## 准备工作
### 1、安装selenium
```
pip install selenium
```
### 2、安装浏览器driver(以Edge浏览器为例)
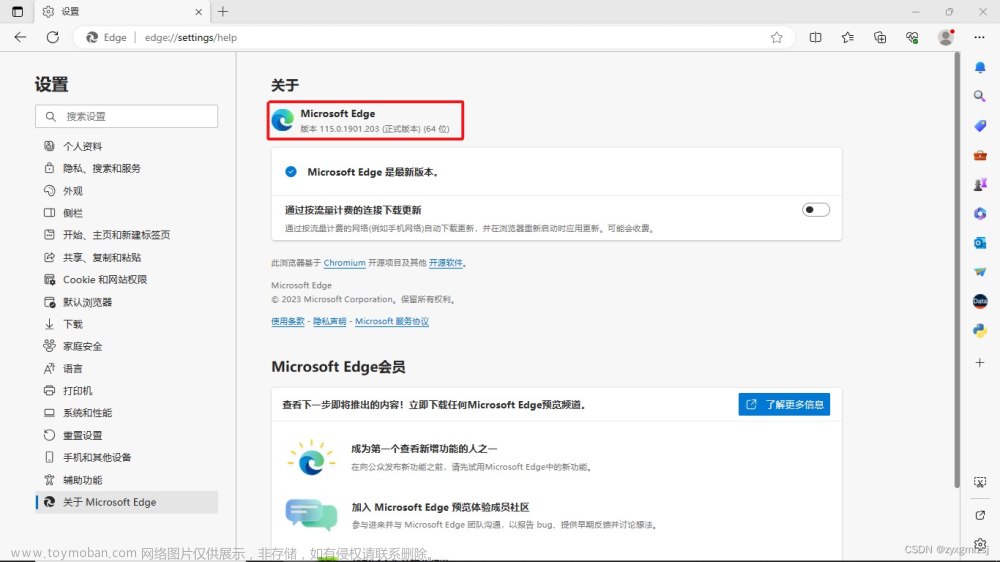
* 打开edge浏览器,然后“帮助和反馈”->“关于Microsoft Edge”,查看浏览器版本,根据版本号下载driver

* 打开网站[url](https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/) ,根据浏览器版本下载对应的driver

* 将下载的driver解压后放在爬虫脚本同级目录下

### 3、需要安装的其他库
```
# 网络连接的库
pip install requests
# 处理标签数据的库
pip install beautifulsoup4
# 处理excel写入的库
pip install xlwt
```
### 4、分析网页和信息处理逻辑
#### 分析网页
* 要爬取网页是[研招网官网硕士专业目录](https://yz.chsi.com.cn/zsml/queryAction.do),如下图所示。

* 可以看到信息主要是五个查询字段,分别是招生单位、所在地、研究生院、自划线院校、博士点,和两个必选字段分别是专业门类和专业领域。必须选择专业门类和专业领域才能进行查询。

* 打开页面的检查页面,可以看到很多个jsp的请求,getMI.jsp是学科门类下拉列表的数据,getZy.jsp是专业领域下拉列表的数据,getSs.jsp是所在地的数据。

* 同时,网页数据还进行了分页处理,所以在爬取数据的时候也需要考虑到这一点。

#### 处理思路
经过对网页的简单的分析,需要先选中“学科门类”和“专业领域”,然后点击“查询”按钮,最后不断点击下一页按钮来获取网页源代码,在通过beautifulsoup对网页源代码进行信息提取,最后将提取的信息写入excel。
## 编写代码
### 方法解析
#### getMajor()方法
```python
def getMajor():
url_1 = "https://yz.chsi.com.cn/zsml/pages/getMl.jsp"
url_2 = "https://yz.chsi.com.cn/zsml/pages/getZy.jsp"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36',
'Connection': 'close'} # CLOSE: 在header中不使用持久连接
# 查询期刊名称及其他信息
print("------------开始爬取-----------")
# response = requests.post(url, headers=headers, data=payload, cookies=cookie)
response = requests.post(url_1, headers=headers)
result = response.json()
zyxw = {'mc':'专业学位','dm':'zyxw'}
result.insert(0,zyxw)
datas = []
payload = {
'mldm': '01'
}
for item in result:
payload['mldm'] = item['dm']
response = requests.post(url_2, headers=headers, data=payload)
data = response.json()
datas.append(data)
return result,datas
```
* 这个方法主要就是获取网页中两个下拉框的数据,根据分析网页得知这两个数据都是通过两个jsp拿到的
* 值得注意的是直接获取第一个下拉框的数据(也就是https://yz.chsi.com.cn/zsml/pages/getMl.jsp),是没有专业硕士这一项的,所以我们这里手动加入并把它插入到result的第一项(因为在下拉项的第一项也是专业硕士)。

