聊到AI绘画,基本上就会聊到SD这个概念,毕竟作为开源可以本地部署的AI绘画软件,SD可能是目前的唯一选择,不管是webUI或者ComfyUI,还有国内的很多套壳绘画AI,都是sd作为基础进行二次优化的。那么SD到底是个啥,这篇文章就结合我个人的理解简单跟大家聊聊。
基础介绍
SD全称是Stable Diffusion,稳定扩散模型,可以理解为一种技术,而大家常说的WebUI或者Comfyui都是这个技术的界面层,所以这一点首先要了解。
Stable Diffusion模型是一种基于扩散过程的生成模型,它用于生成高质量的图像。这种模型是在传统的扩散模型(Denoising Diffusion Probabilistic Models, DDPMs)的基础上发展而来的。
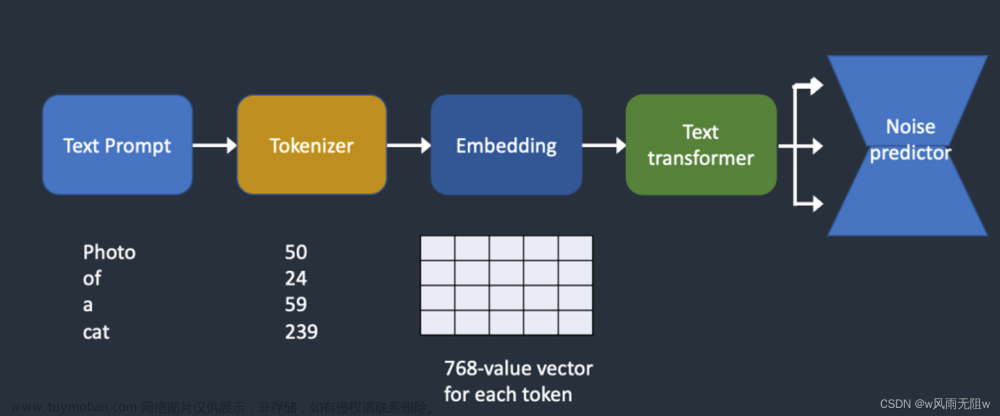
那么,SD的架构长什么样子呢?接下来要放出这张已经被很多人发过的图片了:
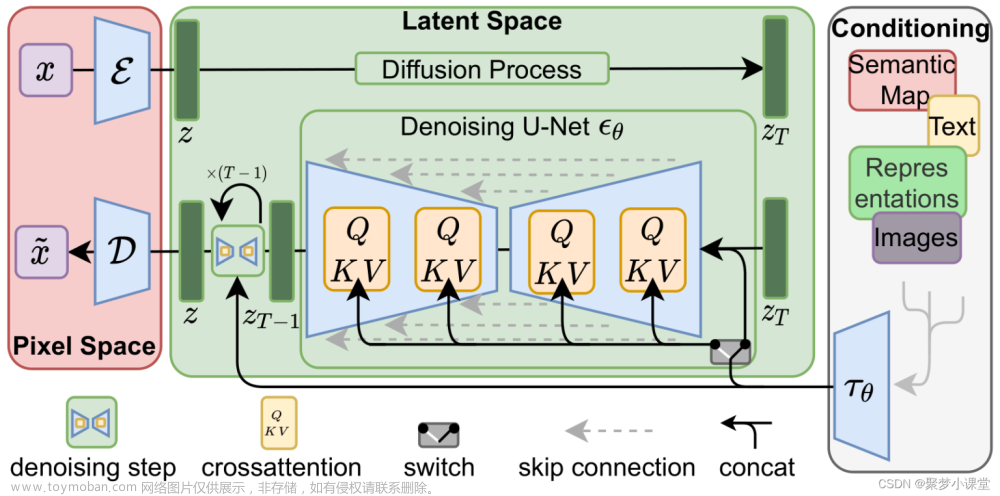
Stable Diffusion的改进
Stable Diffusion模型的主要改进在于它在潜在空间(latent space)中进行扩散过程,而不是在原始图像空间。这使得模型在生成图像时速度更快,同时保持了高质量的输出。
-
潜在空间(Latent Space):首先,模型训练一个自编码器(autoencoder),将原始图像压缩到一个低维的潜在空间表示。这个表示包含了图像的压缩信息,但尺寸远小于原始图像。
-
在潜在空间中的扩散:在潜在空间中进行正向和反向扩散过程。由于潜在数据的尺寸较小,这大大加快了去噪过程。
-
条件生成:Stable Diffusion模型可以接收文本提示作为条件输入,这使得模型能够根据文本描述生成相应的图像。这是通过将文本提示转换为嵌入向量,并通过注意力机制(如Transformer)与潜在数据结合来实现的。
核心组件构成
没错,stable diffusion其实是由三部分组成的,而每一个都可以理解为一个较为独立的模块,每次使用的时候,不管是文生图还是图生图,都是他们三个相互配合才能生成一张图片,
-
VAE(变分自编码器,Variational Auto-Encoder):VAE负责将原始图像压缩到一个低维的潜在空间(latent space)表示,这个表示被称为潜在数据。VAE由编码器(Encoder)和解码器(Decoder)两部分组成,编码器将图像压缩成潜在数据,解码器则将潜在数据还原为图像。
-
U-Net:U-Net是一个深度神经网络,它在Stable Diffusion中扮演着去噪器的角色。在扩散过程中,U-Net学习如何逐步去除添加到潜在数据中的噪声,从而生成清晰的图像。U-Net通常包含多个卷积层,以及用于处理时间步的调度算法。
-
CLIP Text Encoder:这是一个基于Transformer的语言模型,用于将文本输入转换为数字表示,即文本嵌入(embeddings)。这些文本嵌入随后被用作条件信息,指导图像生成过程,使得生成的图像与文本描述相匹配。
