1.背景介绍
大数据时代,数据处理能力成为了企业竞争的核心。随着数据规模的不断增长,传统的数据处理技术已经无法满足企业的需求。为了更好地处理大规模数据,Apache Flink 和 Apache Kafka 等流处理框架和消息队列系统发展迅速。
Apache Flink 是一个流处理框架,可以实时处理大规模数据流。它具有高吞吐量、低延迟和强一致性等优势。而 Apache Kafka 是一个分布式消息队列系统,可以实现高吞吐量的数据传输。两者结合,可以构建出一个高效、可扩展的大数据处理平台。
本文将从以下几个方面进行阐述:
- 背景介绍
- 核心概念与联系
- 核心算法原理和具体操作步骤以及数学模型公式详细讲解
- 具体代码实例和详细解释说明
- 未来发展趋势与挑战
- 附录常见问题与解答
1.背景介绍
1.1 Apache Flink
Apache Flink 是一个用于流处理和批处理的开源框架。它可以处理实时数据流和批量数据,提供了强一致性和低延迟的处理能力。Flink 支持各种数据类型,如键值对、表格数据和复杂对象。它还提供了丰富的数据处理功能,如窗口操作、连接操作、聚合操作等。
Flink 的核心组件包括:
- 数据源(Source):用于从外部系统读取数据,如Kafka、HDFS、TCP socket等。
- 数据接收器(Sink):用于将处理结果写入外部系统,如Kafka、HDFS、TCP socket等。
- 数据流(Stream):用于表示数据的流动过程,可以通过各种操作符进行处理。
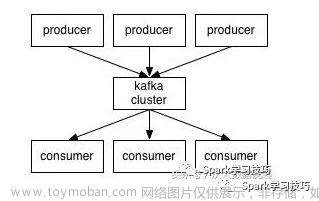
1.2 Apache Kafka
Apache Kafka 是一个分布式消息队列系统,可以处理实时数据的高吞吐量传输。Kafka 通过分区和复制机制实现了高可靠性和扩展性。它主要用于构建实时数据流处理系统、日志处理系统、消息队列系统等。
Kafka 的核心组件包括:
- 生产者(Producer):用于将数据发送到 Kafka 集群。
- 消费者(Consumer):用于从 Kafka 集群中读取数据。
- * broker*:用于存储和管理数据的服务器。
2.核心概念与联系
2.1 Flink 与 Kafka 的集成
Flink 与 Kafka 的集成主要通过 Flink 的数据源(Source)和数据接收器(Sink)来实现。Flink 提供了 Kafka 数据源(FlinkKafkaConsumer)和 Kafka 数据接收器(FlinkKafkaProducer)来与 Kafka 进行交互。
2.1.1 FlinkKafkaConsumer
FlinkKafkaConsumer 是 Flink 中用于从 Kafka 读取数据的数据源。它可以从一个或多个 Kafka 主题中读取数据,并将数据转换为指定的数据类型。FlinkKafkaConsumer 支持各种配置参数,如:
- groupId:用户组 ID,用于标识消费者组。
- topic:Kafka 主题名称。
- bootstrap.servers:Kafka broker 列表。
- keyDeserializer:键的反序列化器。
- valueDeserializer:值的反序列化器。
- properties:其他 Kafka 配置参数。
2.1.2 FlinkKafkaProducer
FlinkKafkaProducer 是 Flink 中用于将数据写入 Kafka 的数据接收器。它可以将 Flink 数据流写入一个或多个 Kafka 主题,并支持各种配置参数,如:
- groupId:用户组 ID,用于标识消费者组。
- topic:Kafka 主题名称。
- bootstrap.servers:Kafka broker 列表。
- keySerializer:键的序列化器。
- valueSerializer:值的序列化器。
- properties:其他 Kafka 配置参数。
2.2 Flink 与 Kafka 的数据流转
Flink 与 Kafka 的数据流转过程如下:
- Flink 通过 FlinkKafkaConsumer 从 Kafka 中读取数据。
- Flink 对读取到的数据进行处理,如转换、聚合、窗口操作等。
- Flink 通过 FlinkKafkaProducer 将处理结果写入 Kafka。
这样,Flink 和 Kafka 可以构建出一个高效、可扩展的大数据处理平台。
3.核心算法原理和具体操作步骤以及数学模型公式详细讲解
3.1 FlinkKafkaConsumer 的读取过程
FlinkKafkaConsumer 的读取过程主要包括以下步骤:
- 连接到 Kafka:FlinkKafkaConsumer 通过提供的 bootstrap.servers 参数连接到 Kafka 集群。
- 订阅主题:FlinkKafkaConsumer 通过指定 topic 参数订阅 Kafka 主题。
- 消费消息:FlinkKafkaConsumer 通过消费者组(groupId)订阅的主题中消费消息。
FlinkKafkaConsumer 的读取过程可以通过以下数学模型公式表示:
$$ R = FlinkKafkaConsumer(groupId, topic, bootstrap.servers, keyDeserializer, valueDeserializer, properties) $$
其中,$R$ 表示 FlinkKafkaConsumer 的读取过程。
3.2 FlinkKafkaProducer 的写入过程
FlinkKafkaProducer 的写入过程主要包括以下步骤:
- 连接到 Kafka:FlinkKafkaProducer 通过提供的 bootstrap.servers 参数连接到 Kafka 集群。
- 订阅主题:FlinkKafkaProducer 通过指定 topic 参数订阅 Kafka 主题。
- 发送消息:FlinkKafkaProducer 通过消费者组(groupId)订阅的主题发送消息。
FlinkKafkaProducer 的写入过程可以通过以下数学模型公式表示:
$$ S = FlinkKafkaProducer(groupId, topic, bootstrap.servers, keySerializer, valueSerializer, properties) $$
其中,$S$ 表示 FlinkKafkaProducer 的写入过程。
4.具体代码实例和详细解释说明
4.1 FlinkKafkaConsumer 示例
以下是一个使用 FlinkKafkaConsumer 从 Kafka 中读取数据的示例:
```java import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class FlinkKafkaConsumerExample { public static void main(String[] args) throws Exception { // 设置 Flink 执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置 Kafka 消费者组 ID
String groupId = "flink_consumer_group";
// 设置 Kafka 主题
String topic = "test_topic";
// 设置 Kafka 连接参数
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("keyDeserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("valueDeserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 创建 FlinkKafkaConsumer
