Hadoop
Hadoop是一个开源的分布式计算框架,旨在处理大规模数据集和进行并行计算。核心包括两个组件:HFDS、MapReduce。
配置方案
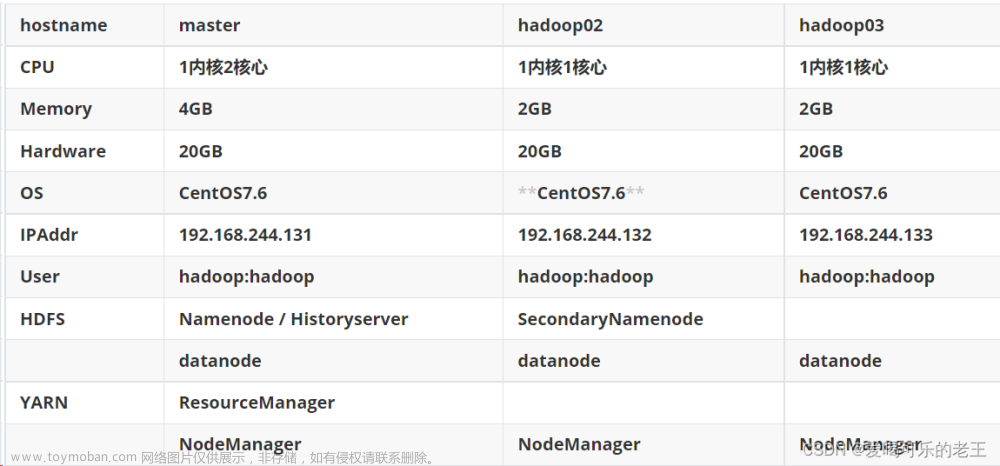
各虚拟机的用户名分别为test0、test1、test2,主机名为hadoop100、hadoop101、hadoop102
虚拟机的分配如下:
- hadoop100:NameNode + ResourceManager
- hadoop101:DataNode + NodeManager
- hadoop102:SecondaryNameNode
其中Master为hadoop100,这个配置方案可以提供集群的基本功能,Master节点负责管理整个文件系统的元数据和资源调度,而Worker节点负责存储数据和执行任务。
各节点的作用:
- NameNode:负责管理整个分布式文件系统的命名空间和文件元数据。它是HDFS的主节点,负责存储文件系统的元数据信息,并处理客户端的文件操作请求。将一台虚拟机作为NameNode节点可以提供高可靠性和容错性。
- SecondaryNameNode:主要负责协助NameNode进行元数据备份和检查点操作。它定期从NameNode获取编辑日志,并创建检查点,从而减少NameNode对元数据的负担和故障恢复时间。请注意,SecondaryNameNode并不是NameNode的备份,无法自动接管NameNode的角色。
- HDFS DataNode:负责存储和管理实际的数据块。它接收并处理从NameNode分配的数据块写入请求,并执行数据块的读取和复制操作。HDFS DataNode节点存储实际的数据块和后续读写操作。
安装Hadoop
上传压缩包,并解压
tar zxvf hadoop-3.3.6.tar.gz
打开环境变量注册表
vim /etc/profile
配置环境变量
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
配置生效
source /etc/profile
进入Hadoop的安装目录,编辑/etc/hadoop/hadoop-env.sh文件,设置JAVA_HOME为您的JDK安装路径
export JAVA_HOME=/opt/dev/jdk1.8.0_151
检查是否安装完成,使用命令查看hfs中的根目录
hadoop fs -ls /
由于Hadoop单机模式是一种用于开发和测试的模式,它并不需要进行集群和分布式环境的设置。在Hadoop单机模式下,默认情况下,Hadoop会使用当前用户的身份进行操作,而无需输入密码。
配置Hadoop分布式集群
前提条件:
- 三台Linux系统虚拟机(可使用VMWare软件进行克隆)定义为hadoop100、hadoop101、hadoop102
- 所有虚拟机都需要联通网络
- 虚拟机之间区别主机名
- 三台虚拟机都拥有相同路径版本的 JDK 和 Hadoop
设置主机名
首先分别打开三台虚拟机,分别使用下列指令将主机名修改。
由于NetworkManager服务的配置问题,直接使用hostname指令设置主机名在重启后会失效,需要每次开机重启,若想永久修改主机名生效,则修改/etc/hostname文件
vi /etc/hostname
下述的hadoop100是指新的主机名。同理修改其他的虚拟机主机名
hadoop100
分别检查虚拟机网络,当有数据返回时则无问题
ping www.baidu.com
编辑主机名列表文件
vi /etc/hosts
在文件加入,指定IP地址对应的hostname
192.168.10.128 badoop100
192.168.10.130 hadoop101
192.168.10.131 hadoop102
重启生效
reboot
在主机验证
ping hadoop101
分发 JDK 和 Hadoop
如果没有安装JDK和Hadoop,则可先在某一台虚拟机上安装完毕:
tar -zxvf /opt/jdk1.8.0_151.tar.gz
然后在该虚拟机上通过下列的集群分发脚本将 JDK和Hadoop分别分发到其他的虚拟机中,后续要输入yes和当前将要连接的hadoop101的密码:
# 将当前JDK发送到test1用户下主机名为hadoop101的/opt/dev/jdk1.8.0_151路径
scp -r /opt/dev/jdk1.8.0_151 test1@hadoop101:/opt/dev/jdk1.8.0_151
# 将Hadoop发送到test2用户下主机名为hadoop102的/opt/dev/jdk1.8.0_151路径
scp -r /opt/hadoop/bin/hadoop test1@hadoop102:/opt/hadoop/bin/hadoop
记得配置环境变量,查看环境变量profile文件
vim /etc/profile
目标虚拟机都要设置环境变量
export JAVA_HOME=/opt/dev/jdk1.8.0_151
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/bin
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
让配置文件生效