这三个组件共同工作,使得Stable Diffusion能够根据文本提示生成高质量的图像。在生成过程中,模型首先在潜在空间中进行正向扩散,添加噪声,然后在反向扩散过程中,通过U-Net逐步去除噪声,最终由VAE的解码器生成最终的图像。CLIP Text Encoder在整个过程中提供文本条件,确保生成的图像与输入的文本描述相符。
篇幅有限,我们这里先讲讲vae,因为在comfyui里边经常看到个VAE encoder,VAE decoder,到底编码解码的在玩啥?
VAE是干啥的
首先,它肯定不是有些自媒体朋友们讲的,就是个滤镜,它真的不是滤镜,虽然看起来效果上,有点类似加了个滤镜...
VAE(变分自编码器,Variational Auto-Encoder)是一种深度学习模型,它结合了自编码器(Auto-Encoder)的结构和概率图模型(如贝叶斯网络)的原理。
在Stable Diffusion模型中,VAE的编码器部分负责将图像压缩到潜在空间(latent space),而解码器部分则在生成过程中将潜在数据转换回像素空间,从而生成最终的图像。这种结构使得Stable Diffusion能够在潜在空间中高效地进行图像生成和编辑。
潜空间latent space是个啥?
Latent Space(潜在空间)是机器学习和深度学习中的一个概念,它指的是数据的一种低维表示,这种表示能够捕捉数据的主要特征和结构。在潜在空间中,数据的复杂性被简化,使得数据点之间的模式和关系更加清晰,便于分析和理解。
潜在空间的特点包括:
-
低维性:潜在空间通常具有比原始数据空间更低的维度。这意味着它能够通过较少的变量来表示数据,从而减少计算复杂度。
-
压缩表示:潜在空间中的每个点代表了原始数据的一个压缩版本,这种压缩保留了数据的关键信息,同时去除了冗余和噪声。
-
特征学习:通过潜在空间,模型可以学习到数据的内在特征,这些特征对于执行特定任务(如分类、回归或生成)可能是有用的。
-
模式识别:在潜在空间中,相似或相关的数据点会彼此靠近,这有助于识别数据中的模式和结构。
-
生成能力:在生成模型(如变分自编码器VAE或生成对抗网络GAN)中,潜在空间可以用来生成新的数据实例。通过在潜在空间中选择或随机采样点,并通过解码器生成对应的数据,可以创造出新的、与训练数据相似的数据点。
潜在空间的概念在许多机器学习应用中都非常重要,因为它提供了一种有效的方式来理解和操作数据,尤其是在处理高维数据时。通过潜在空间,研究人员可以更好地探索数据的内在属性,发现数据之间的关联,以及创造新的数据样本。
是不是还是有点萌萌的?
其实可以简单理解为“概念空间”。并不准确,但是可以这么大概理解,比如说这张图片:

它在像素空间里边是1280x1280像素,每个像素点都是RGB三个色值组成,也就是 3x1280x1280这么大的信息量,可以说,不算小的一张图片了。

但是,在你的脑海里边,并没有记下来这么多的数据,而是有个大概的印象“一个红色的苹果”。
嗯,这张图片,就是像素空间,而这张图片表达的概念,就是“一个红色的苹果”。
很明显,后边这个“概念”占的字符数要小的多。这,就是“latent space”。
VAE如何实现像素图片的压缩呢?