FlinkKafkaConsumer<String, String> consumer = new FlinkKafkaConsumer<>(
topic,
new KeyValueDeserializationSchema<String, String>() {
@Override
public String deserializeKey(String key, long l) {
return key;
}
@Override
public String deserializeValue(String value) {
return value;
}
},
properties
);
// 从 Kafka 中读取数据
DataStream<Tuple2<String, String>> dataStream = env.addSource(consumer)
.keyBy(0)
.map(new MapFunction<Tuple2<String, String>, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(Tuple2<String, String> value) throws Exception {
return new Tuple2<String, Integer>("word", 1);
}
});
// 输出结果
dataStream.print();
// 执行 Flink 程序
env.execute("FlinkKafkaConsumerExample");
}} ```
在这个示例中,我们首先设置了 Flink 执行环境,然后设置了 Kafka 消费者组 ID、Kafka 主题和 Kafka 连接参数。接着,我们创建了 FlinkKafkaConsumer,并将其添加到 Flink 数据流中。最后,我们输出了结果。
4.2 FlinkKafkaProducer 示例
以下是一个使用 FlinkKafkaProducer 将数据写入 Kafka 的示例:
```java import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
public class FlinkKafkaProducerExample { public static void main(String[] args) throws Exception { // 设置 Flink 执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置 Kafka 主题
String topic = "test_topic";
// 设置 Kafka 连接参数
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("keySerializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty("valueSerializer", "org.apache.kafka.common.serialization.StringSerializer");
// 创建 FlinkKafkaProducer
FlinkKafkaProducer<String, String> producer = new FlinkKafkaProducer<>(
topic,
new SimpleStringSchema(),
properties
);
// 创建 Flink 数据流
DataStream<String> dataStream = env.fromElements("hello", "world", "flink");
// 将数据流写入 Kafka
dataStream.addSink(producer);
// 执行 Flink 程序
env.execute("FlinkKafkaProducerExample");
}} ```
在这个示例中,我们首先设置了 Flink 执行环境,然后设置了 Kafka 主题和 Kafka 连接参数。接着,我们创建了 FlinkKafkaProducer,并创建了一个 Flink 数据流。最后,我们将数据流写入 Kafka。
5.未来发展趋势与挑战
5.1 未来发展趋势
- 实时数据处理的发展:随着数据量的增加,实时数据处理技术将越来越重要。Flink 和 Kafka 将继续发展,以满足大数据处理的需求。
- 多源、多目标数据流:将来,Flink 和 Kafka 将能够支持多源、多目标数据流,以实现更加灵活的数据处理。
- 智能化和自动化:Flink 和 Kafka 将更加智能化和自动化,以便更好地处理复杂的数据流。
5.2 挑战
- 性能优化:随着数据规模的增加,Flink 和 Kafka 需要不断优化性能,以满足实时数据处理的需求。
- 容错和一致性:Flink 和 Kafka 需要解决容错和一致性问题,以确保数据的准确性和可靠性。
- 安全性和隐私:随着数据的敏感性增加,Flink 和 Kafka 需要提高安全性和隐私保护。
6.附录常见问题与解答
6.1 问题1:FlinkKafkaConsumer 如何订阅多个主题?
答案:可以通过设置 subscription 参数来订阅多个主题。例如:
java FlinkKafkaConsumer<String, String> consumer = new FlinkKafkaConsumer<>( "test_topic1,test_topic2", new KeyValueDeserializationSchema<String, String>() { // ... }, properties );
6.2 问题2:FlinkKafkaProducer 如何发送到多个主题?
答案:可以通过设置 topic 参数来发送到多个主题。例如:
java FlinkKafkaProducer<String, String> producer = new FlinkKafkaProducer<>( "test_topic1,test_topic2", new SimpleStringSchema(), properties );
6.3 问题3:如何在 Flink 中实现窗口操作?
答案:可以使用 WindowFunction 来实现窗口操作。例如:
java dataStream.keyBy(0) .window(TumblingEventTimeWindows.of(Time.seconds(5))) .apply(new WindowFunction<Tuple2<String, Integer>, String, Tuple2<String, Integer>>() { @Override public String apply(Iterator<Tuple2<String, Integer>> iterator, Tuple2<String, Integer> aggregate, Context context) throws Exception { // ... return null; } }); 文章来源:https://www.toymoban.com/news/detail-841673.html
在这个示例中,我们使用了滑动窗口(TumblingEventTimeWindows),窗口大小为 5 秒。然后,我们使用了 WindowFunction 来实现窗口内数据的处理。文章来源地址https://www.toymoban.com/news/detail-841673.html
到了这里,关于Flink 与 Apache Kafka 的完美结合的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!