之前我们已经详细讨论了如何使用BeautifulSoup这个强大的工具来解析HTML页面,另外还介绍了利用在线工具来抓取HTTP请求以获取数据的方法。在今天的学习中,我们将继续探讨另一种常见的网络爬虫技巧:XPath。XPath是一种用于定位和选择XML文档中特定部分的语言,虽然它最初是为XML设计的,但同样适用于HTML文档的解析。
HTML和XML有很多相似之处,比如标签、属性等,因此XPath同样可以在HTML文档中有效地定位元素。爬虫可以利用XPath表达式来指定需要提取的数据的位置,然后通过XPath解析器来解析HTML文档,从而提取所需的信息。
好的,我们不多说,直接开始今天的任务,爬取36kr的热榜新闻以及新闻搜索。
XPath爬虫
如果对XPath不熟悉也没关系,可以直接使用它,就能发现它与我们之前使用的BeautifulSoup有着相同的目的。只是在表达式和方法的使用上略有不同。在进行爬虫之前,我们可以先下载一个XPath工具。之前我们编写BeautifulSoup代码时,需要自行查找HTML代码中的标签并编写代码进行解析,这样很费眼。而在浏览器中可以使用插件工具来直接提取XPath元素。
XPath插件
有很多浏览器插件可供选择,我们只需直接获取一个即可。最重要的是,这些插件可以让我们在选择时轻松复制表达式,就像这样:
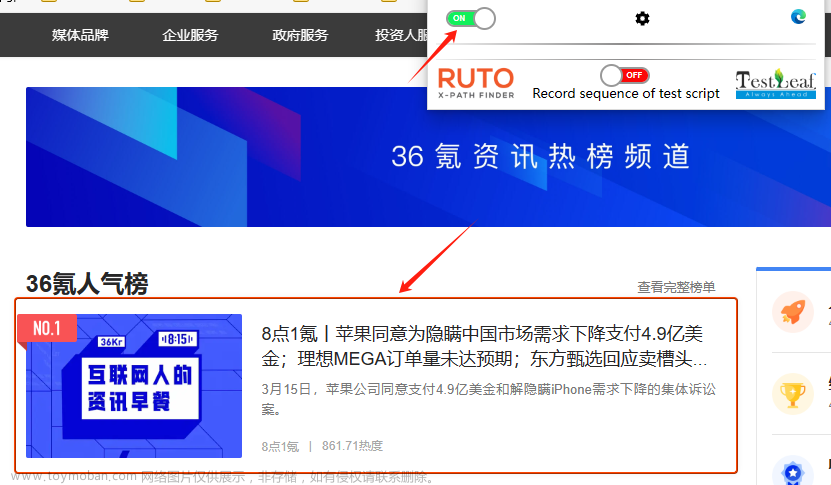
当我打开插件工具后,立即触发左键操作,从而开始显示红色框框,用户选择后,系统会呈现一系列XPath表达式供选择,用户只需选取适当的表达式即可。
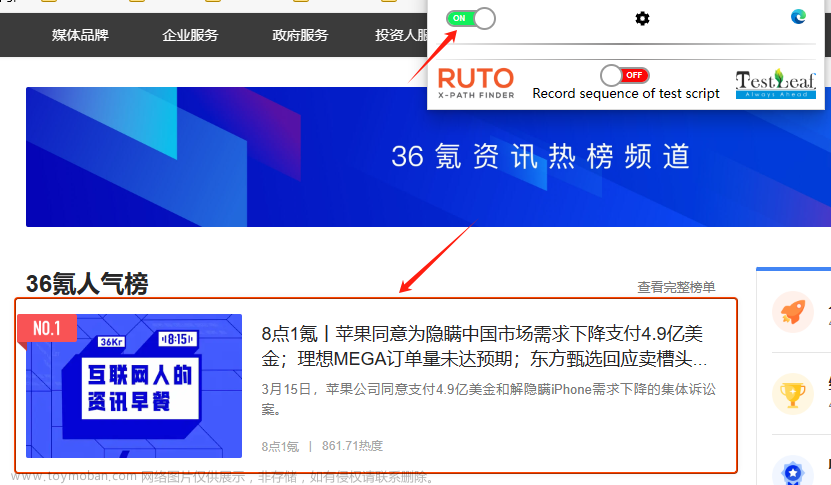
热榜新闻
会使用工具后,我们将继续进行数据爬取和页面信息解析。在此之前,需要安装一个新的依赖库lxml。以下是一个示例代码供参考:
from lxml import etree
import requests
hot_article_list = []
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36"
}
def get_hot_article():
url = 'https://36kr.com/hot-list/catalog'
response = requests.get(url=url,headers=headers)
# 获取的html内容是字节,将其转化为字符串
#使用etree进行解析
data = etree.HTML(response.text)
# 使用XPath定位元素
# 提取a标签的article-item-title文本数据以及url连接
article_titles = data.xpath("(//a[@class='article-item-title weight-bold'])")
article_desc = data.xpath("(//a[@class='article-item-description ellipsis-2'])")
if len(article_titles) == len(article_desc):
for article, desc in zip(article_titles, article_desc):
# 获取元素的链接(href 属性)
link = article.get('href')
# 获取元素的文本内容
title = article.text
desc = desc.text
hot_article_list.append({
"title":title,
"link":link,
"desc":desc
})
else:
print("未找到指定元素")
print(hot_article_list)
这段代码的功能是从36氪网站的热门文章列表中提取文章的标题、链接和描述信息,并将这些信息存储在一个列表中。其中,lxml库用于HTML解析,requests库用于发送HTTP请求。接着,定义了一个空列表hot_article_list,用于存储提取的文章信息。
踩个小坑
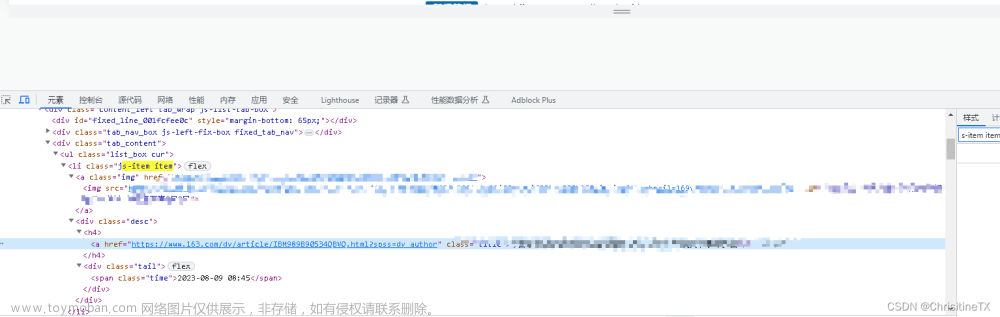
在前面已经成功提取了热门文章标题和链接,接下来通常应该开始逐个访问这些链接以查看新闻详情。然而,在发送请求获取单个URL链接时,却未能获得预期的新闻信息,出现了以下情况:
