前置概念
无并发的解决方案
一些小型项目,或极少有并发的项目,这些策略在无并发情况下,不会有什么问题。
- 读数据策略:有缓存则读缓存,然后接口返回。没有缓存,查询出数据,载入缓存,然后接口返回。
- 写数据策略:数据发生了变动,先删除缓存,再更新数据,等下次读取的时候载入缓存,或一步到位更新数据后直接更新缓存。
- 以上这种方案,有个高大上的名字,叫Cache Aside Pattern。
并发情况下的分布式缓存一致性问题
- 并发:无论是Java的多线程,还是PHP的多进程(默认的单线程),用户量或请求量一上来,就可能有并发问题,正确的应对并发,保证数据不出错,显得尤为重要。
- 缓存:任何组件(不仅是Redis与MySQL),只要源数据并非一成不变,且有缓存机制,就会有一致性的问题。
- 单体架构:强一致性若在单机上,并不是一个问题,例如MySQL的非冗余字段的变动,关联另一个冗余它的字段,这等强一致性的缓存问题,在一个事务里就能维护。
- 分布式:一致性的难点主要在分布式环境下,例如MySQL主从,就添加了bin log与redo log的两阶段提交策略来防止主从数据不一致。针对MySQL与Redis,可以理解成分布式系统,如果没有并发,则按照文章开头的方案正常处理,如果有并发,就需要一些策略保证读取的是最新的缓存数据,因为目前没有一些机制,让MySQL和Redis共同在一个事务内,能一起提交或者回滚,保持强一致。
- 注意:缓存一致性问题是个概率问题,不是一定出现或一定不出现,并发情况下,如果不加锁,MySQL与Redis读写时序是不可控的。
并发与并行,同步与异步
经常听到并发,可真的理解这个概念吗?
- 并发:多过分任务同时进行,但这些任务是交替执行(分配不同的时间片,进程或者线程的上下文切换),好比排n个队去1个窗口办事。
- 并行:多个任务在同一时刻同时执行,通常需要多个或多核处理器,好比排n个队去n个窗口办事。
- 同步:上个任务执行完毕后再执行下一个任务,所以同步没有并发或并行的概念。
- 异步:下一个任务不用等待上个任务执行完。
分布式必知的CAP定理
- 一致性(Consistency):每个节点的数据需要与源数据保持一致,这里往往指的是强一致性。
- 可用性(Availability):这指的是系统能够在任何时刻都对外提供服务,所谓的稳定高可用。
- 分区容错性(Partition Tolerance):分布式系统下,某节点挂掉,还能够对外提供服务的能力。
为什么CAP只能3选2
-
CP舍去A:意味着分布式环境保证强一致,一个数据的变动必须及时通知所有的节点,每个节点为了保证强一致,不得不加锁,此时一个并发过来请求上锁的数据,不是失败就是被阻塞,高可用就达不到。常见于银行,金融,支付系统。
-
AP舍去C:意味着分布式系统舍弃掉一致性,一个数据的变动必须不一定会通知所有的节点,每个节点也不一定加锁,所以就不会出现阻塞或者失败的情况。常见的DNS、CDN系统就是这样,修改源数据不会立即生效,尽管短时间读取还是老数据,但是它不会因为你修改就加锁或者阻塞,它还让你用。
-
CA舍去P:意味着分布式系统下不具有分区容错性,但是是个分布式就有小概率会出问题,尽管很低,想杜绝分区容错性,只能是单体架构。常见于单机系统。
-
架构的设计是根据当前业务特性权衡而来的结果。一个兜底的策略,要看当前业务不能接受哪些缺点,而不是看有哪些优点,然后去一步步演进,改善它。
