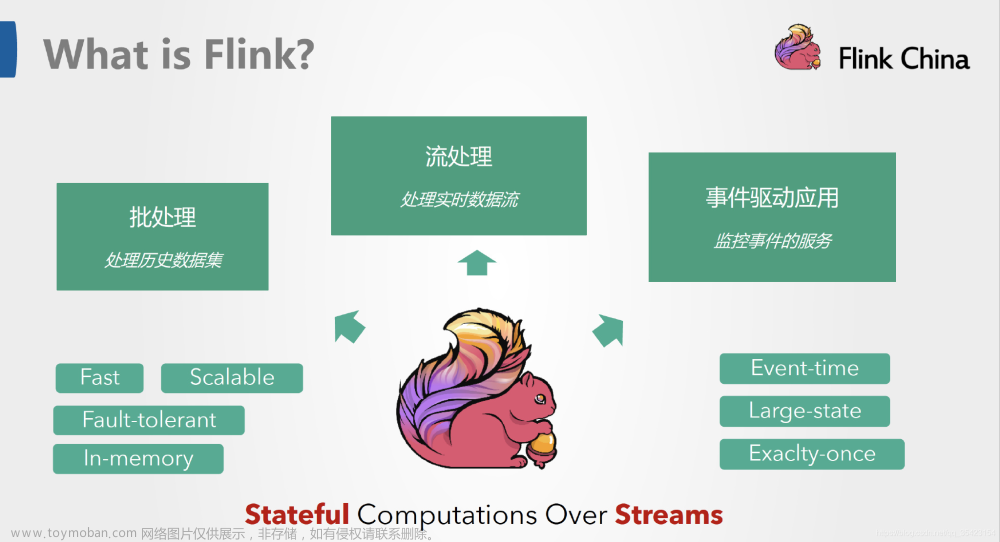
Backpressure(背压)
在分布式流处理系统中,Backpressure(背压)是一个重要的概念,用于的处理系统中不同速率产生和处理数据问题。当数据的生成速率超过处理速率时,未经处理的数据会在系统中积累,可能导致内存溢出或其他资源瓶颈。Backpressure 机制能够帮助系统动态调整处理速度,以避免这种情况。下面我们分别看看在 Spark 和 Flink 中 Backpressure 是如何工作的。
Spark Streaming 中的 Backpressure
在 Spark Streaming 中,Backpressure 是通过动态调整接收数据的速率来实现的。Spark Streaming 允许开启一个自适应的 Backpressure 机制,它可以根据处理的延迟情况自动调整数据接收的速率,以保持系统的稳定运行。
当你开启 Backpressure 时,Spark Streaming 会根据当前批处理的完成时间和设定的批处理间隔来调整下一个批次应接收的数据量。如果批处理的时间超过了设定的间隔,说明系统处理能力已经饱和,Spark Streaming 会减少接收的数据量;反之,则可以增加接收的数据量。这样可以有效避免系统因为处理不过来而出现积压过多数据的情况。
Flink 中的 Backpressure
Flink 的设计理念是提供低延迟和高吞吐的实时数据流处理。与 Spark Streaming 的微批处理模型不同,Flink 是基于真正的流处理模型。Flink 中的 Backpressure 机制是自动的,并且是通过网络层面实现的。
在 Flink 中,如果一个操作(operator)的处理速度低于数据到达的速度,那么这个操作会开始积压数据。由于 Flink 是基于数据流模型的,所以当下游操作无法跟上数据处理速度时,数据会在上游操作处积累,形成背压。Flink 通过检查各个任务之间的数据缓冲区的填充程度来监控和管理 Backpressure。如果某个任务的输出缓冲区持续处于满状态,就意味着下游的任务成为了瓶颈,Flink 会自动调整处理流程,以避免系统过载。
Flink 提供了一个 Web UI 来展示当前作业的 Backpressure 情况,通过这个界面可以很直观地看到系统的处理瓶颈,帮助开发者优化作业配置和逻辑。文章来源:https://www.toymoban.com/news/detail-843004.html
Backpressure 是分布式流处理系统中解决数据生成速度超过处理速度问题的关键机制。在 Spark Streaming 和 Flink 中,虽然实现机制不同,但目的都是为了保持系统的稳定性和避免资源的过度消耗。通过动态调整数据流的速率或处理速度,这两个系统都能有效地管理处理能力有限时的数据积压问题。文章来源地址https://www.toymoban.com/news/detail-843004.html
到了这里,关于在Flink中,什么是背压Backpressure?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!