1、Hadoop集群工作时启动哪些进程?它们有哪些作用?
- NameNode:NameNode是Hadoop分布式文件系统的关键组件之一。它负责管理整个文件系统的元数据,包括文件和目录的命名空间、文件的块信息、权限等。它还负责协调数据块的读写操作,并提供对文件系统的访问控制。
- DataNode:DataNode是HDFS的另一个关键组件,它存储实际的数据块。每个DataNode负责存储和管理本地节点的数据块,并定期向NameNode报告其存储的数据块信息。
- SecondaryNameNode:SecondaryNameNode并不是NameNode的备份,而是协助NameNode的辅助节点。它定期从NameNode获取文件系统的快照,并将其合并到新的文件系统编辑日志中。这样可以减少NameNode故障恢复的时间。
- ResourceManager:ResourceManager是Hadoop集群的资源管理器,负责协调和管理集群中的资源分配。它接收客户端的应用程序提交请求,并决定如何为这些应用程序分配资源。ResourceManager还负责监控集群中各个节点的健康状况。
- NodeManager:NodeManager是每个集群节点上的资源管理器,负责管理该节点上的资源使用情况。它接收来自ResourceManager的指令,并根据指令启动、监控和停止容器,以管理节点上的应用程序。
- JobHistoryServer:JobHistoryServe负责存储和管理作业历史信息。它接收来自ResourceManager的作业历史记录,并为用户提供查询和浏览作业历史的界面。
2、Hadoop在集群计算的时候,什么是集群的主要瓶颈?
- 网络带宽:大数据集群中的节点通常通过网络进行数据通信和传输。如果网络带宽不足,会导致数据传输速度慢,从而影响整个集群的计算性能。
- 存储性能:Hadoop集群通常使用分布式存储系统,如HDFS来存储大量的数据。如果存储系统的读写性能较低,会影响数据的读取和写入速度,从而降低整个集群的计算效率。
- 处理能力:集群中的计算节点数量和每个节点的计算能力都会影响集群的整体处理能力。如果集群规模较小或者每个节点的计算能力较低,可能无法满足大规模数据处理的要求,从而称为瓶颈。
- 内存容量:大数据计算通常需要进行大规模的数据分析和处理,这就需要大量的内存资源来存储和操作数据。如果集群中的节点内存容量不足,可能会导致数据无法完全加载到内存中,从而影响计算性能。
- 数据倾斜:在数据分析过程中,由于数据分布的不均匀性,可能会导致某些节点的数据负载过重,从而使得这些节点成为整个集群的瓶颈。数据倾斜的处理需要采取一些优化策略,如数据预处理、数据重分布等。
3、搭建Hadoop集群的xml文件有哪些?
- core-site.xml:配置Hadoop的核心参数,如文件系统默认方案、HDFS地址等。
- hdfs-site.xml:配置HDFS的相关参数,如副本数量、数据块大小等。
- mapred-site.xml:配置MapReduce相关参数,如作业跟踪器地址、任务分配器等。
- yarn-site.xml:配置YARN相关参数,如资源管理器地址、节点管理器等。
- hive-site.xml:如果需要使用Hive,则需要配置Hive的相关参数,如元数据存储位置、数据库连接等。
4、Hadoop的Checkpoint流程?
Hadoop的checkpoint流程是指在Hadoop集群中,将正在运行的任务的状态信息和元数据信息保存在持久化存储中,以便在集群发生故障或节点失效时,可以快速地恢复任务的执行状态。
流程如下:
- 当一个任务开始执行时,Hadoop会周期性地将任务地状态信息和元数据信息写入到Checkpoint目录中。这些信息包括任务的进度、输入数据的位置、已经完成的工作等。
- Checkpoint目录通常位于分布式文件系统(如HDFS)中,以保证数据的安全性和可靠性。
- Hadoop还会在内存中保存一个Checkpoint ID,用于标识当前的Checkpoint。
- 在任务执行过程中,如果集群发生故障或节点失效,任务会停止执行。
- 当集群恢复正常后,Hadoop会检查Checkpoint目录中的状态信息和元数据信息,并根据Checkpoint ID找到最新的Checkpoint。
- Hadoop会使用Checkpoint中的信息来恢复任务的执行状态,包括任务的进度、输入数据的位置等。
- 任务恢复完成后,Hadoop会继续执行任务,并从上次Checkpoint的位置继续处理数据,以确保不会重复执行已经完成的工作。
5、Hadoop的默认块大小是什么?为什么要设置这么大?
