在本篇文章中,爬虫的讲解不仅仅局限于爬虫本身,还会引申至另一个重要领域:数据分析。对我们而言,爬虫的核心价值实际上在于获取数据,一旦获得了数据,接下来必然是要加以利用。数据分析便是其中关键一环,因此在爬虫的讲解之后,我们将会稍作涉及与数据分析相关的知识要点。
今天主要任务是爬取全国消费数据,然后根据过去十年的数据进行深入分析,以便进行未来两年的消费预测。废话不多说,让我们直接开始吧。
全国消费数据
要获取全国的消费数据,最好前往国家数据统计局进行查询。因此,在使用爬虫时,应当谨慎操作,避免对服务器造成负荷过大的影响。在成功获取数据后,应当及时保存,而不是过度频繁地请求数据,以免导致服务器瘫痪。在开始分析页面之前,先确认所需的全国消费数据是否已被提供,然后按照常规操作,在页面下方进行搜索,以确定数据展示形式是静态页面还是通过ajax请求获取的。
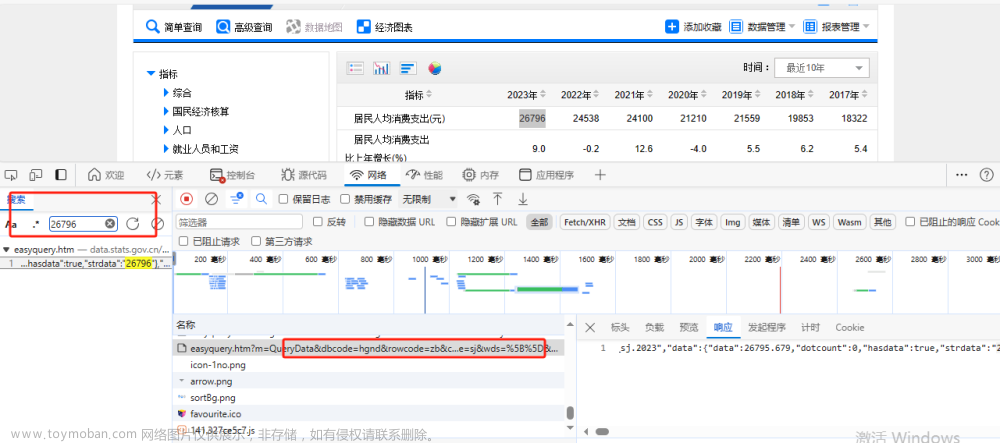
为什么在这里我搜索的是数字而非文字?这是因为该请求返回到浏览器时处于乱码状态,因此为了演示,我选择了数字作为示例,效果是一样的。一旦找到请求,处理起来就很简单了,我们只需复制URL,前往在线网站进行处理,然后将代码复制出来即可。如果在线网站有不清楚的地方,可以参考前几章的文章。
数据抓取
直接看下爬虫代码:
import requests
import re
strdata_code_map = {}
wdcode_name_map = {}
def get_data():
global strdata_code_map,wdcode_name_map
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Cookie': 'wzws_sessionid=oGX46GqAMTIzLjE3Mi40OS4yMDKBZDk0YTI3gmZjNWVlMQ==; u=6; experience=show; JSESSIONID=bANUmkmAc_F_FOy-dM-8VqxHEea-dpa39By6stbh14v9_aYXN7HM!1314454129',
'Referer': 'https://data.stats.gov.cn/easyquery.htm?cn=C01',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0',
'X-Requested-With': 'XMLHttpRequest',
'sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Microsoft Edge";v="122"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
params = {
'm': 'QueryData',
'dbcode': 'hgnd',
'rowcode': 'zb',
'colcode': 'sj',
'wds': '[]',
'dfwds': '[{"wdcode":"zb","valuecode":"A0A04"}]',
'k1': '1710816989823',
'h': '1',
}
response = requests.get('https://data.stats.gov.cn/easyquery.htm', params=params, headers=headers, verify=False)
# 解析JSON数据
response_data = response.json()
# 提取datanodes中的strdata和code映射数据列表
datanodes = response_data['returndata']['datanodes']
for node in datanodes:
input_str = node['code']
match = re.search(r'\.(\w+)_sj\.(\d+)', input_str)
if match:
part1 = match.group(1) # A0A0401
part2 = match.group(2) # 2023
if 'year' not in strdata_code_map:
strdata_code_map['year'] = []
if part2 not in strdata_code_map['year']:
strdata_code_map['year'].append(part2)
if part1 not in strdata_code_map:
strdata_code_map[part1] = []
strdata_code_map[part1].append(node['data']['strdata'])
print(strdata_code_map)
# 提取wdnodes中code和name映射列表
wdnodes = response_data['returndata']['wdnodes']
wdcode_name_map = {node['code']: node['name'] for node in wdnodes[0]['nodes']}
