变成了“隐空间特征”。隐扩散模型包括两个部分,分别如下:
- 压缩模型: 压缩模型是一个编码器-解码器结构,具体来说应该叫做Vector Quantized Variational Auto Encoder(向量量化-变分自编码器,VQ-VAE,现在常用的VQGAN为Taming Transformer[5]中的改进版本)。简单地说,压缩模型可以将图片变成一个特征(这个特征在隐特征空间中,因此叫做latent features,译为“潜在特征”),又可以将特征恢复成原图像。但是要注意,这个从原图像到“恢复后的原图像”是一个有精度损失的过程,现在的技术已经能做到肉眼难以分辨,但对于计算机来说,这个有损过程仍不可忽略。这样一来,我们就不再需要用大量的像素来组成一个图片,而是只需要得到这样一个特征,就能够知道其对应的图片是什么。其好处是能有效节省扩散模型的学习成本,举一个512×512分辨率的图像为例:我们通过压缩模型能够将其变成一个分辨率为32×32的特征,同时让扩散模型学习去生成前面两者,后者需要学习的内容数目相比于前者下降了64倍,效果是非常显著的。
- 扩散模型: 隐扩散模型中,扩散模型的不同之处仅仅是其作用对象:从图片中的像素变成了上文中的特征,其余特性与传统的扩散模型都是一样的。
将前面两者组合起来,就得到了我们的隐扩散模型,拿Stable Diffusion的模型架构来呈现最为经典:
Transformer
Transformer最早用于机器翻译任务,也就是完成一句相同长短的话的翻译过程,处理的对象是“词”(token)。说到Transformer,我们最容易联想得到的是它自注意力机制(self-attention),关于这一机制也同样有很多优秀的帖子阐述得非常清楚。而我们今天更多要关注Transformer模型本身的另一特性——自回归(Autoregressive,AR)。
Transformer跟LSTM一样,是一个经典的自回归模型。那么自回归是什么呢? 我想结合跟ChatGPT交互的方式会很好理解,我们在网页端跟ChatGPT对话的时候,会发现其实ChatGPT的回复是一个一个词蹦出来的,换句话说,这个过程我们可以叫做 “预测下一个词”(next word prediction)(这里借用了GPT预训练方式的说法,便于理解,二者有本质不同)。
这里需要注意的是,“词”有可能是英文中的每个单词,也可能是用于表征图像的某种形式,是一种更为广义的定义。那么对于图像中的词,需要结合前文中的压缩模型来解释。前面我们说到,压缩模型的过程是有精度损失的,其具体损失在于,压缩模型将连续的图片处理成特征后,需要在特征空间中将图片进行离散化处理,即原本是小数的像素值会被处理成整数,这样一来,精确的值就会变得不精确,便导致了精度上的损失。计算机在处理文本的时候,实际看到的是一堆的整数,为了方便人类的理解,我们人为设置了一个词表(vocabulary) 让这些整数与自然语言一一对应,这一过程被叫做tokenize;类似地,对于离散化过后的图像特征,我们也能得到这样的一个词表,我们叫做码本(codebook),而经过码本对应后的词会作为Transformer的输入,并进行进一步处理。
那么如果要生成一张图像,Transformer会怎么做呢? 结合前面压缩模型的过程,我们拿Taming Transformer举例,它需要首先预测一个词,然后将这个词作为下一次预测的“上文信息”,Transformer会进一步根据这个词预测下一个词,再将上一个词、这一个词再送入Transformer本身,以此类推。最后,直至模型预测的一定数量词,使这些词能够组合成一个图片对应的特征,再由压缩模型恢复成我们肉眼能够识别的图片(像素)。
小结
尽管latent diffusion models和Transformer都为人工智能的发展添上了浓墨重彩的一笔,这些技术也有着它们固有的缺陷。对于扩散模型来说,自2020年DDPM诞生以来,连续3年的工作仍然延续最初的经典U-Net架构,在网络结构设计上仍依赖早期的研究经验,有着很大的提升空间;而Transformer一直被诟病的则是其“错误累积”问题,简单来说,错误扩散来源于Transformer“预测下一个词”的生成模式,如果说前面生成的词出现了错误,那么模型在生成后续的词时会“将错就错”,进而导致误差的累积,扩散模型由于同时对所有的像素去除噪声(这种范式我们称为非自回归,non-autoregressive),从生成范式上规避了这一问题。如何同时解决好二者的存在的缺陷,成为了一个很好的研究课题。
现在我们同时了解了扩散模型和Transformer是什么,很自然的一个想法就是:如果我们做一个“A+B”会怎么样?如果这个”A+B“能够同时解决上述问题,那自然更妙。 于是,就有了我们下面要讲的Diffusion Transformer。
Diffusion Transformer是什么?