* 不同门类下的专业领域数据需要传入参数才能获取,这里需要传入的payload中‘mldm’属性,这项属性也就是门类数据中的‘dm’属性,所以我们这里根据门类数据中的‘dm’属性分别获取每个门类下的不同专业领域信息。

#### find_page()方法
```python
def find_page(data_first,data_second):
options = webdriver.ChromeOptions()
# 解决DevToolsActivePort文件不存在的报错
options.add_argument('--no-sandbox')
# 指定浏览器分辨率
options.add_argument('window-size=1600x900')
# 谷歌文档提到需要加上这个属性来规避bug
options.add_argument('--disable-gpu')
# 隐藏滚动条, 应对一些特殊页面
options.add_argument('--hide-scrollbars')
# 不加载图片, 提升速度
options.add_argument('blink-settings=imagesEnabled=false')
# 浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
options.add_argument('--headless')
# 初始化一个driver,driver的路径选择的是相对路径,不行就写绝对路径
# edge
driver = webdriver.Edge()
# chrome
# driver = webdriver.Chrome()
# 网页主页面请求路径
url = "https://yz.chsi.com.cn/zsml/queryAction.do"
driver.get(url)
# 学科门类
s1_len = len(data_first)
print(s1_len)
allData = []
for i in range(s1_len+1):
# 给出加载时间
time.sleep(1)
s1 = Select(driver.find_element_by_name("mldm"))
if i == 0:
continue
s1.select_by_index(i)
name_one = data_first[i-1]['mc']
# 学科类别
s2_len = len(data_second[i-1])
print(s2_len)
pageData = []
name_list = data_second[i-1]
for j in range(s2_len+1):
s2 = Select(driver.find_element_by_name("yjxkdm"))
if j == 0:
continue
s2.select_by_index(j)
print(i,j)
name_two = data_second[i-1][j-1]['mc']
# 查询按钮
s3 = driver.find_element_by_name("button")
s3.click()
tablename = name_one + '-' + name_two
print(tablename)
pages = []
# 跳页
for l in range(50):
currentPage = driver.page_source
pages.append(currentPage)
# 下一页
s4 = driver.find_elements_by_class_name("lip")
# 是否存在box直接跳页
s5 = driver.find_elements_by_class_name("lip-input-box")
time.sleep(1)
if len(s5) == 0:
s4[-1].click()
else:
s4[-2].click()
nextPage = driver.page_source
# 当前页和下一页一致跳出循环
if nextPage == currentPage:
break
pageData.append(pages)
allData.append(pageData)
# 将html交给beautifulsoup,每个大类
getPage(allData,data_first,data_second)
# 退出浏览器
driver.close()
driver.quit()
```
* 这个方法主要是通过selenium库模拟网页的操作,获取网页源代码然后将这些网页源代码交给beautifulsoup库处理,从而提取数据。
* 首先,我们查看网页源代码,发现两个下拉选择框的name属性分别是mldm和yjxkdm,查询按钮的name属性是button;获取这些元素对象进行模拟选择和查询。

* 值得注意的点是这里遍历的遍历是从1开始且结束于len+1的,这是因为网页中下拉选项中的第一项是提示文字,并不能查询到实际的信息。

* 另一个值得注意的点是跳页的问题,我们找到下一页的按钮,对它进行模拟点击,这里我们循环了50次,这里为什么是50次?因为每页有30条数据,所以总体的数据大概有1500,而全国招收硕士的院校有863个,所以这个冗余是完全足够的。