VAE(变分自编码器)实现数据压缩的主要方式是通过其编码器(Encoder)部分,该部分将输入数据映射到一个低维的潜在空间表示。以下是VAE实现压缩的详细过程:
-
编码过程:
- 输入数据(例如图像)首先通过编码器网络。编码器通常由一系列卷积层(对于图像数据)或其他类型的神经网络层组成。
- 每一层都会提取数据的特征,并逐渐降低数据的维度,同时增加网络的深度。这个过程可以看作是对数据的连续压缩。
- 最终,编码器输出一个低维的潜在向量(latent vector),这个向量是原始数据的压缩表示。在VAE中,这个潜在向量通常有两个部分:一个是均值(mean),另一个是方差(variance),它们共同定义了一个概率分布。
-
概率分布:
- VAE的编码器不仅输出潜在向量的均值,还输出与该向量相关的方差。这两个参数定义了一个高斯分布(或其他类型的分布),该分布描述了潜在空间中的数据点是如何围绕均值分布的。
- 这种表示允许模型在潜在空间中进行概率推断,即给定输入数据,模型可以推断出潜在向量的分布,而不仅仅是一个确定的点。
-
重构过程:
- 在压缩的同时,VAE的解码器(Decoder)部分负责从潜在向量重构输入数据。解码器网络的结构通常与编码器相对应,但方向相反,它将潜在向量映射回原始数据空间。
- 重构过程尝试恢复原始数据的细节,但受限于潜在空间的低维性,重构的数据通常会丢失一些信息。这种信息损失是压缩的一部分,因为不是所有的原始数据特征都被保留。
-
损失函数:
- VAE的训练过程中,会最小化重构损失(例如均方误差)和KL散度(Kullback-Leibler divergence)。重构损失确保重构的数据尽可能接近原始数据,而KL散度确保编码器输出的分布接近先验分布(通常是标准正态分布)。
- 通过这种方式,VAE在训练过程中平衡了数据压缩和重构质量。
总结来说,VAE通过编码器将输入数据压缩到一个低维的潜在空间,并通过概率分布来表示数据的不确定性。解码器则尝试从这个潜在表示重构原始数据。VAE的这种结构使得它能够在保持数据主要特征的同时实现有效的数据压缩。
🤔,是不是还是不太好理解,我们简单做个比喻:
想象一下你有一张很大的画,这张画里有很多细节,比如天空、树木、人物等等。现在,如果你想把这张画放进一个很小的火柴盒里,这就要求你的画像素不能太高,你需要做一些简化,去掉一些不那么重要的部分,只保留最重要的信息。这个过程就像是VAE(变分自编码器)在做数据压缩。
VAE有两个主要的部分:一个是编码器,另一个是解码器。
-
编码器:就像一个聪明的画家,它看着你的大画,然后画出一张小草图。这张草图捕捉了大画的主要特征,比如人物的轮廓、树木的形状,但是去掉了很多细节,比如树叶的纹理或者天空的颜色变化。这个小草图就是你的画的压缩版本,它包含了所有让画看起来像原来那幅画的关键信息,但是用更少的笔画来表示。
-
解码器:现在,想象你要把这张小草图变回原来的大画。解码器就像一个魔术师,它看着草图,然后尝试用更多的细节重新画出原来的大画。虽然它可能无法完全恢复所有的细节,但是它能够创造出一个看起来和原来很相似的画。
在VAE中,这个过程是通过数学和计算机程序来完成的。编码器把复杂的数据(比如图片)转换成一个简单的数学表示,这个表示包含了数据的核心特征。然后,解码器再从这个简单的表示中重建出原始数据。通过这种方式,VAE能够在不丢失太多重要信息的情况下,把数据“压缩”到一个更小的空间里。
当然,这也意味,VAE编码的压缩,的确是个“有损压缩”。
好了,压缩完了,就可以丢给U-Net和CLIP Text Encoder去处理后续的步骤了。
篇幅太长了,熬夜太晚也不好,如果对大家有帮助,还希望大家能帮忙点点赞,点点收藏哈,这样才有动力更新后边的内容哈😄
🎉写在最后~
去年的时候写了两门比较基础的Stable Diffuison WebUI的基础文字课程,大家如果喜欢的话,可以按需购买,在这里首先感谢各位老板的支持和厚爱~
✨StableDiffusion系统基础课(适合啥也不会的朋友,但是得有块Nvidia显卡):
https://blog.csdn.net/jumengxiaoketang/category_12477471.html
 🎆综合案例课程(适合有一点基础的朋友):
🎆综合案例课程(适合有一点基础的朋友):
https://blog.csdn.net/jumengxiaoketang/category_12526584.html
 文章来源:https://www.toymoban.com/news/detail-841722.html
文章来源:https://www.toymoban.com/news/detail-841722.html
这里是聚梦小课堂,就算不买课也没关系,点个关注,交个朋友😄文章来源地址https://www.toymoban.com/news/detail-841722.html
到了这里,关于简单聊聊AI绘画中的SD(Stable Diffusion)是什么的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!