python实现视频或音频转文本
当然可以,以下是您的Python语音视频转文本代码的描述:
内容概要:
这段Python代码利用强大的语音识别库,能够自动将本地存储的语音视频文件转换成文本。它通过分析音频轨道中的语音数据,识别并转录为可编辑和可搜索的文本格式。
适用人群:
- 开发者和程序员,希望在他们的项目中集成语音识别功能。
- 数据科学家和工程师,需要从音频资料中提取文本数据进行分析。
- 教育工作者和在线内容创作者,希望为视频提供文字版内容。
- 语言学习者,通过转录音频来学习和练习。
适用场景及目标:
- 自动化工作流程:将会议录音、讲座或播客自动转换为文本,提高工作效率。
- 数据收集和分析:从音频资料中提取文本,用于进一步的语言分析或机器学习训练。
- 内容创作:为视频或音频内容创建字幕,增加可访问性和观众范围。
- 语言学习:帮助学习者通过对照转录文本和原始音频来提高语言技能。
其他说明:
- 代码可定制性强,可根据需求调整识别准确度和处理速度。
- 支持多种音频格式,灵活适应不同的文件类型。
- 可以轻松集成到现有的Python项目中,与其他库和框架兼容。
- 注重用户隐私,不会上传文件到外部服务器进行处理。
# -*- coding: utf-8 -*-
import speech_recognition as sr
import subprocess
import os
def transcribe_audio(file_path):
"""
将音频文件识别内容,并将语音转为文字。
参数:
file_path: 音频文件的路径。
返回:
识别出的文本。
"""
# 创建 SpeechRecognition 对象
r = sr.Recognizer()
# 将文件转换为flac文件
directory = os.path.dirname(file_path)
flac_file_path = directory+"/output.flac"
subprocess.run(["ffmpeg", "-i", file_path, "-acodec", "flac", flac_file_path], encoding='utf-8')
# 打开转换后的音频文件
with sr.AudioFile(flac_file_path) as source:
audio = r.record(source)
# 识别语音
try:
text = r.recognize_google(audio, language='zh-CN')
except sr.RequestError:
print("API 请求失败")
except sr.UnknownValueError:
print("无法识别语音")
finally:
# 删除文件 output.flac
os.remove(flac_file_path)
return text
if __name__ == '__main__':
# 将本地音频文件识别内容,并转为文字
audio_file_path = "文件路径"
text = transcribe_audio(audio_file_path)
print(text)
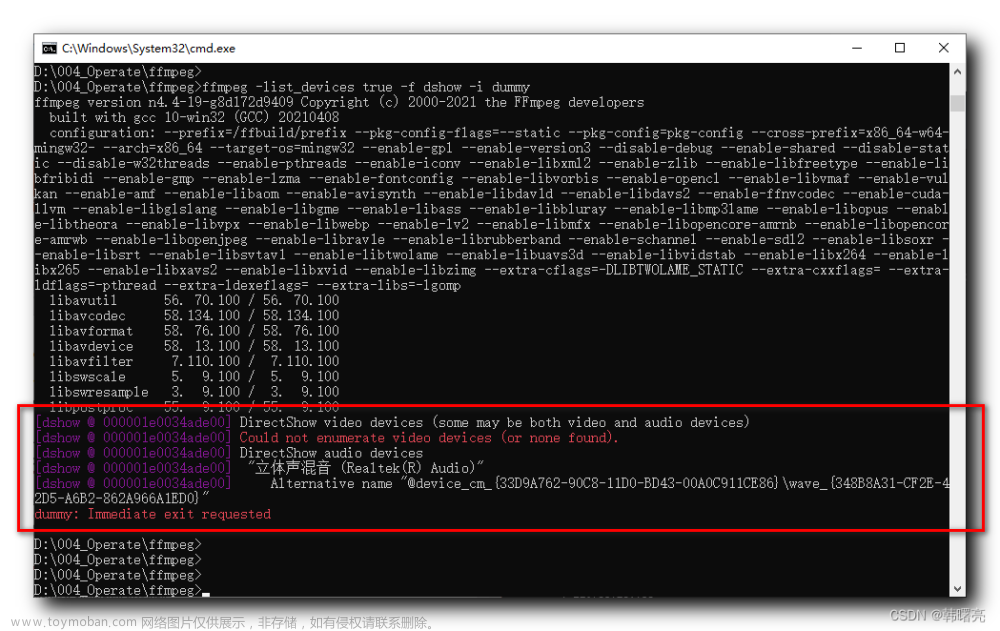
ps: 运行之前,先将依赖安装好,安装完之后,需要在全局安装 ffmpeg 包,打开cmd窗口,执行
pip install ffmpeg
mac的同学执行文章来源:https://www.toymoban.com/news/detail-841716.html
brew install ffmpeg
如果还有其他问题,可以留言或评论,笔者会帮忙解决~文章来源地址https://www.toymoban.com/news/detail-841716.html
到了这里,关于python实现视频或音频转文本的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!