* 跳出循环的语句如下,逻辑是“当前页和下一页一致跳出循环”就说明已经到最后一页啦,就跳出循环,避免无效点击。
```python
# 当前页和下一页一致跳出循环
if nextPage == currentPage:
break
```
#### getPage()方法
```python
# name_one为表名,name_two为子表名
def getPage(allData,data_first,data_second):
all_data = []
t = -1
for pageData in allData:
t = t + 1
l = -1
for pages in pageData:
l = l + 1
for page in pages:
# 解析源代码
soup = BeautifulSoup(page, 'html.parser')
tbody = soup.find('tbody')
# print(tbody)
for item in tbody.children:
if isinstance(item, bs4.element.Tag):
k = 0
tdItem = []
tdItem.append(data_first[t]['mc'])
tdItem.append(data_second[t][l]['dm']+data_second[t][l]['mc'])
for td in item.children:
if isinstance(td, bs4.element.Tag):
if k == 0 or k == 1:
s = td.text.replace("\n","")
tdItem.append(s)
else:
ii = td.find('i')
if ii:
tdItem.append('√')
else:
tdItem.append('×')
k = k + 1
all_data.append(tdItem)
write_excel(all_data)
```
* 这个方法是将获取的所有源代码交给beautifulsoup进行处理,获取我们需要的信息。
* 下面的图是部分源码的信息,可以看到所有信息都在tbody标签下的tr标签下,对于前两项(招生单位和所在地)自己获取标签的文本信息,对于后三项我们采用找“i”标签的方式来获取信息,如果存在“i”标签,我们标记信息为“√”,否则标记为“错”。