source /etc/profile
输入java指令检验Java是否安装成功
java -version
输入hadoop指令查看是否安装成功
hadoop
设置免密登录
配置SSHD:如果免密登录不生效或出现连接错误,可能是由于目标节点的SSH服务器配置不正确。在目标节点上,编辑/etc/ssh/sshd_config文件,确保以下设置:
vim /etc/ssh/sshd_config
PubKeyAuthentication yes
PasswordAuthentication no
重启ssh服务:
sudo service ssh restart
分别在三个虚拟机中的~/.ssh目录下生成id_rsa和id_rsa.pub文件,分别对应着私钥和公钥:
ssh-keygen -t rsa
将公钥复制到其他虚拟机上,实现SSH的无密码登录:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
修改authorized_keys文件的权限
chmod 600 ~/.ssh/authorized_keys
将主节点的公钥文件分发到集群中的各个节点上,使得节点可以进行免密登录。可以使用ssh-copy-id命令实现自动分发。运行以下命令,其中test1、test2是目标节点的登录用户名,hadoop101、hadoop102是节点主机名:
ssh-copy-id -i ~/.ssh/id_rsa.pub test1@hadoop101
ssh-copy-id -i ~/.ssh/id_rsa.pub test2@hadoop102
输入完成后,输入目标机的密码,将主节点的公钥添加到从节点的~/.ssh/authorized_keys文件中。
远程登录目标机,测试是否成功共享密钥,如果可以成功登录且不用输入密码,则表示免密登录已经配置成功:
ssh test1@hadoop101
ssh test2@hadoop102
配置hadoop-env.sh
打开文件
vi etc/hadoop/hadoop-env.sh
修改文件
export JAVA_HOME=/opt/dev/jdk1.8.0_381
配置core-site.xml
打开文件
vi etc/hadoop/core-site.xml
修改文件:
fs.defaultFS:该参数是配置指定HDFS的通信地址。
hadoop.tmp.dir:该参数配置的是Hadoop临时目录
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop100:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoopTmp/</value>
</property>
</configuration>
配置hdfs-site.xml
打开文件
vi etc/hadoop/hdfs-site.xml
修改文件:
dfs.namenode.http-address:该参数是配置NameNode的http访问地址和端口号。因为在集群规划中指定hadoop100设为NameNode的服务器,故设置为hadoop100:9870。
dfs.namenode.secondary.http-address:该参数是配置SecondaryNameNode的http访问地址和端口号。在集群规划中指定hadoop102设为SecondaryNameNode的服务器,故设置为hadoop102:50090。
dfs.replication:该参数是配置HDFS副本数量。
dfs.namenode.name.dir:该参数是设置NameNode存放的路径。
dfs.datanode.data.dir:该参数是设置DataNode存放的路径。
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop100:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop102:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoopTmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoopTmp/dfs/data</value>
</property>
</configuration>
配置yarn-site.xml
打开文件
vi etc/hadoop/yarn-site.xml
修改文件:
参数说明:
yarn.resourcemanager.hostsname:该参数是指定ResourceManager运行在那个节点上。
yarn.resourcemanager.webapp.address:该参数是指定ResourceManager服务器的web地址和端口。
yarn.nodemanager,aux-services:该参数是指定启动时加载server的方式。
yarn.nodemanager.aux-services.mapreduce.shuffle.class:该参数是指定使用mapreduce_shuffle中的类。
yarn.log-aggregation-enable:该参数是配置是否启用日志聚集功能。
