前言
最近在学习视频剪辑的时候,希望找一款软件进行翻译;发现大多数是调用某云的Api进行翻译。通过查询资料,打算使用Whisper进行本地视频语音的识别,然后进行字幕文件的编辑(srt),最后通过ffmpeg添加到视频中。
Whisper 是 OpenAI 构建的通用语音识别模型。它于 2022 年底正式向公众发布,现已成为最先进的语音识别模型之一。可以进行多语言语音识别、语言翻译和语言识别。
废话不多说,上代码。
一、安装
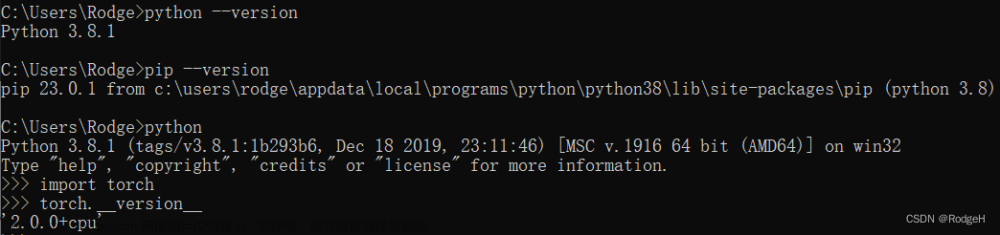
Whisper需要用到英伟达显卡进行翻译,所以需要安装pytorch的cpu版本。
pip install torch --index-url https://download.pytorch.org/whl/cu118
安装openai-whisper模块
pip install -U openai-whisper
二、Whisper
根据自己显卡的显存大小,选择不同的whisper模型。
| 模型 | 要求的显存 | 速度 |
|---|---|---|
| tiny | 大于1GB | ~32x |
| base | 大于1GB | ~16x |
| small | 大于2GB | ~6x |
| medium | 大于5GB | ~2x |
| large | 大于10GB | ~1x |
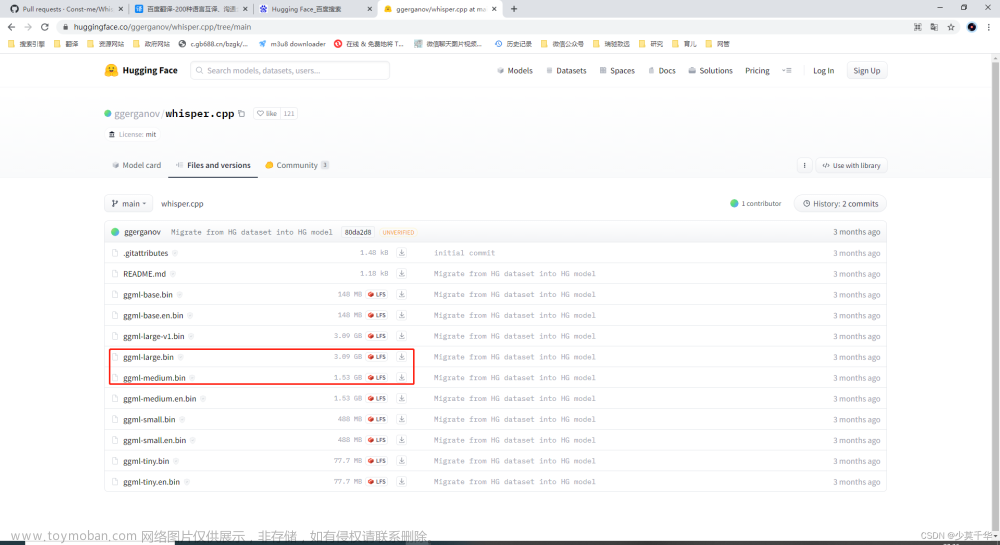
1.下载模型
下载base模型到C:\Users\用户.cache\whisper文章来源:https://www.toymoban.com/news/detail-841527.html
import whisper
model = whisper.load_model("base")
也可以指定下载路径文章来源地址https://www.toymoban.com/news/detail-841527.html
import whisper
model = whisper.load_model("base", download_root="路径")
2.视频语音识别
# 视频路径
video_path = "./Who are you.mp4"
到了这里,关于不到百行代码,使用Whisper进行视频字幕生成。的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!