* 此外,还需要将选择的属性值拼接到数据中,以实现较好地写入excel中。
```python
tdItem.append(data_first[t]['mc'])
tdItem.append(data_second[t][l]['dm']+data_second[t][l]['mc'])
```
#### write_excel()方法
```python
def write_excel(datas):
workbook = xlwt.Workbook(encoding='utf-8')
booksheet = workbook.add_sheet("学科门类", cell_overwrite_ok=False)
# 添加表头
booksheet.write(0, 0, "学科门类")
booksheet.write(0, 1, "学科专业")
booksheet.write(0, 2, "招生单位")
booksheet.write(0, 3, "所在地")
booksheet.write(0, 4, "是否有研究生院")
booksheet.write(0, 5, "是否是自划线院校")
booksheet.write(0, 6, "是否有博士点")
for i, row in enumerate(datas):
for j, col in enumerate(row):
booksheet.write(i + 1, j, col)
workbook.save('E:\\dataSet\\' + "数据" + '.xls')
```
* 这个方法比较简单,将获取到的数据写入excel中,先写表头信息,然后写入数据,保存到excel里面
### 全代码展示
#### 1、根据专业门类和专业领域写入多个excel文件
```python
#!/opt/python39/bin/python3
# encoding=utf-8
import time
from selenium import webdriver
import xlwt
from bs4 import BeautifulSoup
import bs4
import requests
# 创建chrome参数对象
from selenium.webdriver.support.select import Select
def find_page(data_first,data_second):
options = webdriver.ChromeOptions()
# 解决DevToolsActivePort文件不存在的报错
options.add_argument('--no-sandbox')
# 指定浏览器分辨率
options.add_argument('window-size=1600x900')
# 谷歌文档提到需要加上这个属性来规避bug
options.add_argument('--disable-gpu')
# 隐藏滚动条, 应对一些特殊页面
options.add_argument('--hide-scrollbars')
# 不加载图片, 提升速度
options.add_argument('blink-settings=imagesEnabled=false')
# 浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
options.add_argument('--headless')
# 初始化一个driver,driver的路径选择的是相对路径,不行就写绝对路径
# edge
driver = webdriver.Edge()
# chrome
# driver = webdriver.Chrome()
# 网页主页面请求路径
url = "https://yz.chsi.com.cn/zsml/queryAction.do"
driver.get(url)
# 学科门类
s1_len = len(data_first)
print(s1_len)
for i in range(s1_len+1):
# 给出加载时间
time.sleep(1)
s1 = Select(driver.find_element_by_name("mldm"))
if i <= 4:
continue
s1.select_by_index(i)
name_one = data_first[i-1]['mc']
# 学科类别
s2_len = len(data_second[i-1])
print(s2_len)
pageData = []
name_list = data_second[i-1]
for j in range(s2_len+1):
s2 = Select(driver.find_element_by_name("yjxkdm"))
if j == 0:
continue
s2.select_by_index(j)
print(i,j)
name_two = data_second[i-1][j-1]['mc']
# 查询按钮
s3 = driver.find_element_by_name("button")
s3.click()
tablename = name_one + '-' + name_two
print(tablename)
pages = []
# 跳页
for l in range(50):
currentPage = driver.page_source
pages.append(currentPage)
# 下一页
s4 = driver.find_elements_by_class_name("lip")
# 是否存在box直接跳页
s5 = driver.find_elements_by_class_name("lip-input-box")
time.sleep(1)
if len(s5) == 0:
s4[-1].click()
else:
s4[-2].click()
nextPage = driver.page_source
# 当前页和下一页一致跳出循环
if nextPage == currentPage:
break
pageData.append(pages)
# 将html交给beautifulsoup,每个大类
getPage(pageData,name_one,name_list)
# 退出浏览器
driver.close()
driver.quit()
# name_one为表名,name_two为子表名
def getPage(pageData,name_one,name_list):
datas = []
for pages in pageData:
data = []
for page in pages:
# 解析源代码
soup = BeautifulSoup(page, 'html.parser')
tbody = soup.find('tbody')
# print(tbody)
for item in tbody.children:
if isinstance(item, bs4.element.Tag):
k = 0
tdItem = []
for td in item.children:
if isinstance(td, bs4.element.Tag):
if k == 0 or k == 1:
s = td.text.replace("\n","")
tdItem.append(s)
else:
ii = td.find('i')
if ii:
tdItem.append('是')
else:
tdItem.append('否')
k = k + 1
data.append(tdItem)
print(data)
datas.append(data)
write_excel(datas,name_one,name_list)
def getMajor():
url_1 = "https://yz.chsi.com.cn/zsml/pages/getMl.jsp"
url_2 = "https://yz.chsi.com.cn/zsml/pages/getZy.jsp"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36',
'Connection': 'close'} # CLOSE: 在header中不使用持久连接
# 查询期刊名称及其他信息
print(":------------开始爬取-----------")
# response = requests.post(url, headers=headers, data=payload, cookies=cookie)
response = requests.post(url_1, headers=headers)
result = response.json()
zyxw = {'mc':'专业学位','dm':'zyxw'}
result.insert(0,zyxw)
datas = []
payload = {
'mldm': '01'
}
for item in result:
payload['mldm'] = item['dm']
response = requests.post(url_2, headers=headers, data=payload)
data = response.json()
datas.append(data)
return result,datas
def write_excel(datas,name_one,name_list):
workbook = xlwt.Workbook(encoding='utf-8')
k = 0
print(datas)
for item in name_list:
name = item['mc']
dm = item['dm']
if name == '':
name = dm
# 写入为excel文件
booksheet = workbook.add_sheet(name, cell_overwrite_ok=False)
# 添加表头
booksheet.write(0, 0, "招生单位")
booksheet.write(0, 1, "所在地")
booksheet.write(0, 2, "是否有研究生院")
booksheet.write(0, 3, "是否是自划线院校")
booksheet.write(0, 4, "是否有博士点")
for i, row in enumerate(datas[k]):
