今日,分享编写Python爬虫程序来实现微博评论数据的下载。

具体步骤如下👇👇👇:
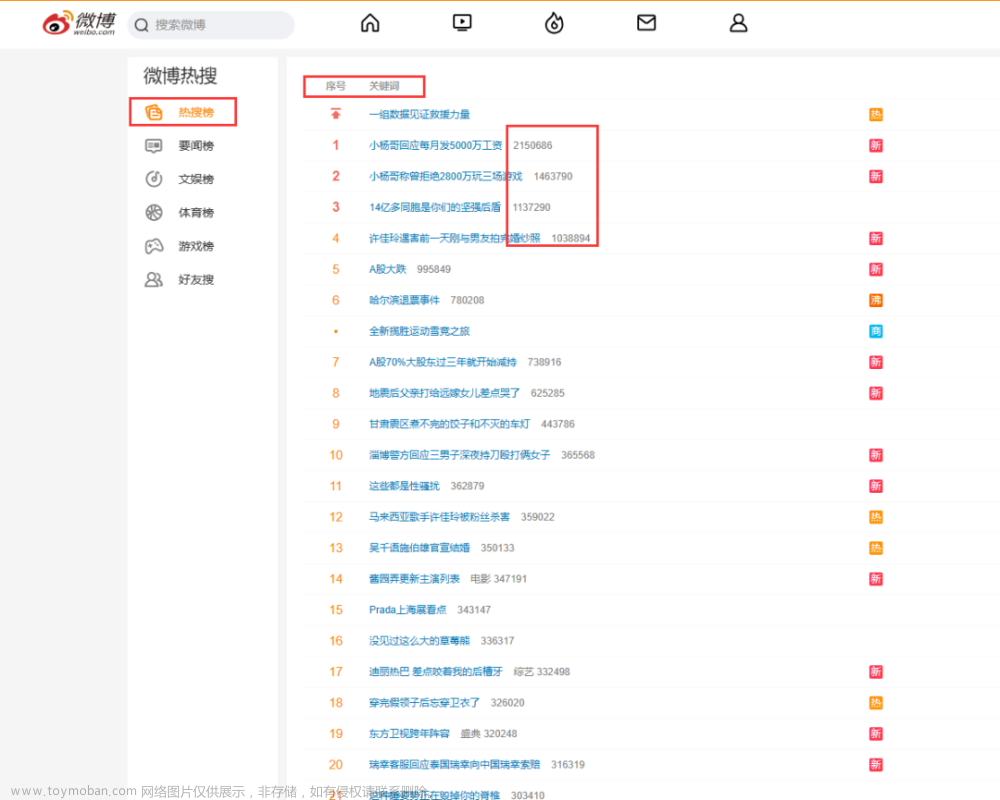
Step1:电脑访问手机端微博_https://m.weibo.cn/_
Step2:打开一条微博_https://m.weibo.cn/detail/4907031376694279_
Step3:URL地址中的_49070__31376694279_就是需要爬取的微博ID
Step4:将ID填写到_main_下即可,也支持同时填写多个
完整代码:
import os
import requests
import pandas as pd
import datetime
from time import sleep
import random
# from fake_useragent import UserAgent
import re
def trans_time(v_str):
"""转换GMT时间为标准格式"""
GMT_FORMAT = '%a %b %d %H:%M:%S +0800 %Y'
timeArray = datetime.datetime.strptime(v_str, GMT_FORMAT)
ret_time = timeArray.strftime("%Y-%m-%d %H:%M:%S")
return ret_time
def tran_gender(gender_tag):
"""转换性别"""
if gender_tag == 'm':
return '男'
elif gender_tag == 'f':
return '女'
else: # -1
return '未知'
def get_comments(v_weibo_ids, v_comment_file, v_max_page):
"""
爬取微博评论
:param v_weibo_id: 微博id组成的列表
:param v_comment_file: 保存文件名
:param v_max_page: 最大页数
:return: None
"""
for weibo_id in v_weibo_ids:
# 初始化max_id
max_id = '0'
# 爬取前n页,可任意修改
for page in range(1, v_max_page + 1):
wait_seconds = random.uniform(0, 1) # 等待时长秒
print('开始等待{}秒'.format(wait_seconds))
sleep(wait_seconds) # 随机等待
print('开始爬取第{}页'.format(page))
if page == 1: # 第一页,没有max_id参数
url = 'https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id_type=0'.format(weibo_id, weibo_id)
else: # 非第一页,需要max_id参数
if str(max_id) == '0': # 如果发现max_id为0,说明没有下一页了,break结束循环
print('max_id is 0, break now')
break
url = 'https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id_type=0&max_id={}'.format(weibo_id,
weibo_id,
max_id)
# 发送请求
# ua = UserAgent(verify_ssl=False)
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