Diffusion Transformer来源于《Scalable Diffusion Models with Transformers》这篇文章,这篇工作做的就是通过”A+B“的思路,将隐扩散模型和Transformer结合起来。我们通过研究动机、方法设计以及个人的一些思考来看一看Diffusion Transformer被AI巨头所青睐的原因。
研究动机
工作的研究动机其实跟前文中描述的扩散模型的缺陷一致——扩散模型基于早期工作的经验,在网络结构设计上仍有很大的提升空间。 而这篇工作在隐空间扩散模型范式的启发下,成功将扩散模型中经典的U-Net结构替换成了Transformer,在进一步提升网络架构复杂度的前提下,能够显著提升生成图片的质量,并在ImageNet数据集的生成任务上取得了2.27 FID分数的好成绩 (2.27的FID分数对于标准数据集ImageNet来说是一个很惊人的成绩)。
方法设计

总体来说,Diffusion Transformer(简称DiT)既有着扩散模型对图片加噪、去噪的特殊机制,又同时有Transformer强大的自注意力机制,以及前文中提到Transformer“预测下一个词”的特点。给定输入图片时,DiT首先通过扩散模型标准的加噪过程对图像压缩后的特征进行污染,将带噪特征、条件特征、ground truth对应的特征拼接在一起输入Transformer后输出结果,完成一次DiT的前传过程。
在训练过程中,DiT通过①和②计算标准的扩散损失
L
s
i
m
p
l
e
=
∥
ϵ
θ
(
x
t
)
−
x
t
∥
2
2
\mathcal{L}_{simple} = \Vert \epsilon_\theta(x_t) - x_t \Vert^2_2
Lsimple=∥ϵθ(xt)−xt∥22,同时,DiT还额外约束了①和③之间的KL散度,确保预测的
Σ
\Sigma
Σ与ground truth分布保持一致。
具体针对每个DiT模块的细节,我们可以对照其论文中的模型架构图(顺序由右到左)进行介绍:
- Patchify:从字面意思上可以简单译为“块化”。这里的patchify是针对于Transformer的输入进行处理的,操作其实也很简单。给定一个分辨率为
I
×
I
×
C
I \times I \times C
I×I×C的特征,我们把它裁剪成
I
/
p
I/p
I/p个小块,其中每个小块的分辨率是
p
×
p
×
C
p \times p \times C
p×p×C,再将这些小块按照一定顺序(通常为左上到右下)排成一排,形成一个长度为
T
=
(
I
/
p
)
2
T=(I/p)^2
T=(I/p)2的序列输入Transformer,具体流程我们可以参照论文中的流程图:

-
DiT模块: 在完成“块化”的操作之后,下一步要做的就是输入DiT进行相应的运算。DiT由DiT 模块的基本单元构成,其中,DiT模块中的大多数元素类似于标准的Transformer模块,包括多头自注意力机制(Multi-Head Self-Attention)、Layer Normalization、Feed Forward Layer等等。其中,为了融合外部的条件控制,DiT有三种变种形式,分别与In-Context Conditioning、Cross-Attention、adaLN-Zero相组合,它们都用于融合外部的标签条件,对应Diffusion Transformer模型架构图中由右到左的顺序:
- In-Context Conditioning: 从字面意思上来看,In-Context Conditioning可以翻译为”上下文条件化“。其实就是将条件拼接在输入词的后面。前面我们说到,Transformer的输出过程其实是在做“预测下一个词”,而in-context conditioning其实是给这一过程加上了一个前缀,在“预测下一个词”的过程中,模型会持续收到这个前缀的作用。具体来说,在DiT这篇工作的设定中,这个条件对应ImageNet中图片的类别,在模型生成图片“词”的时候,模型就会在知道生成图片的类别的前提之下完成输出过程。从技术层面上来看,这个设计跟ViT中的cls token大同小异。
- Cross-Attention: 跨注意力机制其实很简单,类似于经典latent diffusion models中U-Net的跨注意力机制,将条件对应的特征作为注意力机制的K和V,以图片特征作为Q进行运算,从而达到将条件融入图片生成过程中的效果。
-
adaLN-Zero: 这个模块是这篇工作中的另一创新点,是针对Transformer原本layer normalization在图像生成任务上的一个创新。具体做法抛弃了layer norm原来直接学习增益(scale)和偏置(shift)的做法,而是通过自适应地学习加权系数(图中的
α
1
,
α
2
,
β
1
,
β
2
\alpha_1, \alpha_2, \beta_1, \beta_2
α1,α2,β1,β2),加权系数将输入条件的特征处理后,再加到每层layer norm的增益和偏置中去,以此完成条件的融合。
- 这里adaLN-Zero的设计其实感觉跟SPADE[6]的思路类似。SPADE的提出是为了融合分割图的条件输入而提出了,其做法是将分割图处理成可学习的增益和偏置,再将增益和偏置加权到图像特征上,完成条件的融合。可以看到,SPADE和adaLN-Zero的异曲同工之妙,说明增益和偏置是融入条件信号是一个有效的方式。
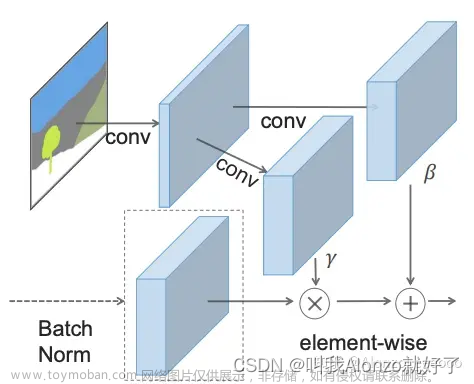
- 这里adaLN-Zero的设计其实感觉跟SPADE[6]的思路类似。SPADE的提出是为了融合分割图的条件输入而提出了,其做法是将分割图处理成可学习的增益和偏置,再将增益和偏置加权到图像特征上,完成条件的融合。可以看到,SPADE和adaLN-Zero的异曲同工之妙,说明增益和偏置是融入条件信号是一个有效的方式。
为什么是Diffusion Transformer?
Diffusion Transformer的研究动机其实大道至简,将隐扩散模型所达到相对不错的性能效果,与Transformer强大的模型架构相结合,希望能够让扩散模型更上一层楼。正值OpenAI和StabilityAI都不约而同地选择了Diffusion Transformer,不由得引发了我对它的一些思考,同期模型其实也不乏其他可用的选项,例如Mamba,那么究竟是什么特点能让Diffusion Transformer变成AI巨头们独一无二的选项呢?
