说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。


1.项目背景
贝叶斯优化(Bayesian Optimization)是一种全局优化方法,特别适用于那些目标函数昂贵、噪声大或者无法导数的黑盒优化场景。在机器学习模型参数调优中,贝叶斯优化能够有效地搜索超参数空间,以找到最优的模型配置。
将贝叶斯优化器应用到极限学习机分类模型(ELMClassifier)上时,概念可以这样理解:
1)超参数空间:极限学习机包含多个可调节的超参数,例如隐藏层节点数量、激活函数类型、正则化参数等。这些参数组合构成了一个高维搜索空间。
2)目标函数:在本场景下,目标函数通常是评估指标,如交叉验证后的准确率、F1分数或AUC值等,用于衡量经过不同超参数配置训练得到的ELMClassifier模型的性能。
3)贝叶斯优化过程:
(1)代理模型:首先构建一个概率模型(通常是一个高斯过程或树回归模型),该模型作为真实目标函数的代理,并根据已采样点更新其对整个搜索空间的预测分布。
(2)acquisition function:基于代理模型计算一个 acquistion function(如期望改善EI, 乌尔曼指数UCB等),它综合考虑了探索(exploration)和开发(exploitation)策略,指导下一个候选超参数的选择。
(3)迭代优化:循环进行采样、计算目标函数值、更新代理模型以及选择下一个要评估的超参数点,直到达到预设的迭代次数或满足其他停止条件为止。
4)最终结果:通过这样的过程,贝叶斯优化器能够智能地探索极限学习机的超参数空间,找到一组能使得ELMClassifier模型性能最优化的超参数设置,从而提高模型在新数据上的泛化能力。
本项目使用基于贝叶斯优化器(Bayes_opt)优化ELMClassifier分类算法来解决分类问题。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
| 编号 |
变量名称 |
描述 |
| 1 |
x1 |
|
| 2 |
x2 |
|
| 3 |
x3 |
|
| 4 |
x4 |
|
| 5 |
x5 |
|
| 6 |
x6 |
|
| 7 |
x7 |
|
| 8 |
x8 |
|
| 9 |
x9 |
|
| 10 |
x10 |
|
| 11 |
y |
数据详情如下(部分展示):

3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:

从上图可以看到,总共有11个字段。
关键代码:

3.2 缺失值统计
使用Pandas工具的info()方法统计每个特征缺失情况:

从上图可以看到,数据不存在缺失值,总数据量为2000条。
关键代码:

3.3 变量描述性统计分析
通过Pandas工具的describe()方法来来统计变量的平均值、标准差、最大值、最小值、分位数等信息:

关键代码如下:

4.探索性数据分析
4.1 y变量分类柱状图
用Pandas工具的value_counts().plot()方法进行统计绘图,图形化展示如下:

从上面图中可以看到,分类为0和1的样本,数量基本一致。
4.2 y变量类型为1 x1变量分布直方图
通过Matpltlib工具的hist()方法绘制直方图:

从上图可以看出,x1主要集中在-2到2之间。
4.3 相关性分析
通过Pandas工具的corr()方法和seaborn工具的heatmap()方法绘制相关性热力图:

从图中可以看到,正数为正相关,负数为负相关,绝对值越大相关性越强。
5.特征工程
5.1 建立特征数据和标签数据
y为标签数据,除 y之外的为特征数据。关键代码如下:

5.2 数据集拆分
数据集集拆分,分为训练集和测试集,80%训练集和20%测试集。关键代码如下:

6.构建贝叶斯优化器优化极限学习机分类模型
主要使用基于贝叶斯优化器优化极限学习机分类模型,用于目标分类。
6.1 构建调优模型
| 编号 |
模型名称 |
调优参数 |
| 1 |
极限学习机分类模型 |
n_hidden |
| 2 |
alpha |
|
| 3 |
rbf_width |
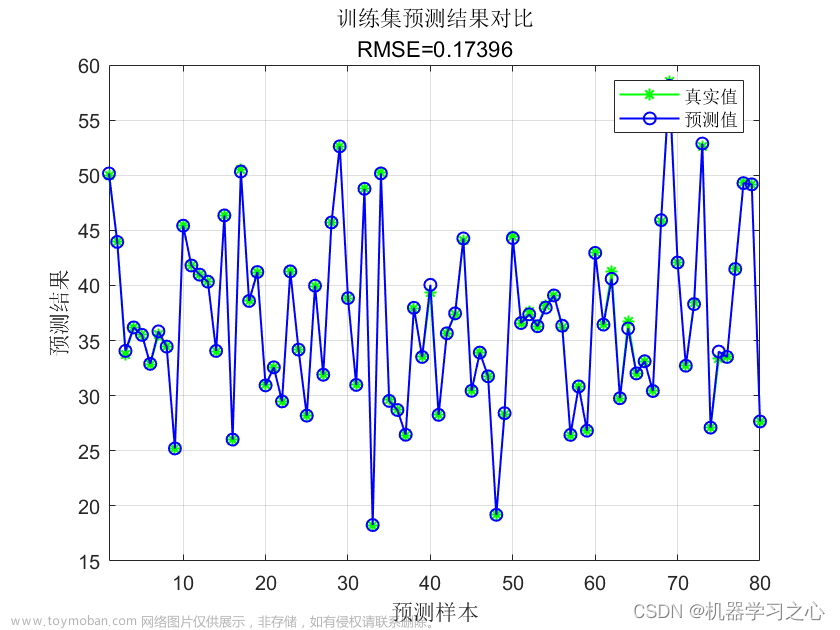
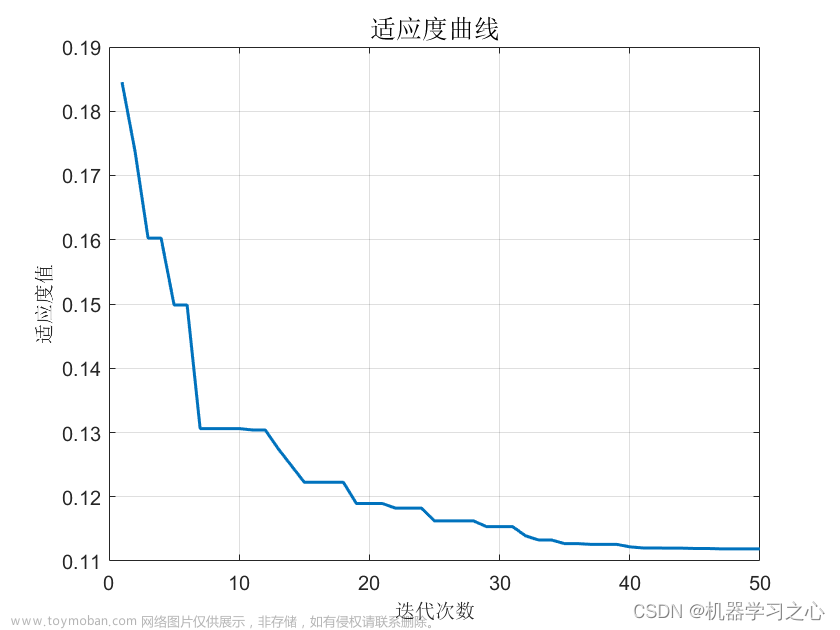
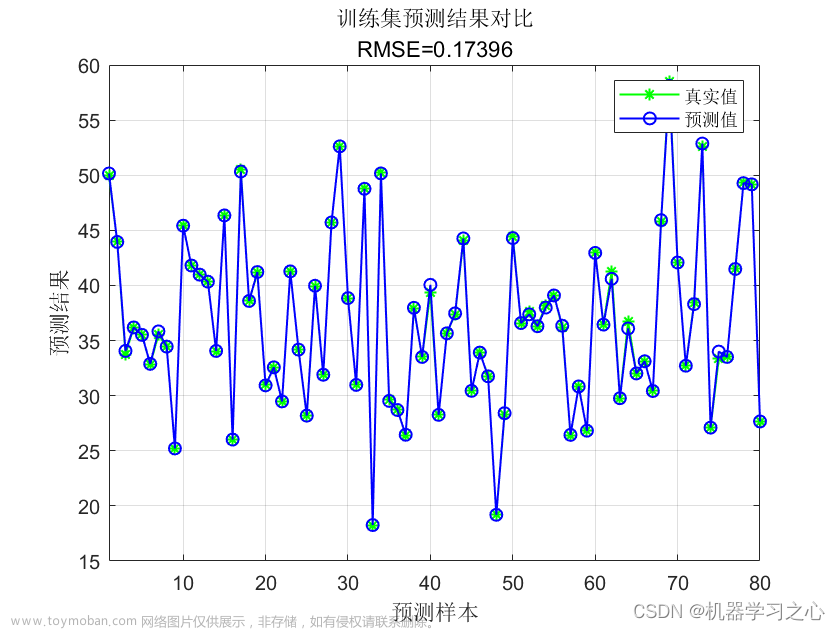
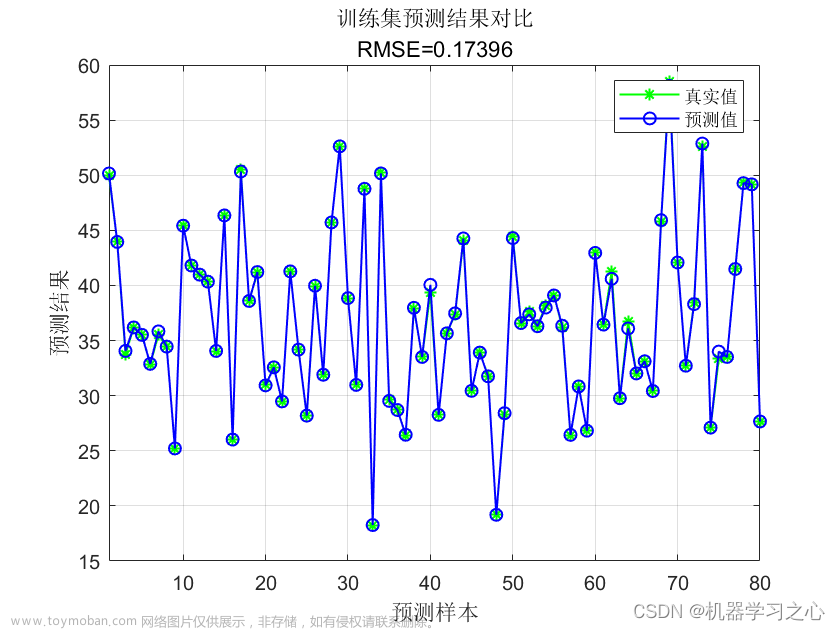
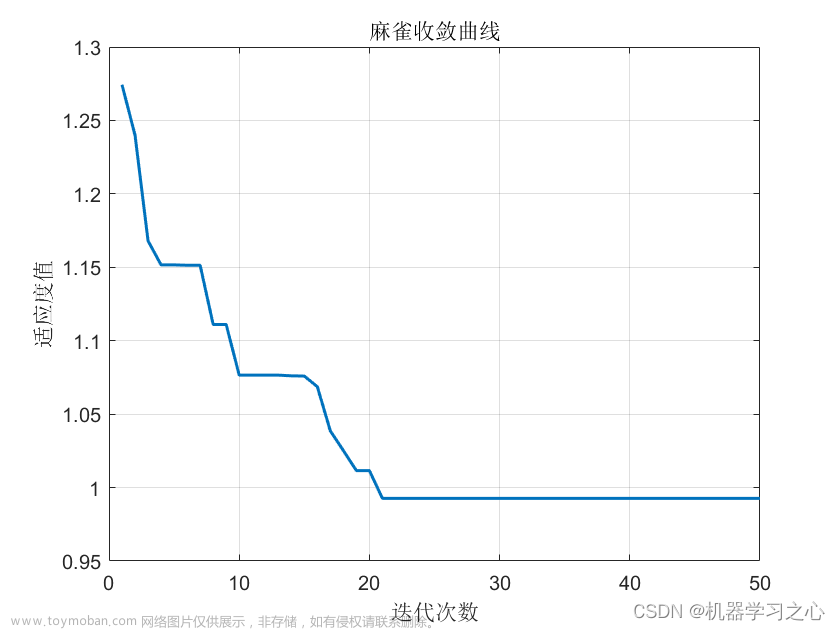
6.2 最优参数展示
寻优的过程信息:

最优参数结果展示:

6.3 最优参数构建模型
| 编号 |
模型名称 |
调优参数 |
| 1 |
极限学习机分类模型 |
'n_hidden': (10.0, 30.0) |
| 2 |
'alpha': (0.3, 0.6) |
|
| 3 |
'rbf_width': (0.5, 1.0) |
7.模型评估
7.1 评估指标及结果
评估指标主要包括准确率、查准率、召回率、F1分值等等。
| 模型名称 |
指标名称 |
指标值 |
| 测试集 | ||
| 极限学习机分类模型 |
准确率 |
0.9150 |
| 查准率 |
0.9886 |
|
| 召回率 |
0.8439 |
|
| F1分值 |
0.9105 |
|
从上表可以看出,F1分值为0.9105,说明此模型效果较好。
关键代码如下:

7.2 分类报告
极限学习机分类模型的分类报告:

从上图可以看到,分类类型为0的F1分值为0.92;分类类型为1的F1分值为0.91;整个模型的准确率为0.92。
7.3 混淆矩阵

从上图可以看出,实际为0预测不为0的 有4个样本;实际为1预测不为1的 有31个样本,整体预测准确率良好。 文章来源:https://www.toymoban.com/news/detail-841382.html
8.结论与展望
综上所述,本项目采用了基于贝叶斯优化器优化ELMClassifier分类模型,最终证明了我们提出的模型效果良好。文章来源地址https://www.toymoban.com/news/detail-841382.html
# 本次机器学习项目实战所需的资料,项目资源如下:
# 项目说明:
# 获取方式一:
# 项目实战合集导航:
https://docs.qq.com/sheet/DTVd0Y2NNQUlWcmd6?tab=BB08J2
# 获取方式二:
链接:https://pan.baidu.com/s/16NJZCZFDZ-4IrK32sh6XPA
提取码:ff9c到了这里,关于Python实现贝叶斯优化器(Bayes_opt)优化极限学习机分类模型(ELMClassifier算法)项目实战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!