Hadoop的默认块大小是128MB。这个设置是经过仔细考虑的。
首先,大块大小可以减少寻址开销。在处理大型数据集时,如果块太小,会导致较多的寻址操作,增加了磁盘寻道时间,降低了整体的性能。通过增大块大小,可以减少寻址次数,提高数据的读写速度。
其次,大块大小可以提高数据的本地性。Hadoop是为了处理大规模数据而设计的,通常在集群中的不同节点上存储数据。当任务需要读取数据时,如果数据块大小较大,这些数据块有很大的概率可以在本地节点上找到,减少了网络传输的需求,提高了整体的效率。
最后,大块大小可以提高处理小文件的效率。在Hadoop中,每个文件都被拆分成多个块进行处理,如果块太小,会导致小文件的数量增加,从而增加了管理和调度的开销。通过增大块大小,可以减少小文件的数量,简化了整个系统的管理和调度过程。
6、Hadoop里Block划分的原因?
Hadoop中的数据存储是通过将大文件划分为固定大小的块(Block)来进行管理的。这样做的主要原因有以下几点:
- 分布式存储:Hadoop是一个分布式系统,数据存储在集群中的多个节点上。通过将文件划分为块,可以将这些块分散存储在不同的节点上,实现数据的分布式存储和并行处理。
- 数据冗余:Hadoop使用副本机制来确保数据的可靠性和容错性。将数据划分为块后,可以将每个块的多个副本分布在不同的节点上,以防止数据丢失或节点故障。
- 数据局限性:Hadoop采用了数据局部性原则,即将计算任务分配给存储数据的节点,以减少数据的网络传输和提高计算效率。将数据划分为块后,可以更好地实现数据局部性,因为计算任务可以针对某个块进行处理,而不需要处理整个文件。
- 管理和调度:将数据划分为块后,Hadoop可以更方便地管理和调度数据。块的大小可以根据具体应用和硬件配置进行调整,以优化数据处理和存储地性能。
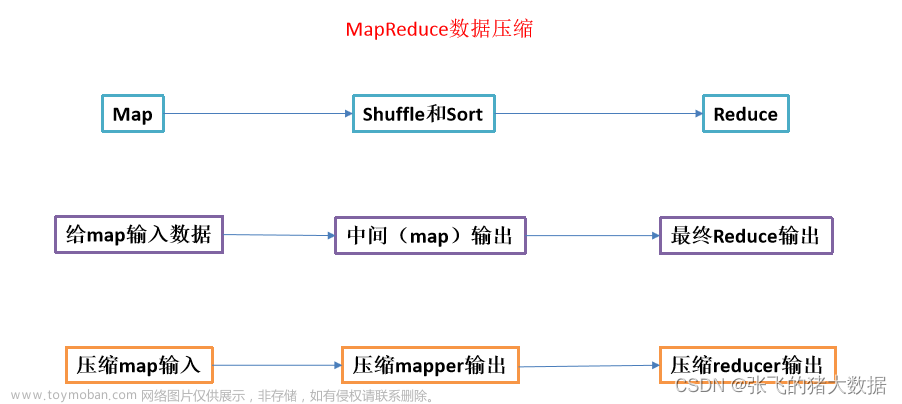
7、Hadoop常见的压缩算法?
- Gzip:Gzip是一种常见的压缩算法,可以减小文件的大小,但无法进行并行处理。
- Snappy:Snappy是Google开发的一种快速压缩/解压缩库,具有很高的压缩和解压缩速度,但相对于其它算法来说,压缩比较低。
- LZO:LZO是一种较快的压缩算法,可以在Hadoop中实现高速压缩和解压缩,适用于大数据处理。
- Bzip2:Bzip2是一种压缩算法,能够提供较高的压缩比,但相对较慢。
- LZ4:LZ4是一种极快的压缩算法,具有较高的压缩和解压缩速度,但压缩比较低。
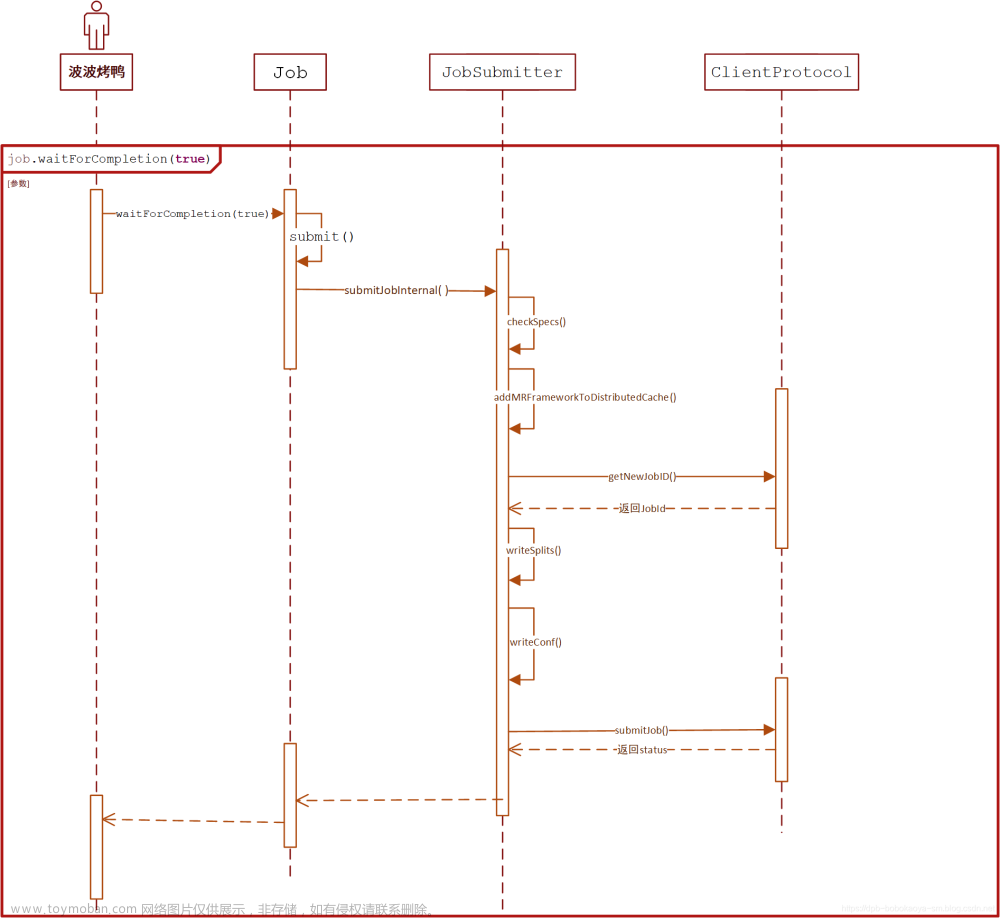
8、Hadoop作业提交到YARN的流程?
- 用户通过命令行或者客户端API向YARN提交作业。
- YARN的ResourceManager接收到作业提交请求后,会为该作业分配一个唯一的Application ID,并将该作业的元数据信息写入YARN的状态存储中,同时为该作业分配一个ApplicationMaster。
- ResourceManager将Application ID和ApplicationMaster的地址返回给客户端。