yarn.log-aggregation.retain-seconds:该参数是配置聚集的日志在HDFS上保存的最长时间。
yarn.nodemanager.remote-app-log-dir:该参数是指定日志聚合目录。
<configuration>
<property>
<name>yarn.resourcemanager.hostsname</name>
<value>hadoop100</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop100:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/user/hadoopcontainer/logs</value>
</property>
</configuration>
配置mapred-site.xml
打开文件
vi etc/hadoop/mapred-site.xml
修改文件参数说明:
mapreduce.framework.name:该参数是指定MapReduce框架运行在YARN上。
mapreduce.jobhistory.address:该参数是设置MapReduce的历史服务器安装的位置及端口号。
mapreduce.jobhistory.webapp.address:该参数是设置历史服务器的web页面地址和端口。
mapreduce.jobhistory.intermediate-done-dir:该参数是设置存放日志文件的临时目录。
mapreduce.jobhistory.done-dir:该参数是设置存放运行日志文件的最终目录。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>${hadoop.tmp.dir}/mr-history/tmp</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>${hadoop.tmp.dir}/mr-history/done</value>
</property>
</configuration>
配置主次节点
PS:hadoop3以后slaves改为workers,新建文件
vim etc/hadoop/slaves
vim etc/hadoop/workers
添加所有节点的主机名:
hadoop100
hadoop101
hadoop102
分发配置文件
在其他节点查看下当前存放hadoop目录是否具有权限写入,否则后续分发将失败
ls -ld /opt/hadoop
如果没有权限,则输入下列指令开放hadoop目录的写入权限
sudo chmod -R 777 /opt/hadoop
将上述配置好的hadoop相关文件分发到其他虚拟机:
scp -r /opt/hadoop/* test1@hadoop101:/opt/hadoop/
scp -r /opt/hadoop/* test2@hadoop102:/opt/hadoop/
在主节点创建日志文件夹
sudo mkdir /opt/hadoopTmp/dfs/name
sudo mkdir /opt/hadoopTmp/dfs/data
启动集群
在主节点输入格式化命令:
hdfs namenode -format
启动集群
start-all.sh
停止集群
stop-all.sh
验证是否成功
jps
当看到下列内容表示成功:
Master: NameNode、DataNode、ResourceManager、NodeManager
slave1: SecondaryNameNode、DataNode、NodeManager
slave2: DataNode、NodeManager
Web端访问
关闭防火墙:
service iptables stopservice iptables stop
访问HDFS:ip地址:9870;
访问YARN:ip地址:8088;
版本注意事项
-
Hadoop3版本后,NameNode、Secondary NameNode, DataNode的端口出现了变化。文章来源:https://www.toymoban.com/news/detail-842693.html
2版本端口号 3版本端口号 namenode 8020 9820 namenode htttp web 50070 9870 namenode https web 50470 9871 secondnamenode https web 50091 9869 secondnamenode https web 50091 9869 secondnamenode http web 50090 9868 datanode ipc 50020 9867 datanode 50010 9866 datanode http web 50075 9864 datanode https web 50475 9865 -
Hadoop3版本之前的主从节点文件为slaves,3之后为workers文章来源地址https://www.toymoban.com/news/detail-842693.html
到了这里,关于Linux环境搭建Hadoop及完全分布式集群的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!