ACID中的C与CAP中的C
不是一个概念。
- ACID中的C:是事务内的数据,从一个合法状态转换到另一个合法的状态(这里的合法,指符合业务,符合事务的变化规律,A转账B 50元,双方余额加减的过程,数只能是50,不会是60)。
- CAP中的C,缓存的数据需要与源数据保持一致。
分布式必知的BASE理论
可以理解为CAP的宽松方案,通过牺牲数据的强一致性,来获得高可用性。
BASE理论最经典的场景,就是支付回调,支付状态允许存在几秒钟的延迟,而不是支付后实时获取。
-
基本可用性(Basic Availability):允许系统中的某些部分出现故障,保证核心功能的正常运行。常见的负载均衡、服务降级、限流等方式。
-
软状态(Soft state):允许数据存在中间状态,或者说是游离态,允许数据在某些时刻不一致,但是最终达到一致性的状态。支付回调前支付状态的场景。
-
最终一致性(Eventually Consistency):系统中的数据在经过一段时间后,最终会达到一致的状态。不需要强制性的实时保持一致,只需要最后保持一致性。支付回调后支付状态的场景。
强一致性、弱一致性、顺序一致性、线性一致性、因果一致性、最终一致性
- 强一致性:等价严格、原子、线性一致,所有节点操作顺序都与全局时钟下的几乎一致,需加锁,常见于金融、银行场景。
- 弱一致性:能容忍数据短时间内不一致,或能容忍部分数据不一致。常见于CDN和DNS场景。
- 顺序一致性:强一致,在不同的节点上保持一致的操作执行顺序,需要加锁。常见于分布式队列场景。
- 最终一致性:弱一致,最终一致性就属于弱一致性,概念相似。常见于支付回调,离线下载,异步同步大文件的场景。
- 线性一致性:强一致,强一致性、严格一致性、原子一致性一回事,同上。
- 因果一致性:弱一致,属于事件触发类型,因为触发,果为执行,常见于MySQL异步主从(弱一致)、分布式评论系统。
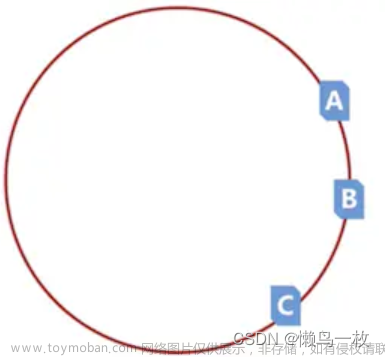
详解顺序一致性:
假设有两个节点,在一个分布式系统中执行写操作。如果 节点A 在时间点 1 执行了写操作 W1,然后 节点B 在时间点 2 执行了写操作 W2。那么顺序一致性要求在分布式系统的其它节点上,读取数据的时候:
应该先看到 W1 的效果,然后才能看到 W2 的效果,而不是先看到W2再看到W1的结果。
并且保证,再同一时间,不能出现节点1看到 W1 的效果,节点2看到 W2 的效果。
全局时钟
分布式下的全局时钟,指的是分布式的每个节点,都有着一致的时间基准,就像共用一个时钟一样,让每个节点在一致的时间线上处理各自的数据,这个非常重要。
实操
增数据后,保证Redis读取的是最新的数据
不存在一致性问题。
请求A新增数据时,有并发读请求B,此时B是查不到缓存的的,就会查询MySQL。
如果B查到数据就载入缓存。
如果B没查到数据,就等后面的请求查询到数据后再载入缓存。
无论B能否查询到缓存,都不影响A的插入,或C的读取,因此不影响数据一致性。
删数据后,保证Redis读取的是最新的数据
- 情况1:不存在一致性问题,缓存中没有这块数据,删除MySQL数据后没有其它副本。
- 情况2:存在一致性问题,缓存中有这块数据,此时就有2种策略:
-
先删除缓存再删除数据:
不行。如果请求A缓存删除成功,此时一个过来一个读请求B,会查询到即将要删掉的MySQL数据,并将其重新载入缓存,请求A执行MySQL delete后,会造成MySQL无数据,Redis有数据的情况,缓存不一致。 -
先删除数据再删除缓存:
也有问题。请求A发现缓存数据不存在,读取了MySQL数据,此时请求B删除MySQL数据,接着请求B删除缓存数据,请求A将老数据写入缓存。此时数据库里没数据,Redis里有数据,缓存不一致。
并发情况下,没办法控制执行顺序问题,所以这就是个概率问题。
改数据后,保证Redis读取的是最新的数据
- 情况1:不存在一致性问题,缓存中没有这块数据,更新MySQL数据后没有其它副本。
- 情况2:存在一致性问题,缓存中有这块数据,此时就有5种策略:
-
先更新数据再更新缓存:
不行。v初始值为0,更新请求A,将值改为1,此时过来更新请求B,将值改为2,确定MySQL最终的值是2。但是受redis网络连接卡顿等影响,更新请求B先将缓存中的v值改为2,更新请求A再将缓存中的值改为1。此时MySQL的值为2,缓存中的值为1,缓存不一致。 -
先更新缓存再更新数据:
不行。v初始值为0,更新请求A修改缓存数据,v值改为1,然后更新MySQL,此时MySQL更新失败,或事务回滚,虽然后续的读缓存的是新数据,数据库的是老数据,但这种脏数据再某些场景下是不允许发生的,缓存不一致。如果非要使用,可以再更新完缓存后,通过消息中间件异步更新数据库。 -
先更新数据再删除缓存:
不行。v初始值为0,更新请求A将v值改为1,更新请求B将v值改为2,更新请求A删除缓存,更新请求B删除缓存,然后A、B都将值写入MySQL。此时查询请求C过来,获取的可以使最新的数据并载入缓存。
另一种情况:
v初始值为0,更新请求A将v值改为1,更新请求B将v值改为2,更新请求A删除缓存,更新请求B删除缓存,然后更新请求A将1写入MySQL,此时查询请求C过来,没有缓存,查MySQL发现是1,载入缓存。更新请求B将MySQL值改为2,此时缓存不一致。
另一种情况:
v初始值为0,读请求X查询不到缓存的数据,于是读MySQL,获取值为0,此时过来一个更新请求Y,将MySQL中的0改为1,然后删除缓存,请求X又将老数据0载入缓存。
此时MySQL值为1,Redis值为0,缓存不一致。 -
先删除缓存再更新数据:
不行。v初始值为0,更新请求A先删除缓存,此时过来一个读请求B,发现没有缓存,读取MySQL,获取值为0,此时更新请求A将MySQL的0改为1,读请求B将Redis v的值改为0,缓存不一致。 -
延时双删:
可以。是最终一致性的方案。
延迟:更新MySQL后,隔一段时间再删除缓存,一般间隔0.3-~1.5秒左右,略大于一个读请求周期的耗时即可。
双删:更新数据库的前后都删除一遍缓存。
v初始值为0,更新请求A先删除缓存,此时读请求B过来,发现没有缓存,去查MySQL后载入缓存,然后更新请求A更新MySQL更新v值为1,再等一段时间,再次删除缓存。此时读请求B查询的是0(为了保证全局的最终一致性,只能牺牲查询请求B),更新请求A中,MySQL和缓存数据一致,都是1。
延迟双删的延迟,是为了保证查询请求B走完流程,如果删除的早,更新请求A先走完流程,那还是会被读请求B的将老数据载入缓存。
延时可通过用Laravel queue或者其它消息中间件去实现。
那如何保证,第二次删除成功呢?
