目录
Whisper的安装
Whisper的基本使用
识别结果转简体中文
断句
Whisper的安装
Whisper是OpenAI的一个强大的语音识别库,支持离线的语音识别。在使用之前,需要先安装它的库:
pip install openai-whisper使用whisper,还需安装setuptools-rust:
pip install setuptools-rust但是,whisper安装时,自带的pytorch可能有些bug,因此需要卸载重装:
卸载:
pip uninstall torch重装:
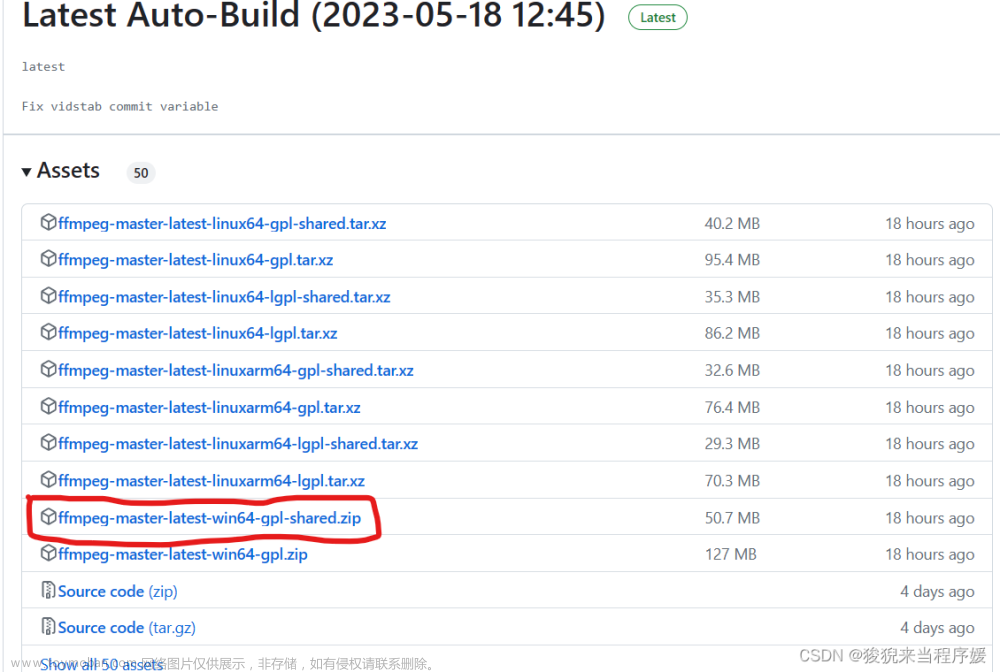
pip install torch另外,需要通过choco安装ffmpeg库。先通过管理员权限的PowerShell安装choco:
Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072;
iex ((New-Object System.Net.WebClient).DownloadString('https://chocolatey.org/install.ps1'))然后,在管理员权限的PowerShell安装ffmpeg:
choco install ffmpeg完成这些步骤之后,我们就可以使用啦!
Whisper的基本使用
whisper的基本代码如下:
import whisper
model = whisper.load_model("base")
result = model.transcribe("zh.wav")
print(result['text'])
其中,zh.wav可以换成你自己的音频。我的控制台输出:
我們說,40月2日混淩土不能與引力長相互攪拌不然會因為愛銀斯坦的相對論而引發雜串的食品安全問題這是嚴重的金融危機可以看到,它的识别结果还行(因为我的音频是AI合成的,识别会有一定误差),但是输出的是繁体中文,我们需要把他变成简体中文。
识别结果转简体中文
可以通过opencc库实现转化,先安装:
pip install opencc然后修改代码:
import whisper
import opencc
model = whisper.load_model("base")
result = model.transcribe("zh.wav")
cc = opencc.OpenCC("t2s")
res = cc.convert(result['text'])
print(res)输出:
我们说,40月2日混凌土不能与引力长相互搅拌不然会因为爱银斯坦的相对论而引发杂串的食品安全问题这是严重的金融危机断句
在一个语音中,我们都会有一些停顿。但是,在识别结果中,这些停顿并没有被完全表示出来。我们可以如此修改代码,实现按断句输出结果:文章来源:https://www.toymoban.com/news/detail-841702.html
import whisper
import opencc
model = whisper.load_model("base")
result = model.transcribe("zh.wav")
cc = opencc.OpenCC("t2s")
for i in result['segments']:
res = cc.convert(i['text'])
print(f"断句开始于{i['start']}秒,结束于{i['end']}秒,识别结果:{res}")输出:文章来源地址https://www.toymoban.com/news/detail-841702.html
断句开始于0.0秒,结束于5.36秒,识别结果:我们说,40月2日混凌土不能与引力长相互搅拌
断句开始于5.36秒,结束于11.14秒,识别结果:不然会因为爱银斯坦的相对论而引发杂串的食品安全问题
断句开始于11.14秒,结束于13.44秒,识别结果:这是严重的金融危机到了这里,关于Python使用whisper实现语音识别(ASR)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!