print(wdcode_name_map)
这段代码解析了返回的JSON数据,提取了datanodes中的数据节点和wdnodes中的维度节点信息。对于数据节点,通过正则表达式提取了每个节点的code属性,解析出数据节点对应的strdata和code映射关系,并将这些信息存储到strdata_code_map字典中。对于维度节点,将每个节点的code和name属性映射关系存储到wdcode_name_map字典中。
数据分析
拿到数据后,我们立即对其进行数据分析。一般来说,在数据分析项目中,我们会首先利用Pandas库加载数据,进行数据清洗和处理,然后使用Matplotlib库进行数据可视化,以便更深入地理解数据并有效展示结果。
不多说,直接看下代码:
import pandas as pd
import matplotlib.pyplot as plt
def get_now_plt():
data = {
'year': ['2023', '2022', '2021', '2020', '2019', '2018', '2017', '2016', '2015', '2014'],
'A0A0401': ['26796', '24538', '24100', '21210', '21559', '19853', '18322', '17111', '15712', '14491'],
'A0A0402': ['9.0', '-0.2', '12.6', '-4.0', '5.5', '6.2', '5.4', '6.8', '6.9', '7.5'],
'A0A0403': ['12114', '10590', '10645', '9037', '9886', '8781', '7803', '7157', '6460', '5842'],
'A0A0404': ['14.4', '-0.5', '17.8', '-8.6', '12.6', '12.5', '9.0', '10.8', '10.6', '11.4'],
'A0A0405': ['7983', '7481', '7178', '6397', '6084', '5631', '5374', '5151', '4814', '4494'],
'A0A0406': ['6.7', '4.2', '12.2', '5.1', '8.0', '4.8', '4.3', '7.0', '7.1', '8.9'],
'A0A0407': ['1479', '1365', '1419', '1238', '1338', '1289', '1238', '1203', '1164', '1099'],
'A0A0408': ['8.4', '-3.8', '14.6', '-7.5', '3.8', '4.1', '2.9', '3.3', '5.9', '7.0'],
'A0A0409': ['6095', '5882', '5641', '5215', '5055', '4647', '4107', '3746', '3419', '3201'],
'A0A040A': ['3.6', '4.3', '8.2', '3.2', '8.8', '13.1', '9.6', '9.6', '6.8', '6.7'],
'A0A040B': ['1526', '1432', '1423', '1260', '1281', '1223', '1121', '1044', '951', '890'],
'A0A040C': ['6.6', '0.6', '13.0', '-1.7', '4.8', '9.1', '7.4', '9.7', '6.9', '10.3'],
'A0A040D': ['3652', '3195', '3156', '2762', '2862', '2675', '2499', '2338', '2087', '1869'],
'A0A040E': ['14.3', '1.2', '14.3', '-3.5', '7.0', '7.1', '6.9', '12.0', '11.6', '14.9'],
'A0A040F': ['2904', '2469', '2599', '2032', '2513', '2226', '2086', '1915', '1723', '1536'],
'A0A040G': ['17.6', '-5.0', '27.9', '-19.1', '12.9', '6.7', '8.9', '11.2', '12.2', '9.9'],
'A0A040H': ['2460', '2120', '2115', '1843', '1902', '1685', '1451', '1307', '1165', '1045'],
'A0A040I': ['16.0', '0.2', '14.8', '-3.1', '12.9', '16.1', '11.0', '12.3', '11.5', '14.5'],
'A0A040J': ['697', '595', '569', '462', '524', '477', '447', '406', '389', '358'],