for j, col in enumerate(row):
booksheet.write(i + 1, j, col)
# 第k个数据
k = k+1
workbook.save('E:\\dataSet\\' + name_one + '.xls')
data_first,data_second = getMajor()
find_page(data_first,data_second)
```
#### 2、将所有数据写入同一个excel文件
```python
#!/opt/python39/bin/python3
# encoding=utf-8
import time
from selenium import webdriver
import xlwt
from bs4 import BeautifulSoup
import bs4
import requests
# 创建chrome参数对象
from selenium.webdriver.support.select import Select
def find_page(data_first,data_second):
options = webdriver.ChromeOptions()
# 解决DevToolsActivePort文件不存在的报错
options.add_argument('--no-sandbox')
# 指定浏览器分辨率
options.add_argument('window-size=1600x900')
# 谷歌文档提到需要加上这个属性来规避bug
options.add_argument('--disable-gpu')
# 隐藏滚动条, 应对一些特殊页面
options.add_argument('--hide-scrollbars')
# 不加载图片, 提升速度
options.add_argument('blink-settings=imagesEnabled=false')
# 浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
options.add_argument('--headless')
# 初始化一个driver,driver的路径选择的是相对路径,不行就写绝对路径
# edge
driver = webdriver.Edge()
# chrome
# driver = webdriver.Chrome()
# 网页主页面请求路径
url = "https://yz.chsi.com.cn/zsml/queryAction.do"
driver.get(url)
# 学科门类
s1_len = len(data_first)
print(s1_len)
allData = []
for i in range(s1_len+1):
# 给出加载时间
time.sleep(1)
s1 = Select(driver.find_element_by_name("mldm"))
if i == 0:
continue
s1.select_by_index(i)
name_one = data_first[i-1]['mc']
# 学科类别
s2_len = len(data_second[i-1])
print(s2_len)
pageData = []
name_list = data_second[i-1]
for j in range(s2_len+1):
s2 = Select(driver.find_element_by_name("yjxkdm"))
if j == 0:
continue
s2.select_by_index(j)
print(i,j)
name_two = data_second[i-1][j-1]['mc']
# 查询按钮
s3 = driver.find_element_by_name("button")
s3.click()
tablename = name_one + '-' + name_two
print(tablename)
pages = []
# 跳页
for l in range(50):
currentPage = driver.page_source
pages.append(currentPage)
# 下一页
s4 = driver.find_elements_by_class_name("lip")
# 是否存在box直接跳页
s5 = driver.find_elements_by_class_name("lip-input-box")
time.sleep(1)
if len(s5) == 0:
s4[-1].click()
else:
s4[-2].click()
nextPage = driver.page_source
# 当前页和下一页一致跳出循环
if nextPage == currentPage:
break
pageData.append(pages)
allData.append(pageData)
# 将html交给beautifulsoup,每个大类
getPage(allData,data_first,data_second)
# 退出浏览器
driver.close()
driver.quit()
# name_one为表名,name_two为子表名
def getPage(allData,data_first,data_second):
all_data = []
t = -1
for pageData in allData:
t = t + 1
l = -1
for pages in pageData:
l = l + 1
for page in pages:
# 解析源代码
soup = BeautifulSoup(page, 'html.parser')
tbody = soup.find('tbody')
# print(tbody)
for item in tbody.children:
if isinstance(item, bs4.element.Tag):
k = 0
tdItem = []
tdItem.append(data_first[t]['mc'])
tdItem.append(data_second[t][l]['dm']+data_second[t][l]['mc'])
for td in item.children:
if isinstance(td, bs4.element.Tag):
if k == 0 or k == 1:
s = td.text.replace("\n","")
tdItem.append(s)
else:
ii = td.find('i')
if ii:
tdItem.append('√')
else:
tdItem.append('×')
k = k + 1
all_data.append(tdItem)
write_excel(all_data)
def getMajor():
url_1 = "https://yz.chsi.com.cn/zsml/pages/getMl.jsp"
url_2 = "https://yz.chsi.com.cn/zsml/pages/getZy.jsp"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36',
'Connection': 'close'} # CLOSE: 在header中不使用持久连接
# 查询期刊名称及其他信息
print("------------开始爬取-----------")
# response = requests.post(url, headers=headers, data=payload, cookies=cookie)
response = requests.post(url_1, headers=headers)
result = response.json()
zyxw = {'mc':'专业学位','dm':'zyxw'}
result.insert(0,zyxw)
datas = []
payload = {
'mldm': '01'
}
for item in result:
payload['mldm'] = item['dm']
response = requests.post(url_2, headers=headers, data=payload)
data = response.json()
datas.append(data)
return result,datas
def write_excel(datas):
workbook = xlwt.Workbook(encoding='utf-8')
booksheet = workbook.add_sheet("学科门类", cell_overwrite_ok=False)
# 添加表头
booksheet.write(0, 0, "学科门类")
booksheet.write(0, 1, "学科专业")
booksheet.write(0, 2, "招生单位")
booksheet.write(0, 3, "所在地")
booksheet.write(0, 4, "是否有研究生院")
booksheet.write(0, 5, "是否是自划线院校")
booksheet.write(0, 6, "是否有博士点")
for i, row in enumerate(datas):
for j, col in enumerate(row):
booksheet.write(i + 1, j, col)
workbook.save('E:\\dataSet\\' + "数据" + '.xls')
data_first,data_second = getMajor()
print(data_first)
print(data_second)
find_page(data_first,data_second)
```
## 结果

生成一个表的结果:

生成多个表的结果: 文章来源:https://www.toymoban.com/news/detail-842190.html
文章来源地址https://www.toymoban.com/news/detail-842190.html
到了这里,关于selenium+beautifulsoup数据爬取的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!