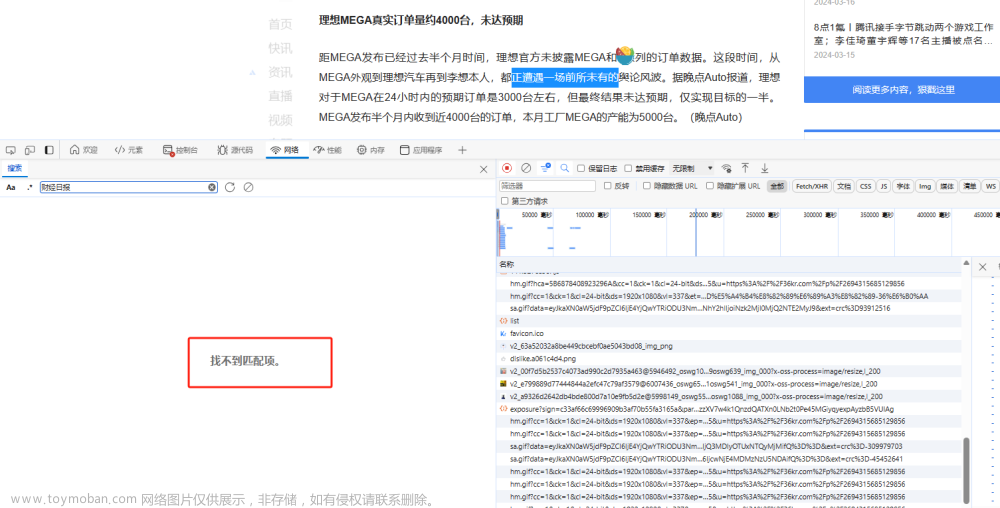
通常情况下,网页中的数据要么直接包含在静态HTML中,比如之前我们解析的美食菜谱等;要么是通过Ajax的HTTP请求获取的,比如我们尝试获取腾讯云社区的文章列表。通常,这些数据都可以在搜索中找到相应的匹配项。然而,我花了一个小时的时间仍未能成功获取所需信息。最初,我怀疑可能是因为网页中存在跳转页面传输数据,因此我特意使用抓包工具进行了下载,但令人失望的是,并没有发现相关数据。
因此,我又仔细检查了一遍静态HTML代码,并在代码末尾发现了一个奇怪之处——HTML页面的部分竟然被加密了。让我们来看看这段代码吧。

如果你对这些内容感到疑惑,建议再次在搜索框中输入相关关键字以查找更多信息。很可能存在解密函数。果然如此。我们接下来看下。

既然官方对数据进行了加密处理,显然是出于一定的考虑,其中可能包括对爬虫的防护等因素。鉴于此,我决定不再尝试对其进行解密操作,这个就这样吧。
信息搜索
36氪网站不仅提供了热门文章信息,还支持新闻搜索功能。让我们深入探讨一下搜索功能的实现方式。通常情况下,静态页面即可满足需求进行信息提取。但若希望获取更多数据,就需要通过发送ajax请求来实现。
接着看代码:
from lxml import etree
from urllib.parse import quote
import requests
def get_article_search(keyword):
qk = quote(keyword)
url = f'https://36kr.com/search/articles/{qk}'
response = requests.get(url=url,headers=headers)
# 获取的html内容是字节,将其转化为字符串
#使用etree进行解析
data = etree.HTML(response.text)
# 使用XPath定位元素
# 提取a标签的article-item-title文本数据以及url连接
article_detail = data.xpath("(//p[@class='title-wrapper ellipsis-2']//a)")
for a_tag in article_detail:
text = a_tag.xpath("string()").strip()
url = a_tag.get("href")
print("文本:", text)
print("URL连接:", url)
def get_article_url(keyword):
headers = {
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Content-Type': 'application/json',
'Cookie': 'Hm_lvt_713123c60a0e86982326bae1a51083e1=1710743069; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2218b40a4b8576e0-0508814adc1724-745d5774-2073600-18b40a4b858109a%22%2C%22%24device_id%22%3A%2218b40a4b8576e0-0508814adc1724-745d5774-2073600-18b40a4b858109a%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; Hm_lvt_1684191ccae0314c6254306a8333d090=1710743069; aliyungf_tc=9f944307bb330cb7a00e123533aad0ee8a0e932e77510b0782e3ea63cddc99cf; Hm_lpvt_713123c60a0e86982326bae1a51083e1=1710750569; Hm_lpvt_1684191ccae0314c6254306a8333d090=1710750569',
'Origin': 'https://36kr.com',
