目录
一 数据建模概述
二 构建数据仓库项目应该设计哪些模型表?
三 数据仓库项目的模型表应该如何设计?
三 总结
在开始学习之前请先思考两个问题?在你的脑海里对这两个问题是有已经有了清晰的答案?
-
构建数据仓库项目应该设计哪些模型表?
-
数据仓库项目的模型表应该如何设计?
一 数据建模概述
数据建模在数据仓库构建中扮演着至关重要的角色,其重要性远不仅限于为数据提供一个结构化的容器。数据建模是将业务需求转化为可操作数据结构的过程,其重要性体现在多个方面:
首先,数据建模有助于深入理解业务。通过与业务团队密切合作,数据建模者能够捕捉到业务中的关键概念、实体、关系和规则。这种深刻理解是构建数据仓库的基础,确保数据仓库能够真实反映业务运作的本质,满足用户的需求。
其次,数据建模为数据仓库提供了一种清晰、可维护的结构。通过采用维度模型等建模方法,数据仓库能够以业务为中心进行组织,使得数据的组织结构更加直观,易于理解。这不仅有助于用户更轻松地查询和分析数据,也为数据仓库的维护和演化提供了方便。
另外,数据建模对于数据的质量和一致性至关重要。通过定义清晰的关系和规范,数据建模可以帮助识别和纠正潜在的数据质量问题。在数据仓库中,质量和一致性对于可信度和决策的准确性有着直接的影响。
此外,数据建模为数据仓库提供了标准化和可重复的设计模式。这种标准化简化了数据仓库的开发流程,降低了系统的复杂性,提高了数据仓库的可维护性和扩展性。
在这里,笔者从数据仓库建模的两个核心问题出发概述Kimball架构下的数据仓库构建过程。
二 构建数据仓库项目应该设计哪些模型表?
在构建数据仓库项目时,设计核心结构的模型表是至关重要的。为了解决这一挑战,我们采用了Kimball模型设计过程,通过以下问题和思路来逐步解释:
问题1:如何确定数据仓库的维度表?
通过对业务流程的梳理,我们借助有报表、与业务人员的沟通以及原始数据库中的事件类表等方式,识别了有价值的维度表。在设计这些表时,我们遵循Kimball维度设计理论,注意处理代理键、维度层级、缓慢变化维、多值维度等维度设计技巧。
问题2:如何确定数据仓库的明细事实表?
首先,我们介绍了两个概念:业务流和数据流。通过深入了解业务流,我们能够确定主要业务过程,即不可再分的最小操作单位。这些业务过程的确定依赖于充分的业务调研,而这个过程建议有业务专家的积极参与。业务调研结果确定了需要建模的业务过程,为接下来的事实表设计提供了基础。
数据探查是下一步的关键,通过探查数据源,我们能够明确每个业务过程对应的原始业务表的位置。通过业务调研和数据探查,我们可以确定数据仓库中可能需要建立的事实表。这样的设计方法使得数据仓库更贴近业务需求,为企业提供更准确、有价值的决策支持。
在业务调研和数据探查完成之后,我们就可以根据我们前期工作获取到的信息进行数仓模型结构的设计工作了。下面以交易业务为例进行数仓设计流程介绍,如下图所示:
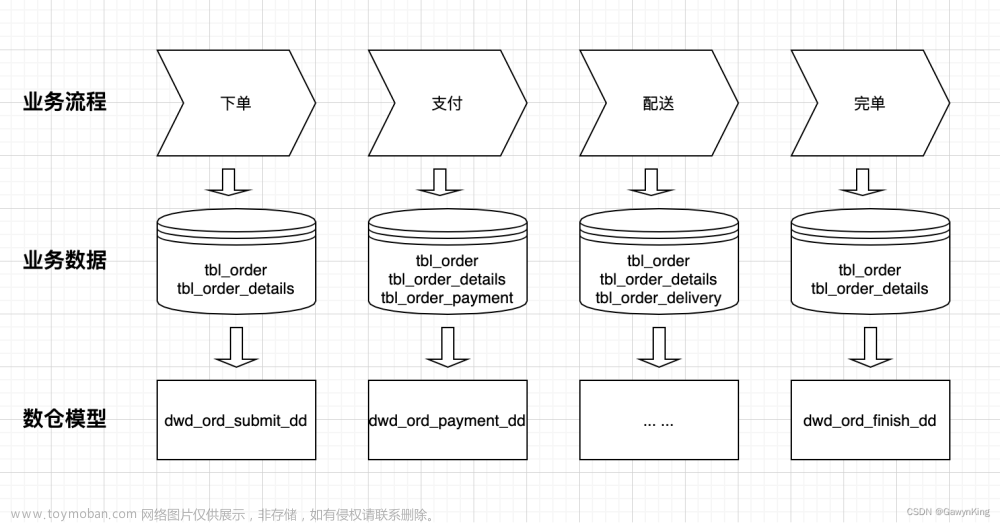
业务调研:首先数理业务流程,交易域核心业务流程有下单-支付-配送-完单四个流程,如上图业务流程所示;
数据探查:其次找到业务流程中关键过程点对应的原始数据表,如上图业务数据所示;
数仓建模:最后,根据我们调研到的业务流程和业务数据情况,设计数仓模型表,如上图所示,有提单事实表(dwd_ord_submit_dd)、支付事实表(dwd_ord_payment_dd)和完单事实表(dwd_ord_finish_dd),其中配送阶段又有很多流程,因此这里先忽略不考虑,再进行订单履约数据建设时进行统一设计。
三 数据仓库项目的模型表应该如何设计?
下面我们进入单表模型设计阶段,在进行维度模型建模时,采用以下四个关键步骤,这也是Kimball架构建模的核心步骤,确保系统性而有条理地构建数据仓库核心结构:
-
选择业务过程: 首先,深入了解业务流程,明确企业中的核心业务过程。这可能包括销售、采购、物流等关键领域。业务过程的选择应该基于对企业运作的全面理解,确保捕捉到业务的本质和重要流程。
-
确认粒度: 一旦业务过程确定,就需要明确事实表的粒度,即事实表记录的最小可度量单元。这一步关键,因为它决定了事实表中记录的信息细节,直接影响到数据仓库的性能和可用性。合理的粒度确保了事实表能够满足业务需求。
-
确认维度: 在业务流程和粒度确定的基础上,明确维度表,即用于描述业务过程的特定维度。维度包括时间、地点、产品、客户等,直接影响到数据的分析和查询能力。维度的选择要根据业务需求,确保反映业务的全貌,同时避免冗余和不必要的复杂性。
-
确认事实: 最后,确定与业务过程相关的事实,即数值型的业务度量。这可能包括销售额、库存量、运输成本等。确认事实表中的事实是建立数据仓库的核心,因为它们直接关联到业务的关键指标,为企业提供了数据支持。
通过遵循以上四个步骤,能够系统性地构建起维度模型,确保数据仓库能够有效地捕捉并反映业务的本质,为企业决策提供有力的数据支持。文章来源:https://www.toymoban.com/news/detail-842363.html
三 总结
以上我们对数仓建模的两个核心问题进行了描述,本文侧重是流程层面的介绍,对于维度建模中设计到的维度表建模技术和事实表建模技术并没有过多介绍,但对于技术细节的把控能力对于数仓建模质量也是至关重要的,那么其他内容我们后续慢慢介绍。相信笔者本文的介绍和示例对于大部分同学而言都是有所帮助的。文章来源地址https://www.toymoban.com/news/detail-842363.html
到了这里,关于Kimball维度模型之构建数据仓库流程解析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!








