🏷️个人主页:牵着猫散步的鼠鼠
🏷️系列专栏:Java全栈-专栏
🏷️个人学习笔记,若有缺误,欢迎评论区指正


目录
1.前言
2.canal部署安装
3.Spring Boot整合canal
3.1数据库与缓存一致性问题概述
3.2 整合canel
4.总结
1.前言
canal [kə'næl] ,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。其诞生的背景是早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。所以其核心功能如下:
- 数据实时备份
- 异构数据源(elasticsearch、Hbase)与数据库数据增量同步
- 业务缓存cache 刷新,保证缓存一致性
- 带业务逻辑的增量数据处理,如监听某个数据的变化做一定的逻辑处理
原理实现图如下所示

canal是借助于MySQL主从复制原理实现,所以我们接下来先来了解一下主从复制原理。

大概流程可以理解为如下:
- master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events,可以通过show binlog events进行查看);
- slave将master的binary log events拷贝到它的中继日志(relay log);
- slave重做中继日志中的事件,将改变反映它自己的数据。
canal的工作原理:

原理相对比较简单:
- canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
- mysql master收到dump请求,开始推送binary log给slave(也就是canal)
- canal解析binary log对象(原始为byte流)
canal组件架构实现
我们可以大概看看canal是怎么实现,其内部的组件抽取、封装及其对应的功能实现,以便我们后续在使用上更加得心应手。

说明:
- server代表一个canal运行实例,对应于一个jvm
- instance对应于一个数据队列 (1个server对应1..n个instance)
instance模块:
- eventParser (数据源接入,模拟slave协议和master进行交互,协议解析)
- eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)
- eventStore (数据存储)
- metaManager (增量订阅&消费信息管理器)
2.canal部署安装
上面我们知道canal是通过把自己伪装成mysql slave,收集binlog做解析,然后再进行后续同步操作。所以我们的准备工作必须要求MySQL开启binlog日志:
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
当然也可以不用新增账号,直接使用root账号,为了方便快捷,我下面的案例就是使用root账号的哦,当然这不符合开发规范,root权限账号一般人不能用的~
接下来就是安装canal了,安装方式主要分为直接下载安装包在服务器通过命令运行和使用docker容器化方式部署,docker容器部署虽然简单快捷,但是考虑到不是人人都了解docker,所以我们这里采用直接使用安装包命令运行。
安装包命令运行其实很简单,官网教程步骤也很详细:github.com/alibaba/can…,这里我下载version为1.1.5的,在官网下载安装包解压之后文件如下:
bin canal.deployer-1.1.5.tar.gz conf lib logs plugin主要看看conf目录下配置文件:
canal.properties example logback.xml metrics springcanal.properties是启动canal server的配置文件:这里面有很多配置,我粘贴部分来讲讲
#################################################
######### destinations #############
#################################################
canal.destinations = example
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
# set this value to 'true' means that when binlog pos not found, skip to latest.
# WARN: pls keep 'false' in production env, or if you know what you want.
canal.auto.reset.latest.pos.mode = false
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = spring
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
canal.destinations = example就是指定instance实例的查找位置,如果我们一个canal server需要监听多个instance(平时各个业务线的数据库都是独立的如商品product,仓库warehouse),一个instance监听一个数据库,这是最常见的需求了,这时候我就需要配置多个instance,可以直接把example文件夹拷贝两份,分别用数据库命名新文件夹这样方便我们快速了解该文件夹对应的instance是哪个业务线的。然后就是调整canal.properties
canal.destinations = product,warehouse
紧接着就是修改每个instance文件下的instance.properties,适配监听的数据库配置信息
## mysql serverId , v1.0.26+ will autoGen
## v1.0.26版本后会自动生成slaveId,所以可以不用配置
# canal.instance.mysql.slaveId=0
# 数据库地址
canal.instance.master.address=127.0.0.1:3306
# binlog日志名称
canal.instance.master.journal.name=mysql-bin.000001
# mysql主库链接时起始的binlog偏移量
canal.instance.master.position=154
# mysql主库链接时起始的binlog的时间戳
canal.instance.master.timestamp=
canal.instance.master.gtid=
# username/password
# 在MySQL服务器授权的账号密码
canal.instance.dbUsername=canal
canal.instance.dbPassword=Canal@123456
# 字符集
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
# table regex .*\..*表示监听所有表 也可以写具体的表名,用,隔开
canal.instance.filter.regex=.*\..*
# mysql 数据解析表的黑名单,多个表用,隔开
canal.instance.filter.black.regex=
最后在安装包目录下执行以下命令就可以启动了:
sh bin/startup.sh是不是很简单!!! 但是你有没有发现这种方式每新增一个instance,都需要修改配置文件并重启,这样会导致数据同步中断不太友好,而且也没有canal server服务的状态监控,着实觉得这框架不够完善。阿里巴巴也考虑到了这些问题,所以提供了canal-admin,canal-admin设计上是为canal提供整体配置管理、节点运维等面向运维的功能,提供相对友好的WebUI操作界面,方便更多用户快速和安全的操作。注意:canal-admin有以下限制要求:
MySQL,用于存储配置和节点等相关数据 canal版本,要求>=1.1.4 (需要依赖canal-server提供面向admin的动态运维管理接口)
在官网下载canal-admin的安装包解压如下:
bin canal.admin-1.1.5.tar.gz conf lib logs直接来看conf下的文件:
application.yml canal_manager.sql canal-template.properties instance-template.properties logback.xml public
这里看到的就是一个spring boot框架开发的web项目啦,anal_manager.sql就是canal-admin服务所依赖的数据库初始化脚本,我们得去MySQL执行,然后修改配置文件application.yml
server:
port: 8089
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: 10.10.0.10:3306
database: canal_manager
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminUser: admin
adminPasswd: admin
这里就配置一下前面执行SQL脚本数据库的连接信息即可,当然如果端口8089被占用了就改成别的,到时候canal server配置对应的就行。在canal-admin的目录执行下面命令就能启动了:
sh bin/startup.sh这时候通过主机ip:8089就能在浏览器访问:

默认登录用户名密码:admin/123456,成功进入之后:

我们可以通过界面管理canal集群、canal server 、server下的instance。这样无论是我们修改instance的配置还是新增一个instance都不需要去服务器操作并重启服务了,是不是很方便,直接通过界面操作修改、重启即可。
当然还是需要像一开始一样在服务器启动canal server的,需要把配置canal.properties改成如下:
# register ip
canal.register.ip =
# canal admin config
canal.admin.manager = 10.10.0.10:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster =
canal.admin.register.name =
这里最主要是绑定关联canal-admin,配置admin的地址信息。这里提一下canal.register.ip这个配置是和canal集群有关的,canal集群是依靠zookeeper实现,这里就不展开细讲了。成功启动canal server之后,就可以在admin界面看到了:

然后我们可以基于canal server新增instance:mall和fast-api

这时候你来查看canal server 下的配置目录conf下:
canal.properties example fast-api logback.xml mall metrics spring发现多了两个目录mall和fast-api,这就是对应我们前面在界面上创建的两个instance,admin通过关联canal server自动帮我们生成,是不是很完美!!!
3.Spring Boot整合canal
3.1数据库与缓存一致性问题概述
自有了缓存的那一天起,缓存与数据库数据一致性问题就一直伴随着后端开发者,所以如何保证数据库与缓存双写数据一致性也成为了面试的一个高频考点。对于缓存的更新肯定来自于业务的触发,且最终的逻辑处理数据是需要落库的,只是我们需要考虑的是先更新DB还是先更新缓存?是更新缓存还是删除缓存?在常规情况下,怎么操作都可以,但一旦面对高并发场景,就值得细细思量了。 接下来我们就来分别看看先写数据库或者先写缓存有啥问题?
这里我们假设我们的某个业务功能请求就是修改某个数据值
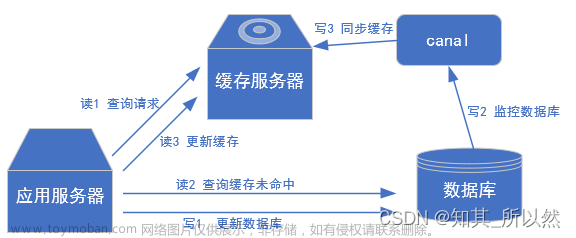
先写 MySQL,再写 Redis
请求 A、B 都是先写 MySQL,然后再写 Redis,在高并发情况下,如果请求 A 在写 Redis 时卡了一会,请求 B 已经依次完成数据的更新,就会出现图中的问题。并发场景下,这样的情况是很容易出现的,每个线程的操作先后顺序不同,这样就导致请求B的缓存值被请求A给覆盖了,数据库中是线程B的新值,缓存中是线程A的旧值,并且会一直这么脏下去直到缓存失效(如果你设置了过期时间的话)。

先写Redis,再写MySQL
和上面一样只是调换了写入数据库与缓存的顺序,直接看图:

高并发场景下一样有数据一致性问题。
还有数据更新删除缓存、延时双删缓存等解决一致性问题方式,这里就不一一列举了,本质上上面我只是引出数据库与缓存双写一致性问题,毕竟我们今天主题是canal,不是双写一致性问题解决方案详解,有兴趣可以自行查阅这个高频面试知识。
3.2 整合canel
canal官方没有提供与spring-boot框架快速整合的starter,根据官网示例直接使用canal client直连canal server操作:
引入依赖:
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.4</version>
</dependency>
示例:我们在上面的canal admin创建一个mall的实例监听mall数据库变化,接下来我通过新增、修改、删除品牌的一条数据。
package com.shepherd.common.canal;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.ByteString;
import com.google.protobuf.InvalidProtocolBufferException;
import java.net.InetSocketAddress;
import java.util.List;
public class CanalClient {
public static void main(String[] args) throws InterruptedException, InvalidProtocolBufferException {
// 创建canal客户端,单链接模式
CanalConnector canalConnector = CanalConnectors.newSingleConnector(new InetSocketAddress("10.10.0.10",
11111), "mall", "", "");
// 创建连接
canalConnector.connect();
while (true) {
// 订阅数据库
// canalConnector.subscribe("mall");
// 获取数据
Message message = canalConnector.get(100);
// 获取Entry集合
List<CanalEntry.Entry> entries = message.getEntries();
// 判断集合是否为空,如果为空,则等待一会继续拉取数据
if (entries.size() <= 0) {
// System.out.println("当次抓取没有数据,休息一会。。。。。。");
Thread.sleep(1000);
} else {
// 遍历entries,单条解析
for (CanalEntry.Entry entry : entries) {
//1.获取表名
String tableName = entry.getHeader().getTableName();
//2.获取类型
CanalEntry.EntryType entryType = entry.getEntryType();
//3.获取序列化后的数据
ByteString storeValue = entry.getStoreValue();
//4.判断当前entryType类型是否为ROWDATA
if (CanalEntry.EntryType.ROWDATA.equals(entryType)) {
//5.反序列化数据
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue);
//6.获取当前事件的操作类型
CanalEntry.EventType eventType = rowChange.getEventType();
//7.获取数据集
List<CanalEntry.RowData> rowDataList = rowChange.getRowDatasList();
//8.遍历rowDataList,并打印数据集
for (CanalEntry.RowData rowData : rowDataList) {
JSONObject beforeData = new JSONObject();
List<CanalEntry.Column> beforeColumnsList = rowData.getBeforeColumnsList();
for (CanalEntry.Column column : beforeColumnsList) {
beforeData.put(column.getName(), column.getValue());
}
JSONObject afterData = new JSONObject();
List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList();
for (CanalEntry.Column column : afterColumnsList) {
afterData.put(column.getName(), column.getValue());
}
//数据打印
System.out.println("Table:" + tableName +
",EventType:" + eventType +
",Before:" + beforeData +
",After:" + afterData);
}
}
}
}
}
}
}
控制台打印如下:
Table:brand,EventType:INSERT,Before:{},After:{"image":"","update_time":"","category_id":"1","create_time":"","letter":"H","name":"huawei","description":"世界第一名族企业","id":"1","is_delete":""}
Table:brand,EventType:UPDATE,Before:{"image":"","update_time":"","category_id":"1","create_time":"","letter":"H","name":"huawei","description":"世界第一名族企业","id":"1","is_delete":""},After:{"image":"http://www.baidu.com/image1.png","update_time":"","category_id":"1","create_time":"","letter":"H","name":"huawei111","description":"世界第一名族企业","id":"1","is_delete":""}
Table:brand,EventType:DELETE,Before:{"image":"http://www.baidu.com/image1.png","update_time":"","category_id":"1","create_time":"","letter":"H","name":"huawei111","description":"世界第一名族企业","id":"1","is_delete":""},After:{}
可以看到canal监控到表数据的变更方式以及数据的前后变化。这样我们就可以通过canal监听MySQL binlog原理优雅实现缓存与数据库数据一致性解决方案啦,通过的监听得到数据信息进行缓存同步写操作即可。
4.总结
canal是一个增量数据同步组件,其好处就是在于对业务逻辑无侵入,它是通过把自己伪装成mysql slave收集binlog实现数据同步的。这里要强调一下异构数据源之间要实现数据增量同步,同时要保证实时性、低延时在大数据领域也是一个令人头疼的问题,不像全量同步简单直接全部数据写到目的源就可以了。canal就是为了解决增量同步而生,这是其招牌。当然canal也是有缺点的,只能监听MySQL,其他数据库oracle就不行了。
同时也要指明企业级的数据同步不可能像上面的方式一条条监听数据变化同步异构数据源如elasticsearch、Hbase的,因为一条条处理同步速度之慢不言而喻,当然通过上面方式同步数据到缓存redis是可以的,因为缓存的数据一般变化不频繁且数据量不大,但同步其他大数据组件就一般都需要批量同步了,这时候就需要借助消息队列中间件如kafka进行数据堆积从而实现批量同步,canal+kafka+elasticsearch这个架构是当下许多企业中较常见的一种数据同步的方案。文章来源:https://www.toymoban.com/news/detail-841409.html
 文章来源地址https://www.toymoban.com/news/detail-841409.html
文章来源地址https://www.toymoban.com/news/detail-841409.html
到了这里,关于Spring Boot整合canal实现数据一致性解决方案解析-部署+实战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!