'Referer': 'https://36kr.com/',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-site',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0',
'sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Microsoft Edge";v="122"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
json_data = {
'partner_id': 'web',
'timestamp': 1710751467467,
'param': {
'searchType': 'article',
'searchWord': keyword,
'sort': 'score',
'pageSize': 20,
'pageEvent': 1,
'pageCallback': 'eyJmaXJzdElkIjo5NSwibGFzdElkIjo1MSwiZmlyc3RDcmVhdGVUaW1lIjo3NTU4MSwibGFzdENyZWF0ZVRpbWUiOjIzOTk3LCJsYXN0UGFyYW0iOiJ7XCJwcmVQYWdlXCI6MSxcIm5leHRQYWdlXCI6MixcInBhZ2VOb1wiOjEsXCJwYWdlU2l6ZVwiOjIwLFwidG90YWxQYWdlXCI6MTAsXCJ0b3RhbENvdW50XCI6MjAwfSJ9',
'siteId': 1,
'platformId': 2,
},
}
response = requests.post(
'https://gateway.36kr.com/api/mis/nav/search/resultbytype',
headers=headers,
json=json_data,
)
data = response.json()
for parsed_data in data['data']['itemList']:
widget_title = parsed_data['widgetTitle'].replace('<em>', '').replace('</em>', '')
print(widget_title)
widget_url = parsed_data['route']
print(widget_url)
get_article_search('OpenAI')
get_article_url('我要')
get_article_search 和 get_article_url。这两个函数都是用来从36氪网站上获取文章信息的。
-
get_article_search(keyword):- 首先,将关键词进行URL编码。
- 构建搜索URL并发送GET请求获取页面内容。
- 使用lxml库的etree模块解析HTML内容。
- 使用XPath定位元素,提取文章标题和URL连接。
-
get_article_url(keyword):- 函数中定义了请求头(headers)和请求体(json_data)。
- 发送POST请求到指定的API接口获取文章URL数据。
- 解析返回的JSON数据,提取文章标题和URL连接。
总结
在这篇文章中,我们深入学习了XPath作为一种常见的网络爬虫技巧。XPath是一种用于定位和选择XML文档中特定部分的语言,尽管最初是为XML设计的,但同样适用于HTML文档的解析。我们探讨了如何使用XPath来定位元素并提取所需信息。文章来源:https://www.toymoban.com/news/detail-841981.html
通过这篇文章的学习,我们对XPath的应用有了更深入的了解,也提升了我们在网络爬虫领域的技能。继续努力学习和实践,相信我们可以在爬虫技术上取得更大的进步!文章来源地址https://www.toymoban.com/news/detail-841981.html
到了这里,关于爬虫实战:探索XPath爬虫技巧之热榜新闻的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!