添加重试机制,如果删除失败,可再删除3次。
查数据后,保证Redis读取的是最新的数据
不存在一致性问题。
数据没有写操作。
小结
可见若数据发生了变动,无论以上方案怎么搞,都可能会有不一致的情况。
即使是延迟双删,也会增加运维成本,多了一些工序,它们的高可用又是一类问题。
如果有MySQL+Redis的锁机制,那么其它请求就会阻塞,性能就下降。反过来就影响一致性,这也是CAP三选二的体现。
换个角度讲,对于缓存一致性问题,删除缓存,比更新缓存相对可靠。文章来源:https://www.toymoban.com/news/detail-841785.html
- 如果用更新缓存策略:两个更新的并发请求,更新MySQL的顺序是一种顺序,受网络波动和卡机的影响,更新缓存可能又一种顺序,这可能导致缓存与MySQL值不一致,缓存内部的可能是个错值。
- 如果用删除缓存策略:两个更新的并发请求,更新MySQL的顺序是一种顺序,受网络波动和卡机的影响,缓存也是被删除。最多其它读请求把旧值又给缓存了进去,但至少是个旧值,而不是个错值。
简单的兜底策略
加上缓存过期时间。避免MySQL与缓存长期不一致,对实时性要求越高,则缓存过期时间越少。
一些粒度更细的自定义存储方式,用不了Redis对key的自动过期功能,可添加时间戳字段,用程序逻辑控制过期。文章来源地址https://www.toymoban.com/news/detail-841785.html
Canal组件的策略
- 官网:https://github.com/alibaba/canal
- 简介:Canal是用于解决缓存一致性问题的组件。由阿里巴巴开源,Java编写的C/S架构的软件。它的服务端可以伪装成MySQL从机,实时捕获 MySQL 主机的bin log,并将变更事件推送到消息队列或者其它存储中,以实现实时数据同步、对数据仓库的实时分析等应用场景。
- 客户端支持:支持Java、C#、Go、PHP、Python、Rust、NodeJs客户端。
- 支持同步Kafka、ElasticSearch、HBase、RocketMQ、RabbitMQ、pulsarMQ、不支持直连Redis。
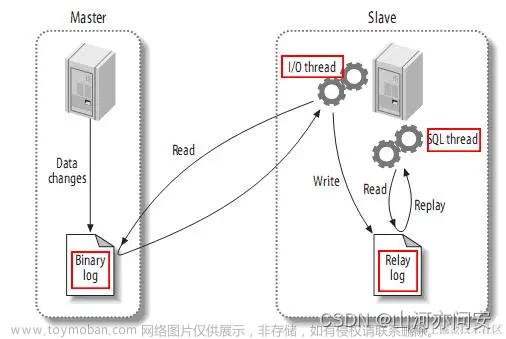
- 前置知识:一文读懂MySQL7大日志(slow、redo、undo、bin、relay、general、error)和简单搭建MySQL主从复制。
- Linux环境,MySQL主机配置
可参考https://github.com/alibaba/canal/wiki/QuickStart
vim /etc/my.cnf
在[mysqld]下写入以下配置
server-id=180 //主机标识,得有一个唯一编号
log-bin=mysql-bin //bin log日志名
binlog_format=row //注意这里一定要用row,用statement或mixed,canal将无法解析
binlog-do-db=test //数据库名
service mysql restart 保存后重启
确认bin log是否开启
select @@sql_log_bin;
+---------------+
| @@sql_log_bin |
+---------------+
| 1 |
+---------------+
登录mysql命令行
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO '从机用户名'@'%';
alter user 'canal'@'%' identified with mysql_native_password by '从机密码,这里设置成canal';
FLUSH PRIVILEGES;
- Linux环境,Canal配置
不管是不是Java开发者,不需要安装JDK或者JRE
mkdir /usr/local/cancl
cd /usr/local/cancl
wget https://github.com/alibaba/canal/releases/download/canal-1.1.7/canal.deployer-1.1.7.tar.gz
tar zxf canal.deployer-1.1.7.tar.gz
修改配置文件
vim /usr/local/canal/conf/example/instance.properties
canal.instance.mysql.slaveId=1 //去掉注释,并修改为非主库server-id的数据
canal.instance.master.address=127.0.0.1:3306 //主库的IP:Port
canal.instance.dbUsername=从机用户名
canal.instance.dbPassword=从机密码
启动,改配置后记得重启。
/usr/local/canal/bin/startup.sh
查看
ps aux | grep canal
- Java或其它语言配置canal客户端:https://github.com/alibaba/canal。
- PHP canal客户端配置:
git clone https://github.com/xingwenge/canal-php.git
cd canal-php
composer install
php src/sample/client.php
只要没提示Socket error: Connection refused (SOCKET_ECONNREFUSED),就说明连接成功。
