上一章我们主要唠了RLHF训练相关的方案,这一章我们主要针对RLHF的样本构建阶段,引入机器标注来降低人工标注的成本。主要介绍两个方案:RLAIF,和IBM的SALMON。
RLAIF
- RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
RLAIF给出的方案是完全使用大模型来进行偏好样本的标注,论文主要测试了摘要任务,对话的无害性和有用性上,RLAIF能获得和RLHFg相似的效果。我们在后期也采用了机器标注,因为真的不标不知道一标吓一跳,想获得足够用来训练RL的高质量标注样本的成本大的吓人......
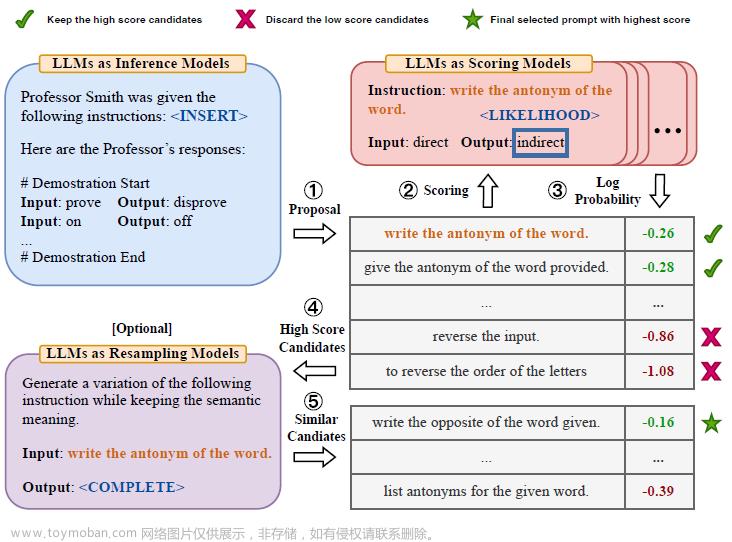
既然是用大模型来标注偏好样本,那核心又回到了如何写Prompt, RLAIF一个基础的Prompt构建如下:Preamble是如何进行评估的任务指令,Exampler是高质量的标注few-shot,然后是上文和两条待评估的摘要,最后是模型输出。

论文还提到了几个指令优化细节
- soft label:想让模型评估两个样本的优劣,有很多种打分方式,论文选择了输出样本序号的方式,这样既符合自然语言表达,同时因为就1个输出字符,可以很直观的计算1和2的解码概率,从而得到soft label,后续用于RM训练
- Positional bias: 考虑summary1和2的前后顺序会影响模型的评估结果,论文会分别对12,21的两组样本进行打分,并取soft label的平均值。这里论文验证了越小的模型位置偏差越严重。
- 加入COT: 在Ending的部分加入思维链指令"Consider the coherence, accuracy, coverage, and overall quality of each summary and explain which one is better. Rationale:"
- 解码策略:在附录中论文对比了self-consistency和greedy decode,效果上greedy更好,哈哈但是self-consistency的样本最多只用到16,所以这个对比做的不是非常充分。
获取到机器标注数据后,论文使用soft-label[0.6,0.4]来进行Reward模型的训练再对SFT之后的模型进行对齐。注意这里有一个细节就是论文使用了soft label,从模型蒸馏的角度,soft label比[0,1]的hard label包含远远更多的信息,在蒸馏方案中往往可以显著提高蒸馏效果,因此不排除RLAIF超过人工标注效果的部分原因,来自soft-label而非machine label。对齐后的模型效果对比如下,RLAIF的无害率提升更加明显,胜率和RLHF齐平

