前言
本文的解决方案旨在解决大体积PDF在线浏览加载缓慢、影响用户体验的难题。通过利用分片加载技术,前端请求时附带range及读取大小信息,后端据此返回相应的PDF文件流。这种方式有效地减轻了服务器和浏览器的负担,提升了加载速度和用户体验。同时解决了首次加载全部分片导致浏览器内存不足的问题。
技术栈:Spring Boot、Vue和pdf.js。
分片加载的效果

前端项目
前端项目结构


前端核心代码
index.vue
<template>
<div class="pdf">
<iframe
:src="`/static/pdf/web/viewer.html?file=${encodeURIComponent(src)}`"
frameborder="0"
style="width: 100%; height: calc(100vh)"
></iframe>
</div>
</template>
<script>
import baseUrl from "@/api/baseurl.js";
export default {
data() {
return {
baseUrl: baseUrl.baseUrl,
src: "",
loading: false,
};
},
created() {},
methods: {
getPdfCode: function () {
this.loading = true;
// 这里是请求分片的接口,看情况修改
this.src = `http://localhost:8181/v1/pdf/load`;
},
},
mounted() {
this.$nextTick(() => {
this.getPdfCode();
});
},
};
</script>
<style lang="scss" scoped></style>

前端项目运行
首先确保vue需要的运行环境已经安装(nodejs),我使用的版本:12.18.2,然后使用vscode打开项目,在终端输入命令:
npm install
npm run serve

后端项目
后端项目结构
本示例只是一个简单的springboot项目,核心文件PDFController.java用于分片加载接口,CORSFilter.java为跨域配置