示例代码如下:
需要注意两个地方
$client->connect("127.0.0.1", 11111);
参数1的值是canal server的ip。
参数2的值是/usr/local/canal/conf/canal.properties文件中的canal.port项,远程连接记得要开放端口。
$client->subscribe("1", "example", ".*\\..*");
参数1是/usr/local/canal/conf/example/instance.properties文件的canal.instance.mysql.slaveId项。
参数2是/usr/local/canal/conf/example,example的目录名,一般不动他,可以配置多个。
参数3有个默认值,排除某个库的某个表。
try {
$client = CanalConnectorFactory::createClient(CanalClient::TYPE_SOCKET_CLUE);
# $client = CanalConnectorFactory::createClient(CanalClient::TYPE_SWOOLE);
$client->connect("127.0.0.1", 11111);
$client->subscribe("1", "example", ".*\\..*");
# $client->subscribe("1001", "example", "db_name.tb_name"); # 设置过滤
while (true) {
$message = $client->get(100);
if ($entries = $message->getEntries()) {
foreach ($entries as $entry) {
Fmt::println($entry);
}
}
sleep(1);
}
$client->disConnect();
} catch (\Exception $e) {
echo $e->getMessage(), PHP_EOL;
}
//当出现以下字样时,说明联调成功。
================> binlog[mysql-bin.000044 : 3130],name[test,cs], eventType: 2
-------> before
id : 1 update= false
num : 6 update= false
-------> after
id : 1 update= false
num : 7 update= true
性能:
官方给出的消费速度:sql insert 10000 事件,32秒消耗完成。消费速度 312.5 条/s。
实测消费速度远高于官方的消费速度,1C1G的本地搭建的服务器:
表中共10000条,不加where全部更新,全部同步耗时2.5秒。
实测平均4000/s的消费速度,意味着每秒有略低于4000个redis key被修改,配置更高的服务器性能将会更好。
这速消费度,大部分的后端接口qps都赶不上,所以足以应对99%的业务场景。
- 对于PHP cancel二次修改,集成到Laravel框架的思路
这种不怎么参与业务,可以集成到框架,也可以不集成,在服务器上单独放一个目录去,cli模式下直接跑也行。
方案1,粗略的整理:将这个包放进laravel的app/Libs中,所有目录结构均不改动,跟框架逻辑无关,仅仅变动跟随Git同步。
二开,redis的连接参数可以硬编码,也可以读取.env的配置,正则匹配获取,要写在while(true)的外面(指的是cancal-php/src/sample/client.php中的while(true))。
方案2,细致的整理:因为目前项目用不上,所以暂时不准备实操,但是思路得有,示例:
composer中的配置,需要集成到框架的composer中,
"require": {
"google/protobuf": "^3.8",
"php": ">=5.6",
"clue/socket-raw": "^1.4"
},
"autoload": {
"psr-4": {
"Com\\Alibaba\\Otter\\Canal\\Protocol\\": "src/protocol/Com/Alibaba/Otter/Canal/Protocol/",
"GPBMetadata\\": "src/protocol/GPBMetadata/",
"xingwenge\\canal_php\\": "src/"
}
}
cancal-php/src/sample/client.php的文件也就不到40行。
这块逻辑可以放到框架的app/Libs下,也可以放到app\Console\Commands,用php artisan xxx命令去执行。
不是依赖包内的其它文件,放在app/Libs/cancal目录下。
核心逻辑接口再src/Fmt.php文件的printLn方法中提供了的可用参数,
有数据库名、表名、操作主键、更改前的值、更改后的值、以及DML动作类型,可以根据这个二开,根据自定义的命名规则,配置自定义redis的动作。
到了这里,关于深入理解高并发下的MySQL与Redis缓存一致性问题(增删改查数据缓存的一致性、Canal、分布式系统CAP定理、BASE理论、强、弱一致性、顺序、线性、因果、最终一致性)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!