-
Diffusion Transformer有助于生成更清晰的文字? 在StabilityAI的技术报告中,Stable Diffusion 3采用的Diffusion Transformer能够生成高质量包含文字的图片。生成文字本身就对扩散模型就有着极高的难度,对于扩散模型生成图片的质量就有着较高要求,在此之上,生成的文字还要与提示词中的其他场景信息完美融合,例如:“在黑板上”、“在路牌上”等等,这就要求模型对于一个场景中不同区域的信息能够有效联系或区别。而Diffusion Transformer中的自注意力机制天然就能做好这点。值得留意的是,StabilityAI将Stable Diffusion 3的参数量规模从前两代版本的800M提升到了8B,整整提升了10倍的模型容量,Stable Diffusion 3能给我们带来怎么样惊艳的效果,值得我们好好期待一下。

-
视频块表征 + 自注意力机制 = 电影级视频? 在OpenAI的技术报告中提到,Sora首次采用“视频块”的技术对视频输入进行表征。视频在图像的基础上又增加了时间的维度,属于更高维的数据,OpenAI提出了类似VQVAE这样的压缩模型,将其用于视频数据的压缩,对于算力资源的节省将非常可观。 由技术报告中的示意图我们可以看到,Sora同样将视频块特征展成序列送入Diffusion Transformer中进行处理,这一操作是类似于DiT中的patchify操作的。值得注意的是,对于Sora而言,展开后的特征序列是包括时间维度的信息的,因此,Transformer架构中的自注意力机制很可能就帮上了大忙。个人猜测Diffusion Transformer对Sora带来的效应有两个方面,分析如下。
- 当Sora在生成单个视频帧时,Diffusion Transformer中的自注意力机制能够将视频帧中不同块的联系建立起来,并增幅单个视频帧的一致性和质量,这一点很有可能是帮助Sora生成电影级视频的一大原因。现有视频生成技术(例如Pika、Gen-2等)仍存在的一个很大问题,那就是单帧中仍存在不一致的问题,比较常见的有复杂场景中变形的人脸。而Sora很有可能正是因为将单帧中不同区域的联系建立好了,才首先确保了生成的每一个视频帧都是高质量的。其实从另一个角度也能证明这个推测:Sora同时还是一个优秀的高分辨率图像生成网络,这一点也在OpenAI的技术报告中有所体现。

- 当Sora在生成一个完整的视频流时,Diffusion Transformer中的自注意力机制能够将时间维度上的联系建立起来,并增强视频流的流畅程度。 另一个现有视频生成技术的局限性及难点就是如何生成丝滑的视频,具体来说就是怎么样将后面生成的视频帧与前面的有效拼接,从而让整体视频在视觉效果上连贯。前面我们说到,经过压缩模型处理过后的特征是带有时间维度的信息的,这个时候Diffusion Transformer中的自注意力机制能够将不同时间视频帧中的联系建立起来,进而生成电影级别的视频。
- 当Sora在生成单个视频帧时,Diffusion Transformer中的自注意力机制能够将视频帧中不同块的联系建立起来,并增幅单个视频帧的一致性和质量,这一点很有可能是帮助Sora生成电影级视频的一大原因。现有视频生成技术(例如Pika、Gen-2等)仍存在的一个很大问题,那就是单帧中仍存在不一致的问题,比较常见的有复杂场景中变形的人脸。而Sora很有可能正是因为将单帧中不同区域的联系建立好了,才首先确保了生成的每一个视频帧都是高质量的。其实从另一个角度也能证明这个推测:Sora同时还是一个优秀的高分辨率图像生成网络,这一点也在OpenAI的技术报告中有所体现。
Diffusion Transformer的应用
FiT
FiT是DiT的后续延续版本,出自于《FiT: Flexible Vision Transformer for Diffusion Model》。
解决了,但没完全解决。 尽管DiT解决了U-Net的问题,从Sora和Stable Diffusion 3成功应用的效果来看,Diffusion Transformer的设计无疑取得了巨大成功,但与此同时,DiT的架构也因Transformer的存在带来新的问题——那就是Transformer的分辨率固定问题。而FiT的诞生就是为了让DiT的架构能够应用于任意分辨率上,具体来说,FiT将DiT的原有的位置编码替换为了苏剑林老师的旋转位置编码(RoPE, Rotary Positional Embedding),并将自注意力机制变成了带掩码的自注意力机制(Masked Multi-Head Self-Attention),有趣的是这篇工作受启发于一些大语言模型的工作,将Feed Forward Layer中的MLP换成了SwiGLU。无论是在训练还是测试阶段,FiT都会将输入扩展至最大的长度,而在生成图片的时候仅取用与分辨率相关的词个数,以此实现Diffusion Transformer在任意分辨率下的图像生成。