# 如果cookie失效,会返回-100响应码
"cookie": "__bid_n=1855e52f83c12780664207; FEID=v10-766d48bf476a5b99a31684e6d4b74c98b4d133a2; __xaf_fpstarttimer__=1672634141361; __xaf_thstime__=1672634141910; __xaf_fptokentimer__=1672634142056; _T_WM=91010151027; SCF=AhqqhuU0eySfXjT2vmQ5faXpqgHtzG0tpXf6Jh1xOrIiSqjsMXmKh4wsNBFg5ejqRMTI93-xSbS-Uduk_s4NRK8.; SUB=_2A25O5c7uDeRhGedI4lIU8C3PwzyIHXVqKdKmrDV6PUJbktAKLUz1kW1NVoZ-2WIGRSgsp51DeFB9dxRhRboM7px_; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WhWcVXRXvfX3iep9.M98zpA5JpX5K-hUgL.Fo2c1K5fehe01h52dJLoIE2LxK.LBK.LB-eLxK-L1KeLBKH7wPxQdcRLxKnLB-qLBoBt; ALF=1678330814; FPTOKEN=p16283+PpnoduGibvvEpa7Jm1K1HU2NhkUXcqTuOwltTEKQJhsj3jOo/s/CWN8838ew7/ie6v2DLIYzTNLo40f3l05g4fFF+kjYdomw3o20ziaJMA4VJXMtzUBj6vAo3zxEa+LfqjEUYQuqn3G1gHwOdB2At9OvAubnkHHfZSzJJo0v+TLKcmjTLExJW/OjHZyhR9bRoWqV/1ENZHuxKvsn7tn+pgwC2n28Q/ez8zMNkj6X0huMuaBeNA8HoQ8FuWjoyrXps7wwbRbBv8z4mumRRoqiXEOSOsASflCjKw6gkfJJ5oHmoh1hx43ugVTZqxpYLivp8aCToqFu/clIex5bB2b0WQdp59i9E1KqEiwRN6jxPjhl7EKQlruQclvFYRExGOw5KMKGZy/0CNraMcw==|PfOWxrz13V2fvzp/rEoL/lSANYW4voaw2PHjpWZ/njY=|10|b67122b33a5e1ebb87032fafdc0126ba; XSRF-TOKEN=eceae9; WEIBOCN_FROM=1110006030; mweibo_short_token=87f071037d; MLOGIN=1; M_WEIBOCN_PARAMS=oid=4865363672566456&luicode=10000011&lfid=102803&uicode=20000061&fid=4865363672566456",
"accept": "application/json, text/plain, */*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7",
"referer": "https://m.weibo.cn/detail/{}".format(weibo_id),
"x-requested-with": "XMLHttpRequest",
"mweibo-pwa": '1',
}
r = requests.get(url, headers=headers) # 发送请求
print(r.status_code) # 查看响应码
# print(r.json()) # 查看响应内容
try:
max_id = r.json()['data']['max_id'] # 获取max_id给下页请求用
datas = r.json()['data']['data']
except Exception as e:
print('excepted: ' + str(e))
continue
page_list = [] # 评论页码
id_list = [] # 评论id
text_list = [] # 评论内容
time_list = [] # 评论时间
like_count_list = [] # 评论点赞数
source_list = [] # 评论者IP归属地
user_name_list = [] # 评论者姓名
user_id_list = [] # 评论者id
user_gender_list = [] # 评论者性别
follow_count_list = [] # 评论者关注数
followers_count_list = [] # 评论者粉丝数
for data in datas:
page_list.append(page)
id_list.append(data['id'])
dr = re.compile(r'<[^>]+>', re.S) # 用正则表达式清洗评论数据