'A0A040K': ['17.1', '4.6', '23.2', '-11.8', '9.7', '6.8', '10.0', '4.4', '8.7', '10.3']
}
label = {
'A0A0401': '居民人均消费支出',
'A0A0402': '居民人均消费支出_比上年增长',
'A0A0403': '居民人均服务性消费支出',
'A0A0404': '居民人均服务性消费支出_比上年增长',
'A0A0405': '居民人均食品烟酒支出',
'A0A0406': '居民人均食品烟酒支出_比上年增长',
'A0A0407': '居民人均衣着支出',
'A0A0408': '居民人均衣着支出_比上年增长',
'A0A0409': '居民人均居住支出',
'A0A040A': '居民人均居住支出_比上年增长',
'A0A040B': '居民人均生活用品及服务支出',
'A0A040C': '居民人均生活用品及服务支出_比上年增长',
'A0A040D': '居民人均交通通信支出',
'A0A040E': '居民人均交通通信支出_比上年增长',
'A0A040F': '居民人均教育文化娱乐支出',
'A0A040G': '居民人均教育文化娱乐支出_比上年增长',
'A0A040H': '居民人均医疗保健支出',
'A0A040I': '居民人均医疗保健支出_比上年增长',
'A0A040J': '居民人均其他用品及服务支出',
'A0A040K': '居民人均其他用品及服务支出_比上年增长'
}
keys = list(data.keys()) # 获取所有键并转换为列表
need_keys = []
for i in range(1, len(keys), 2):
need_keys.append(keys[i])
# 数据
years = data['year']
# 绘制折线图
for key in range(0, len(need_keys), 2):
plt.plot(years, [int(x) for x in data[need_keys[key]]], label=label[need_keys[key]], marker='o')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.xlabel('年份')
plt.ylabel('消费支出(元)')
plt.title('全国居民人均支出情况')
plt.legend()
plt.grid(True)
plt.show()
get_now_plt()
为了保持代码的流畅性,我先复制了数据并定义了两个字典项,分别是label和data。字典label用于存储每种数据类型的中文标签,而字典data包含了各年份的不同消费支出数据,比如居民人均消费支出、居民人均服务性消费支出等。接着,我使用matplotlib.pyplot库来绘制折线图。在绘制过程中,我遍历了need_keys列表,为每种数据类型绘制相应的折线图,并添加了标签和数据点。
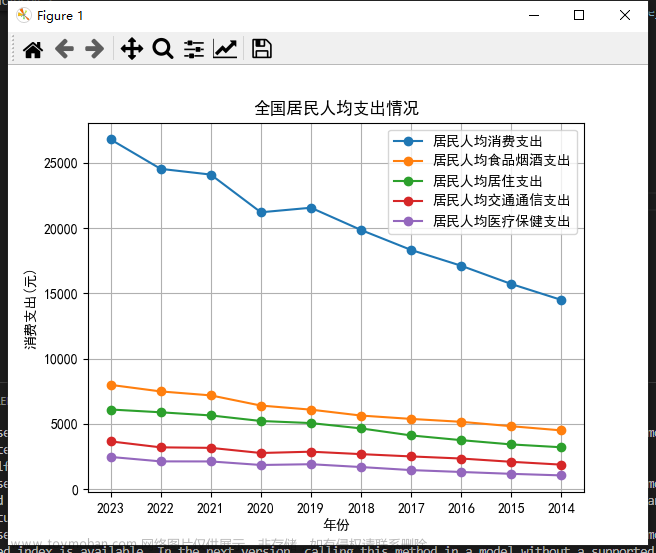
当处理数据时,请确保注意到,如果需要显示中文字符,您可能需要使用以下语句来设置字体以避免乱码:plt.rcParams['font.sans-serif'] = ['SimHei']。此外,请注意我存储的数据是按倒序排列的。
未来预测
当我们拥有近10年的数据时,实际上可以利用这些数据进行预测。在这方面有许多方法可供选择,今天我们将探讨ARIMA模型。ARIMA代表自回归(Autoregressive, AR)、差分(Integrated, I)和移动平均(Moving Average, MA)这三种技术的结合,是一种用于时间序列预测的统计模型。通过ARIMA模型,我们可以捕捉时间序列数据中的趋势、季节性变化和周期性变化。
在本章中,我们仅仅是提供了一些基础信息,希望能够引发你的兴趣,具体的内容将在后续的章节中详细展开。因此,接下来可以直接查看代码部分:
import requests
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA
import re
def get_feature_plt():
# 数据
data = {
'year': [2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022, 2023],
'A0A0403': [5842, 6460, 7157, 7803, 8781, 9886, 9037, 10645, 10590, 12114],
'A0A0405': [4494, 4814, 5151, 5374, 5631, 6084, 6397, 7178, 7481, 7983],
'A0A0407': [1099, 1164, 1203, 1238, 1289, 1338, 1238, 1419, 1365, 1479],
'A0A0409': [3201, 3419, 3746, 4107, 4647, 5055, 5215, 5641, 5882, 6095],