细看会发现上面对比中还有两个细节
- same-size RLAIF:RLAIF的标注模型是PaLM2 Large,而SFT模型是PaLM2 XS。论文同时测试了当标注模型和SFT模型大小同样为PaLM2 XS的效果。说明RLAIF的效果不完全来自模型大到小的蒸馏,在同样大小上模型标注可以带来自我提升
- Direct RLAIF:是不使用Reward模型进行训练,直接使用大模型(PaLM2 XS)标注出1-10分的打分,并把打分概率归一化到sum(1).然后直接使用模型打分作为reward来进行对齐。但个人对这种方案表示存疑,因为在我们的尝试中模型的绝对打分能力并不高,哈哈不排除我们任务有点复杂prompt没写好。论文使用的prompt如下
prompt = """You are an expert summary rater. Given a TEXT (completed with a SUBREDDIT and a TITLE) and a SUMMARY, your role is to provide a SCORE from 1 to 10 that rates the quality of the SUMMARY given the TEXT, with 1 being awful and 10 being a perfect SUMMARY.
"""
IBM SALMON
- SALMON: SELF-ALIGNMENT WITH PRINCIPLE-FOLLOWING REWARD MODELS
- https://github.com/IBM/Dromedary
SALMON在RLAIF的基础上优化了机器标注的部分,并给出了新的Reward模型的训练方案- Principle-Following Reward Model,背后其实也是用到了对比学习的思路。个人感觉这个思路更优的点在于,不直接让模型学习什么回答更好,什么回答更不好,因为好和不好的判定更容易陷入reward hacking,相反SALMON让模型学习每个具体的好和不好的偏好标准的表征。
先说偏好样本标注,同样是基于SFT模型采样两个候选回答,在使用大模型进行偏好标注时,SALMON对偏好进行了更为细致的拆分,总结了小20条偏好标准,包括事实性,数值 敏感,时间敏感等等。论文没有把所有原则合并成一个prompt,而是每一条原则,都会让模型对两个候选回答进行独立打分,打分是回答A、B解码概率的对数之差。这里同样考虑了position bias,因此会swap位置求平均。prompt模板如下

通过以上的标注我们能得到prompt_i,responseiA,responseiB,princle_j, score_iaj, score_ibj的偏好样本。在RL模型训练时,SALMON没有像以上RLAIF直接使用soft label进行模型微调,而是采用了指令微调的方案,并引入了负向原则,例如非事实性,无用性等等,更全面的让Reward模型学习每一个偏好原则的具体表征。具体的指令样本构建方式如下
- 对所有正面 原则,构建对应的负面原则描述,以下为简洁性原则的正负面principle

- 输入:对每个prompt,采样3个原则,并对采样的原则进行随机反转。在以下的指令样本中,随机采样的principle分别是Concise ,Ethical和precise, 其中Eithical被随机反转成负面原则。

- 输出:如果responseA 和resposneB 对应以上3个原则 的打分分别是(2,3,6)和(1,5,5),这时选择AB打分差异最大的一个principle来决定最终的输出结果,这时分差最大的是Ethical Principle,又因为该原则被反转,因此模型的解码结果是该维度上得分更低的A。
最后使用以上构建的指令样本进行微调得到可以理解正负面偏好原则并对回答进行打分的Reward模型。
同样因为训练了Reward模型的Principle理解能力,在推理使用Reward模型时,论文指出可以通过动态调整上文principle来解决一些已经发现的reward hacking的问题,哈哈所谓头疼医头,脚疼医脚。最开始读到这个思路时觉得有点逗,后来训练发现时不时就会发现Reward模型存在各种奇葩Bias时,才发现能快速通过prompt修复一两个小问题真的很香,虽然不是终极解决方案,但胜在临时好用。针对三个发现的Reward hacking问题,论文分别在推理时加入了以下的新principle

说完RL训练策略优化,和样本标注优化,过几章我们接着说RL相关的对抗训练和训练过程优化方案~文章来源:https://www.toymoban.com/news/detail-843141.html
想看更全的大模型相关论文梳理·微调及预训练数据和框架·AIGC应用,移步Github >> DecryPrompt文章来源地址https://www.toymoban.com/news/detail-843141.html
到了这里,关于解密prompt系列25. RLHF改良方案之样本标注:RLAIF & SALMON的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!