后端核心代码
这段代码实现了使用 PDF.js 进行分片加载 PDF 文件的功能。下面是代码的主要实现思路:
- 首先,通过
ResourceUtils.getFile方法获取类路径下的 PDF 文件,并将其读取为字节数组pdfData。 - 然后,判断文件大小是否小于指定的阈值(1MB),如果小于阈值,则直接将整个文件作为响应返回。修改了小体积pdf小于分片大小时无法访问的bug
- 如果文件大小超过阈值,就根据请求头中的
Range字段判断是否为断点续传请求。 - 如果是首次请求或者没有
Range字段,则返回整个文件的字节范围,并设置响应状态为SC_OK(响应码200)。 - 如果是断点续传请求,则解析
Range字段获取请求的起始位置和结束位置,并根据这些位置从文件中读取相应的字节进行响应。 - 在响应头中设置
Accept-Ranges和Content-Range属性,告知客户端服务器支持分片加载,并指定本次返回的文件范围。 - 最后,设置响应的内容类型为
application/octet-stream,内容长度为本次返回的字节数,然后刷新输出流,将数据返回给客户端。
这样,客户端就可以使用 PDF.js 来分片加载显示 PDF 文件了。
PDFController.java
/**
/**
* pdf分片加载的后端实现
*
* @param response
* @param request
* @throws FileNotFoundException
*/
@GetMapping("/load")
public void loadPDFByPage(HttpServletResponse response, HttpServletRequest request) throws FileNotFoundException {
// 获取pdf文件,建议pdf大小超过20mb以上
File pdf = ResourceUtils.getFile("classpath:需要分片加载的pdf.pdf");
byte[] pdfData = new byte[0];
try {
pdfData = FileUtils.readFileToByteArray(pdf);
} catch (IOException e) {
throw new RuntimeException(e);
}
// 以下为pdf分片的代码
try (InputStream is = new ByteArrayInputStream(pdfData);
BufferedInputStream bis = new BufferedInputStream(is);
OutputStream os = response.getOutputStream();
BufferedOutputStream bos = new BufferedOutputStream(os)) {
// 下载的字节范围
int startByte, endByte, totalByte;
// 获取文件总大小
int fileSize = pdfData.length;
int minSize = 1024 * 1024;
// 如果文件小于1 MB,直接返回数据,不需要进行分片
if (fileSize < minSize) {
// 直接返回整个文件
response.setStatus(HttpServletResponse.SC_OK);
response.setContentType("application/octet-stream");
response.setContentLength(fileSize);
bos.write(pdfData);
return;
}
// 根据HTTP请求头的Range字段判断是否为断点续传
if (request == null || request.getHeader("range") == null) {
// 如果是首次请求,返回全部字节范围 bytes 0-7285040/7285041
totalByte = is.available();
startByte = 0;
endByte = totalByte - 1;
response.setStatus(HttpServletResponse.SC_OK);
// 写入一些数据到输出流中,否则火狐浏览器会报错:ns_error_net_partinal_transfer
bos.write(1);
} else {
// 断点续传逻辑
String[] range = request.getHeader("range").replaceAll("[^0-9\\-]", "").split("-");
// 文件总大小
totalByte = is.available();
// 下载起始位置
startByte = Integer.parseInt(range[0]);
// 下载结束位置
endByte = range.length > 1 ? Integer.parseInt(range[1]) : totalByte - 1;
// 跳过输入流中指定的起始位置
bis.skip(startByte);
// 表示服务器成功处理了部分 GET 请求,返回了客户端请求的部分数据。
response.setStatus(HttpServletResponse.SC_PARTIAL_CONTENT);
int bytesRead, length = endByte - startByte + 1;
byte[] buffer = new byte[1024 * 64];
while ((bytesRead = bis.read(buffer, 0, Math.min(buffer.length, length))) != -1 && length > 0) {
bos.write(buffer, 0, bytesRead);
length -= bytesRead;
}
}
// 表明服务器支持分片加载
response.setHeader("Accept-Ranges", "bytes");
// Content-Range: bytes 0-65535/408244,表明此次返回的文件范围
response.setHeader("Content-Range", "bytes " + startByte + "-" + endByte + "/" + totalByte);
// 告知浏览器这是一个字节流,浏览器处理字节流的默认方式就是下载
response.setContentType("application/octet-stream");
// 表明该文件的所有字节大小
response.setContentLength(endByte - startByte + 1);
// 需要设置此属性,否则浏览器默认不会读取到响应头中的Accept-Ranges属性,
// 因此会认为服务器端不支持分片,所以会直接全文下载
response.setHeader("Access-Control-Expose-Headers", "Accept-Ranges,Content-Range");
// 第一次请求直接刷新输出流,返回响应
response.flushBuffer();
} catch (IOException e) {
e.printStackTrace();
}
}
CORSFilter.java 通用的跨域配置
package com.example.pdfload.filter;
import org.springframework.stereotype.Component;
import javax.servlet.*;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
@Component
public class CORSFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
HttpServletResponse response1 = (HttpServletResponse) response;
response1.addHeader("Access-Control-Allow-Credentials", "true");
response1.addHeader("Access-Control-Allow-Origin", "*");
response1.addHeader("Access-Control-Allow-Methods", "GET, POST, DELETE, PUT");
response1.addHeader("Access-Control-Allow-Headers",
"range,Accept-Ranges,Content-Range,Content-Type," +
"X-CAF-Authorization-Token,sessionToken,X-TOKEN,Cache-Control,If-Modified-Since");
if (((HttpServletRequest) request).getMethod().equals("OPTIONS")) {
response.getWriter().println("ok");
return;
}
chain.doFilter(request, response);
}
@Override
public void destroy() {
}
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
}
后端项目运行