'A0A040B': [890, 951, 1044, 1121, 1223, 1281, 1260, 1423, 1432, 1526],
'A0A040D': [1869, 2087, 2338, 2499, 2675, 2862, 2762, 3156, 3195, 3652],
'A0A040F': [1536, 1723, 1915, 2086, 2226, 2513, 2032, 2599, 2469, 2904],
'A0A040H': [1045, 1165, 1307, 1451, 1685, 1902, 1843, 2115, 2120, 2460],
'A0A040J': [358, 389, 406, 447, 477, 524, 462, 569, 595, 697],
}
label = {
'A0A0401': '居民人均消费支出',
'A0A0402': '居民人均消费支出_比上年增长',
'A0A0403': '居民人均服务性消费支出',
'A0A0404': '居民人均服务性消费支出_比上年增长',
'A0A0405': '居民人均食品烟酒支出',
'A0A0406': '居民人均食品烟酒支出_比上年增长',
'A0A0407': '居民人均衣着支出',
'A0A0408': '居民人均衣着支出_比上年增长',
'A0A0409': '居民人均居住支出',
'A0A040A': '居民人均居住支出_比上年增长',
'A0A040B': '居民人均生活用品及服务支出',
'A0A040C': '居民人均生活用品及服务支出_比上年增长',
'A0A040D': '居民人均交通通信支出',
'A0A040E': '居民人均交通通信支出_比上年增长',
'A0A040F': '居民人均教育文化娱乐支出',
'A0A040G': '居民人均教育文化娱乐支出_比上年增长',
'A0A040H': '居民人均医疗保健支出',
'A0A040I': '居民人均医疗保健支出_比上年增长',
'A0A040J': '居民人均其他用品及服务支出',
'A0A040K': '居民人均其他用品及服务支出_比上年增长'
}
df = pd.DataFrame(data)
df.set_index('year', inplace=True)
need_keys = list(data.keys()) # 获取所有键并转换为列表
for i in range(1, len(need_keys), 3):
# 拟合ARIMA模型
model = ARIMA(df[need_keys[i]], order=(1, 1, 1)) # 根据数据特点选择合适的order
model_fit = model.fit()
# 进行未来预测
future_years = [2024,2025] # 假设预测未来两年
forecast = model_fit.forecast(steps=len(future_years))
# 可视化预测结果
plt.plot(df.index, df[need_keys[i]], label=label[need_keys[i]])
plt.plot(future_years, forecast, label='预测'+label[need_keys[i]], linestyle='--', marker='o')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.xlabel('年份')
plt.ylabel('消费支出(元)')
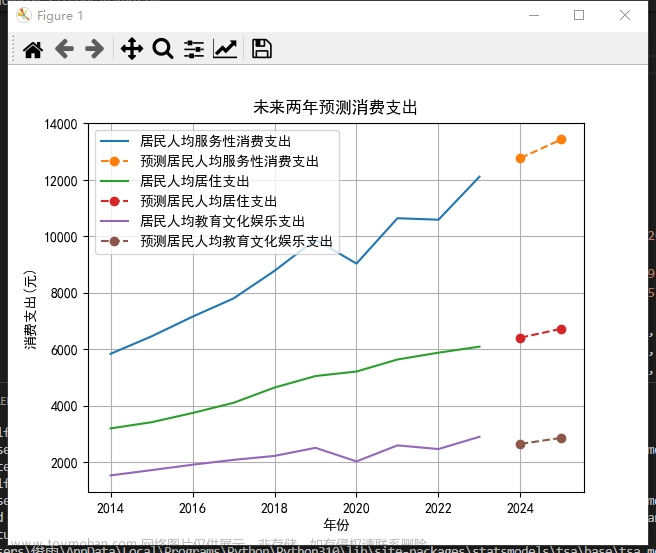
plt.title('未来两年预测消费支出')
plt.legend()
plt.grid(True)
plt.show()
在进行优化处理时,首先将暂存的数据转换为Pandas的DataFrame格式,并将年份设为索引。接着,从数据中提取所需的键名,对每三个键进行ARIMA模型的拟合和预测,随后通过可视化展示了消费支出随时间变化的趋势图,并呈现了未来两年的预测数据。
总结
完美收官,本文是爬虫实战的最后一章了,所以尽管本文着重呈现爬虫实战,但其中有一大部分内容专注于数据分析。爬虫只是整个过程的起点,其主要目的之一就是为后续数据分析等工作做好准备。通过对爬取的数据进行精确的清洗和分析,可以揭示其中隐藏的规律和趋势,为决策提供有力支持。因此,爬虫实战并不仅仅是技术的展示,更是对数据价值的挖掘和充分利用。文章来源:https://www.toymoban.com/news/detail-843146.html
还有一点需要特别强调的是,绝对不能利用这种方式从中谋取个人利益,比如搭建爬虫网站等手段,这些行为是违法的。我想再次强调,在进行爬虫操作时一定要遵守相关法律法规,尽量以学习为主,切勿触犯法律。文章来源地址https://www.toymoban.com/news/detail-843146.html
到了这里,关于爬虫实战+数据分析:全国消费支出分析及未来预测的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!