text2 = dr.sub('', data['text'])
text_list.append(text2) # 评论内容
time_list.append(trans_time(v_str=data['created_at'])) # 评论时间
like_count_list.append(data['like_count']) # 评论点赞数
source_list.append(data['source']) # 评论者IP归属地
user_name_list.append(data['user']['screen_name']) # 评论者姓名
user_id_list.append(data['user']['id']) # 评论者id
user_gender_list.append(tran_gender(data['user']['gender'])) # 评论者性别
follow_count_list.append(data['user']['follow_count']) # 评论者关注数
followers_count_list.append(data['user']['followers_count']) # 评论者粉丝数
df = pd.DataFrame(
{
'max_id': max_id,
'微博id': [weibo_id] * len(time_list),
'评论页码': page_list,
'评论id': id_list,
'评论时间': time_list,
'评论点赞数': like_count_list,
'评论者IP归属地': source_list,
'评论者姓名': user_name_list,
'评论者id': user_id_list,
'评论者性别': user_gender_list,
'评论者关注数': follow_count_list,
'评论者粉丝数': followers_count_list,
'评论内容': text_list,
}
)
if os.path.exists(v_comment_file): # 如果文件存在,不再设置表头
header = False
else: # 否则,设置csv文件表头
header = True
# 保存csv文件
df.to_csv(v_comment_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
print('结果保存成功:{}'.format(v_comment_file))
if __name__ == '__main__':
weibo_id_list = ['4907031376694279', ] # 指定爬取微博id,可填写多个id
max_page = 1 # 爬取最大页数
comment_file = '数据评论.csv'
# 如果结果文件存在,先删除
if os.path.exists(comment_file):
os.remove(comment_file)
# 爬取评论
get_comments(v_weibo_ids=weibo_id_list, v_comment_file=comment_file, v_max_page=max_page)
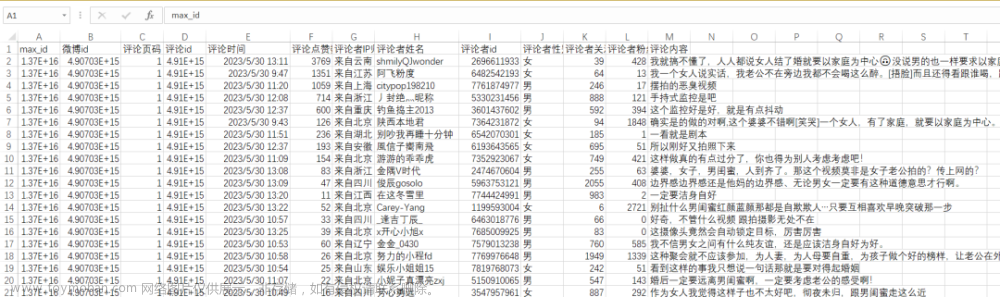
爬取结果:
感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。
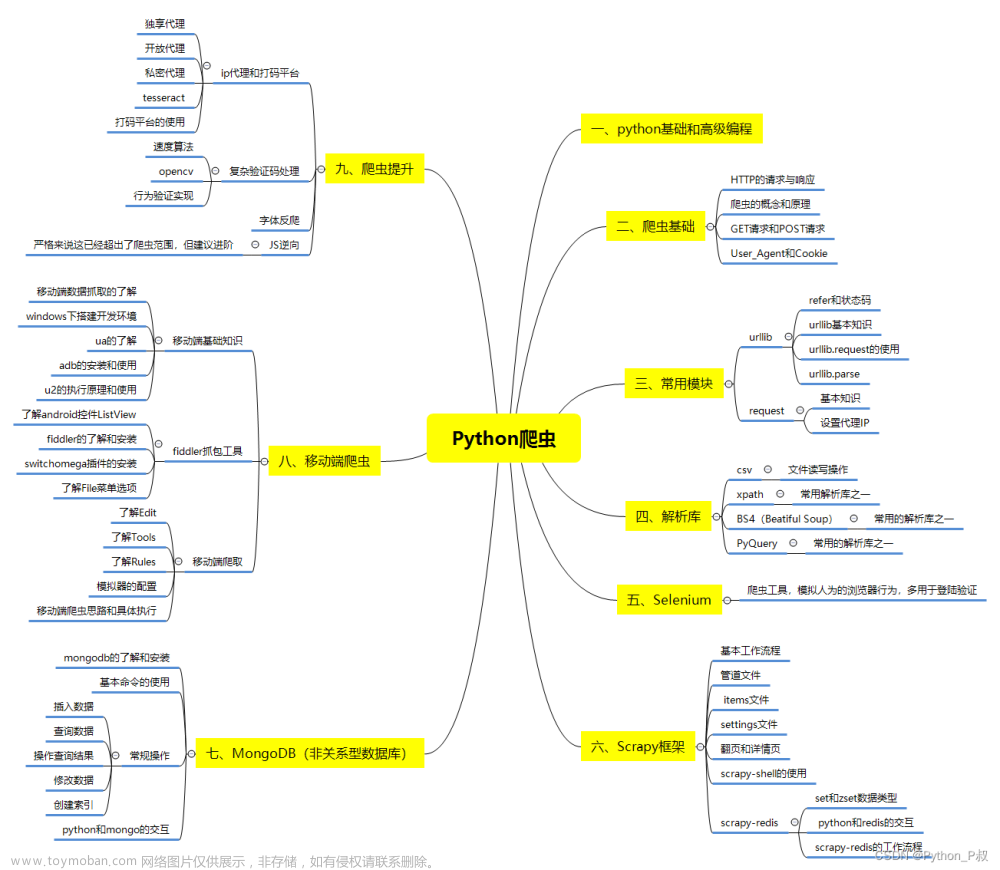
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典
 文章来源:https://www.toymoban.com/news/detail-842172.html
文章来源:https://www.toymoban.com/news/detail-842172.html
 文章来源地址https://www.toymoban.com/news/detail-842172.html
文章来源地址https://www.toymoban.com/news/detail-842172.html
简历模板
 若有侵权,请联系删除
若有侵权,请联系删除 到了这里,关于Python爬虫—爬取微博评论数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!