项目运行效果

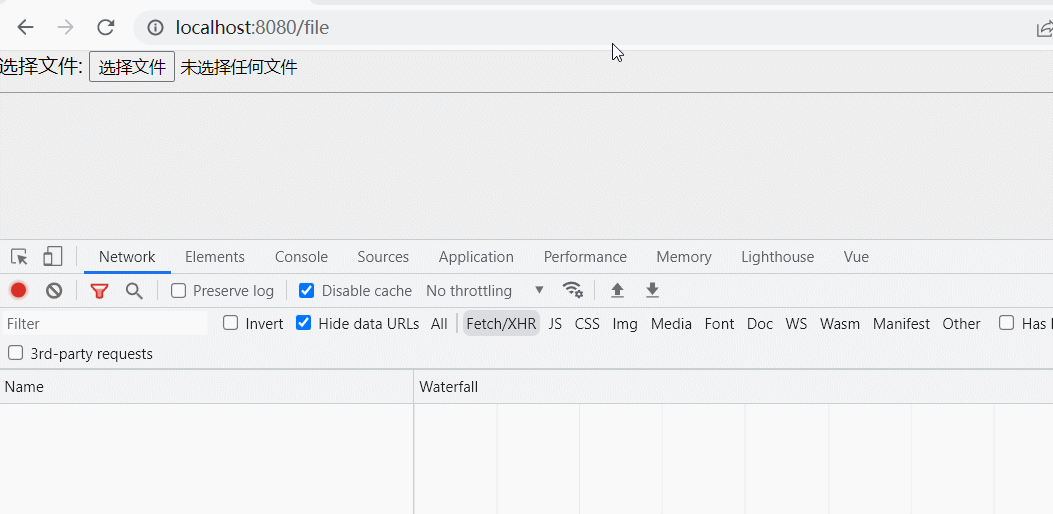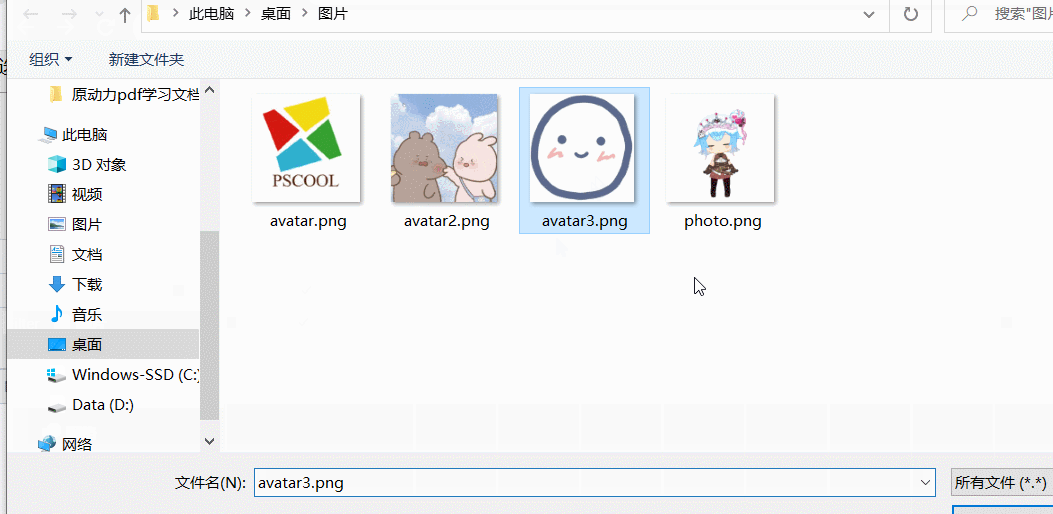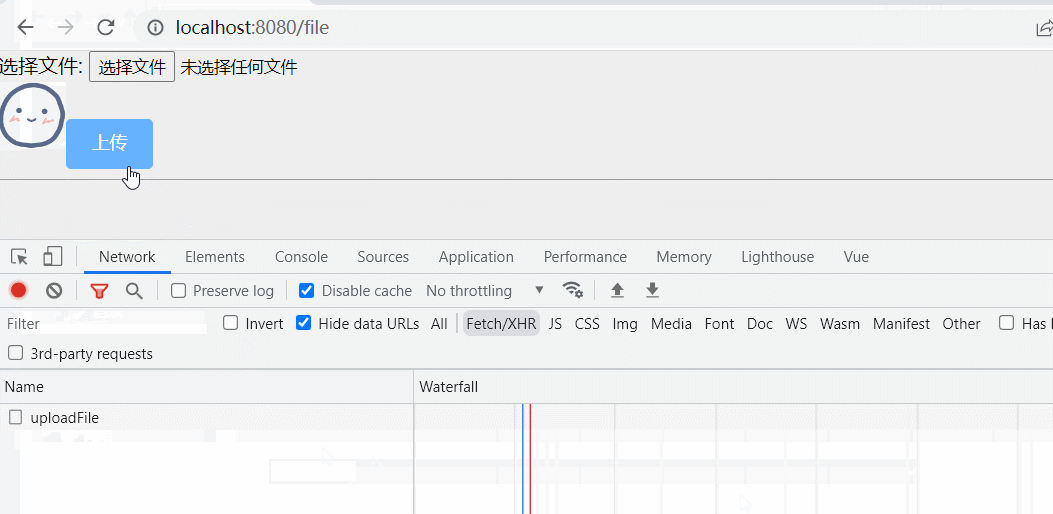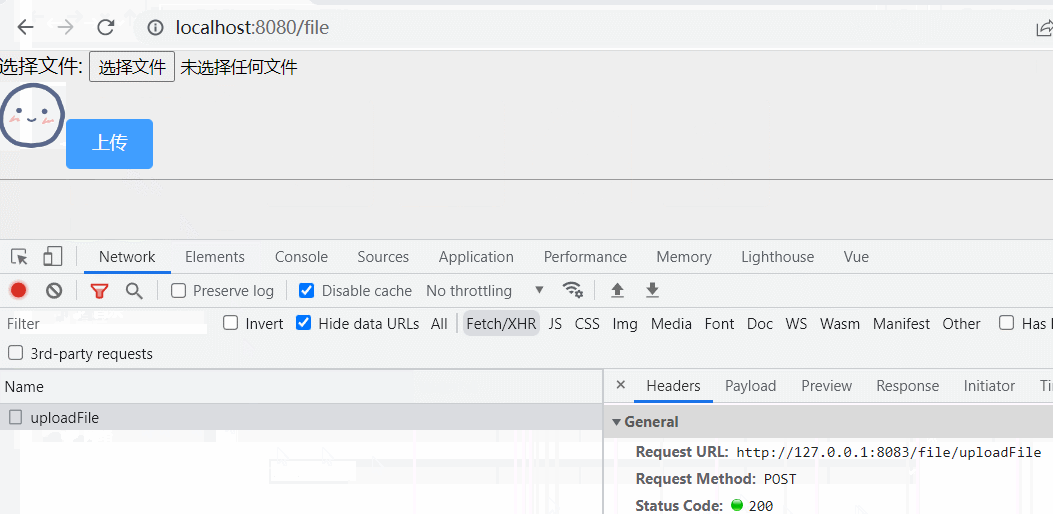
首次访问
首次访问返回状态码200,返回响应信息如下:

// 表明服务器支持分片加载
response.setHeader("Accept-Ranges", "bytes");
// Content-Range: bytes 0-65535/408244,表明此次返回的文件范围
response.setHeader("Content-Range", "bytes " + startByte + "-" + endByte + "/" + totalByte);
// 告知浏览器这是一个字节流,浏览器处理字节流的默认方式就是下载
response.setContentType("application/octet-stream");
// 表明该文件的所有字节大小
response.setContentLength(endByte - startByte + 1);
// 需要设置此属性,否则浏览器默认不会读取到响应头中的Accept-Ranges属性,
// 因此会认为服务器端不支持分片,所以会直接全文下载
response.setHeader("Access-Control-Expose-Headers", "Accept-Ranges,Content-Range");
分片加载
分片加载返回状态码206,返回响应信息如下:


项目源码
 文章来源:https://www.toymoban.com/news/detail-842793.html
文章来源:https://www.toymoban.com/news/detail-842793.html
链接: https://pan.baidu.com/s/1KNn2HE_ZudMRyzPK8_wIjA?pwd=zhou
提取码: zhou文章来源地址https://www.toymoban.com/news/detail-842793.html
到了这里,关于SpringBoot+PDF.js实现按需分片加载预览(包含可运行示例源码)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!