- 客户端通过ApplicationMaster的地址与其建立通信,并向其发送作业的资源需求(如CPU、内存等)以及作业启动命令。
- ApplicationMaster收到作业资源需求和启动命令后,会向ResourceManager请求作业所需的资源。
- ResourceManager根据可用资源的情况为ApplicationMaster分配所需的资源,并将资源的位置信息返回给ApplicationMaster。
- ApplicationMaster收到资源位置信息后,会与NodeManager进行通信,将作业所需的资源分配给具体的任务(Task)。
- 每个Task会在一个独立的容器(Container)中运行,它们会通过心跳机制向ApplicationMaster汇报任务的执行情况。
- ApplicationMaster会收集所有任务的执行情况,并在作业完成后向ResourceManager注销自己。
- ResourceManager接收到ApplicationMaster的注销请求后,会将该作业从YARN的状态存储中删除,并释放相关资源。
9、Hadoop的Combiner的作用?
Hadoop的Combiner的作用是在Map阶段之后,在数据传输到Reduce阶段之前对Map输出的中间劫夺进行本地合并和压缩,以减少数据的传输量和提高整体的性能。Combiner可以将相同key的多个Map输出结果进行合并,减少了网络传输的数据量,从而减少了Reduce阶段的负载。通过使用Combiner,可以在不影响最终结果的情况下,提高整个作业的执行效率。文章来源:https://www.toymoban.com/news/detail-842606.html
10、Hadoop序列化和反序列化
Hadoop序列化和反序列化是指将数据从内存中转换为字节流的过程,并在需要时将字节流重新转换为原始数据类型。这是Hadoop生态系统中处理大数据的关键技术之一。
Hadoop序列化是将数据对象转换为字节流的过程。在Hadoop中,数据对象通常是以Java对象的形式存在的,但是在网络传输或磁盘存储时,需要将这些对象转换为字节流。序列化的目的是将数据压缩成字节流的形式,以便在网络传输或磁盘存储中占用更少的空间。Hadoop提供了多种序列化机制,如Java默认的Serialzable接口、Avro、Thrift和Protocol Buffers等。
Hadoop反序列化是将字节流转换回原始数据类型的过程。在接收到字节流后,需要将其还原为原始数据对象。反序列化的过程是序列化的逆向过程,它将字节流转换为Java对象或其它原始数据类型。Hadoop提供了相应的反序列化机制来与序列化机制配置使用,以便在数据传输和数据处理过程中与原始数据进行转换。文章来源地址https://www.toymoban.com/news/detail-842606.html
到了这里,关于大数据开发(Hadoop面试真题-卷三)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!