UniDiffuser
UniDiffusers是结合扩散模型和Transformer的另一篇工作,出自于《One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale》。
写到这里,不知不觉又跟文章开头自己关于Transformer多模态统一的天马行空产生了呼应。第一次拜读朱军老师团队的Unidiffusers的时候非常惊艳,不仅仅是因为Transformer“真的”统一了模态,而且是跟扩散模型一起,回想起也是饶有趣味。
从上图我们可以看出,Unidiffuser不仅仅能实现文生图,还能完成同时生成文本和图片、图像描述、无条件图像/文本生成、图片/文字变式、图片/文字编辑、图片插值等多个任务,很大程度在生成的这一角度实现了多模态的统一。
具体来说,Unidiffuser能够对图片和文本两种不同模态的数据进行同时处理,整体仅需要微小的改动就能实现这一点。在训练过程中,对于整个Unidiffuser的输出,我们可以根据经典的diffusion loss进行改写;在测试过程中,Classifier-Free Guidance也同样适用于Unidiffuser的架构。在统一模态这一点上,Unidiffuser有几点很有意思的设计:
- 图像的表征: Unidiffuser对于图像的表征仍然沿用latent diffusion models中经典的VQGAN模型,除此之外,Unidiffuser会额外将CLIP从图像中提取到的特征与VQGAN压缩后的特征相拼接,以此提供额外的语义信息。
- 文本的表征: Unidiffuser对于文本的表征也仍然沿用了latent diffusion models中的CLIP text encoder。除此之外,Unidiffuser采用GPT-2的架构单独训练了一个额外的text decoder来重构输入的文本。
- 多模态的统一表征空间: Unidiffuser最有意思的地方在于建立了一个图片和文本共用的统一表征空间,具体来说,图片和文本的特征会被归一化到[-2,2]这个区间内,虽然说将2作为表征空间的取值边界这一点有些匪夷所思,但是能够建立起跨模态统一的表征空间已经有足够的价值,再次证明了Diffusion Transformer的强大之处。
-
基于Transformer的噪声预测网络: 这点非常直观,就是将原本的U-Net替换成Transformer架构,用于统一表征模态。Unidiffuser具体用到的Transformer架构是CVPR 2023的U-ViT[9]架构,也同样是朱军老师他们团队的工作。

总结
Sora和Stable Diffusion 3的到来,无论是在科研还是应用落地上,又给2024年的AIGC社区带来了全新的活力,而Diffusion Transformer作为一颗冉冉升起的新星,让所有人都倍感期待。不知道今年的Diffusion Transformer会不会像2022年的Stable Diffusion那样,再次重新颠覆AIGC的范式,这篇文章写到这里,我也越写越好奇了起来。
最后,欢迎大家关注我的个人GitHub账号,我总结了一些课题的顶会paper list,有需要的小伙伴可以参考,paper list会持续更新最新发布的顶会文章以及其他研究方向。你们的一键三连、GitHub Star就是对我最大的支持!
Video Generation Paper List
Text-to-Image Generation Paper List 文章来源:https://www.toymoban.com/news/detail-841296.html
文章来源:https://www.toymoban.com/news/detail-841296.html
Image Inpainting Paper List 文章来源地址https://www.toymoban.com/news/detail-841296.html
文章来源地址https://www.toymoban.com/news/detail-841296.html
到了这里,关于Diffusion Transformer Family:关于Sora和Stable Diffusion 3你需要知道的一切的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!