前言
文字型pdf提取,python的库一大堆,但是图片型pdf和pdf扫描件提取,还是有些难度的,我们需要用到OCR(光学字符识别)功能。
一、准备
1、安装OCR(光学字符识别)支持库
首先要安装pytesseract和Tesserac OCR,Tesseract OCR是一种广泛使用的OCR工具,它可以用于从图像中提取文字。Tesseract OCR具有较高的识别精度和速度,同时支持多种语言。在Python中,可以使用pytesseract库来调用Tesseract OCR。
(1)安装pytesseract库:
pip install pytesseract
(2)安装Tesseract OCR程序
下载安装
github下载地址:https://github.com/tesseract-ocr/tesseract
国内下载地址:https://digi.bib.uni-mannheim.de/tesseract/
如果要识别中文的话,要安装3.0以上的版本,我这里以国内下载地址为例,下载5.0版本,如图: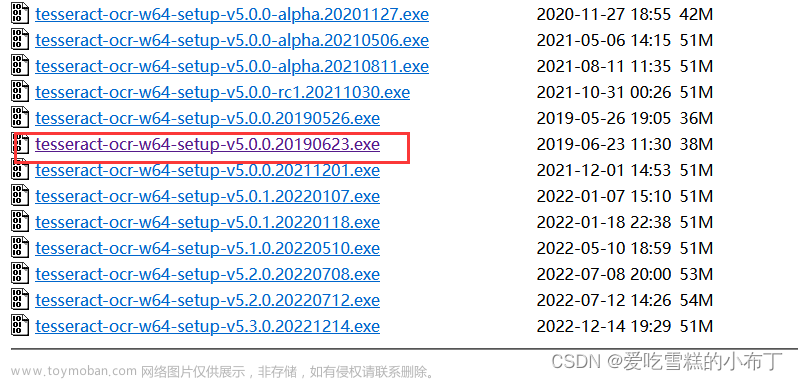
下载完成之后,双击打开,一路next即可,自己选择好安装位置,后面要配置环境变量的。
配置环境变量
我的安装位置如图:
找到系统变量的path,点击编辑,如图:

新建一个环境变量,变量的值是tesseract的安装位置,如图:
点击确定之后,在系统变量界面,点击新建,新建一个系统变量,名称为TESSDATA_PREFIX,值为安装目录下的tessdata目录位置,如图:


一路点击确定即可。
下载中文包
软件默认使用的是英文包,只能识别英文,我们现在下载配置中文包,下载地址:
github:https://github.com/tesseract-ocr/tessdata
gitcode(国内):https://gitcode.com/mirrors/tesseract-ocr/tessdata/tree/main?utm_source=csdn_github_accelerator&isLogin=1
建议选择国内地址,下载速度比较快,我们下载五个包,分别是:eng.traineddata、chi_sim.traineddata、chi_sim_vert.traineddata、chi_tra.traineddata、chi_tra_vert.traineddata,如图:

第一个是英文包,后面四个是中文包,sim开头是简体,tra开头是繁体,点击进去,点击右侧的下载,将五个包下载下来,如图:

下载完成之后,复制到tesseract安装目录下的tessdata文件夹下,如图:
在命令行输入tesseract -v,显示tesseract的版本号,就表示安装完成了,如图:
现在安装工作就完成了。
测试图片识别
测试图片如下:
测试代码:
import pytesseract
from PIL import Image
# (1)配置tesseract安装路径
pytesseract.pytesseract.tesseract_cmd = r'F:\tesseract\tesseract.exe'
text = pytesseract.image_to_string(Image.open(r'1-26.jpg'))
print(text)
结果如下:
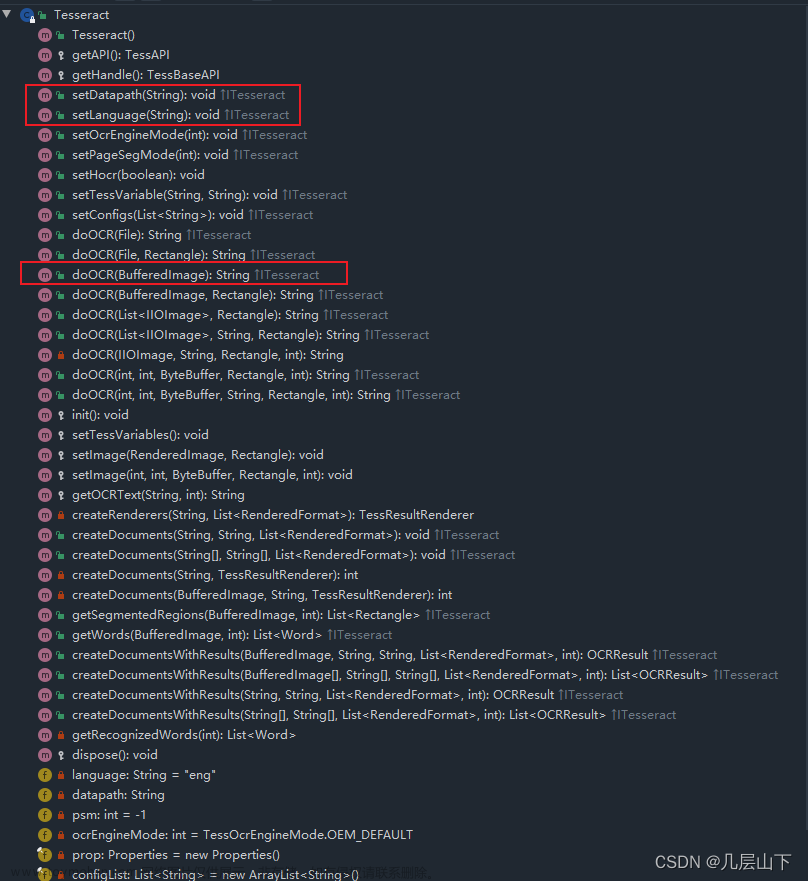
如果我们不想每次代码都去配置tesseract的安装路径的话,可以直接在源文件里面修改,我们找到如图的文件,将框出来的地方修改成安装路径即可:
(2)安装其他库
pip install PyMuPDF PIL
二、正式提取图片型pdf的文字
代码如下:
# -*- coding: UTF-8 -*-
"""
@Date :2023/12/17
"""
import fitz
import pytesseract
from PIL import Image
import io
# (1)配置tesseract安装路径
pytesseract.pytesseract.tesseract_cmd = r'F:\tesseract\tesseract.exe'
# (2)打开pdf文件
pdf_file = fitz.open(r'一户一宅.pdf')
# (3)遍历pdf的每一页
for page_num in range(len(pdf_file)):
# 获取页面
page = pdf_file[page_num]
# 提取页面上的图像
image_list = page.get_images(full=True)
for image_index, img in enumerate(image_list):
# 提取图像
xref = img[0]
base_image = pdf_file.extract_image(xref)
image_bytes = base_image["image"]
# 将字节转换为PIL图像
image = Image.open(io.BytesIO(image_bytes))
# 使用pytesseract对图像进行ocr
text = pytesseract.image_to_string(image, lang='chi_sim')
# 打印结果
print(f"Page {page_num + 1}, Image {image_index + 1}:")
print(text)
# 关闭pdf文件
pdf_file.close()
结果如下:
总结
需要注意的是,Tesseract OCR对于一些复杂或低质量的图像可能识别效果不佳。
提示
对于文字型pdf的提取,可以看这几篇文章:
https://blog.csdn.net/weixin_43856625/article/details/134705266
https://www.jianshu.com/p/8fbb662bd6f7文章来源:https://www.toymoban.com/news/detail-842773.html
https://blog.csdn.net/Achernar0208/article/details/129199937文章来源地址https://www.toymoban.com/news/detail-842773.html
到了这里,关于python提取图片型pdf中的文字(提取pdf扫描件文字)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!