一、实验目的
1、熟悉 Spark 的 RDD 基本操作及键值对操作;
2、熟悉使用 RDD 编程解决实际具体问题的方法
二、实验平台
1、Scala 版本为 2.11.8。
2、操作系统:linux(推荐使用Ubuntu16.04)。
3、Jdk版本:1.7或以上版本。
三、实验内容
1.spark-shell 交互式编程
请到本教程官网的“下载专区”的“数据集”中下载 chapter5-data1.txt,该数据集包含了某大学计算机系的成绩,数据格式如下所示:
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algorithm,60
Jim,DataStructure,80
……
请根据给定的实验数据,在 spark-shell 中通过编程来计算以下内容:
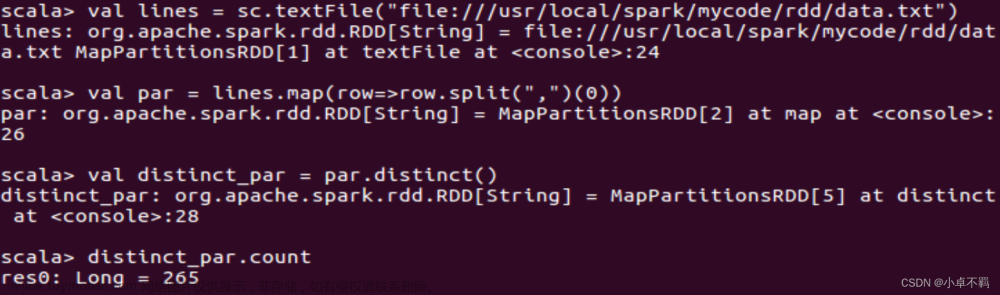
(1)该系总共有多少学生;
val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/data.txt")
val par = lines.map(row=>row.split(",")(0))
val distinct_par = par.distinct()
distinct_par.count
(2)该系共开设来多少门课程;
代码如下:
val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/data.txt")
val par = lines.map(row=>row.split(",")(1))
val distinct_par = par.distinct()
distinct_par.count

(3)Tom 同学的总成绩平均分是多少;
代码如下:
val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/data.txt")
val pare = lines.filter(row=>row.split(",")(0)=="Tom")
pare.foreach(println)
pare.map(row=>(row.split(",")(0),row.split(",")(2).toInt)).mapValues(x=>(x,1)).reduceByKey((x,y
) => (x._1+y._1,x._2 + y._2)).mapValues(x => (x._1 / x._2)).collect()
 (4)求每名同学的选修的课程门数;
(4)求每名同学的选修的课程门数;
代码如下:
val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/data.txt")
val pare = lines.map(row=>(row.split(",")(0),row.split(",")(1)))
pare.mapValues(x => (x,1)).reduceByKey((x,y) => (" ",x._2 + y._2)).mapValues(x =>
x._2).foreach(println)

(5)该系 DataBase 课程共有多少人选修;
代码如下:
val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/data.txt")
val pare = lines.filter(row=>row.split(",")(1)=="DataBase")
pare.count

(6)各门课程的平均分是多少;
代码如下:
val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/data.txt")
val pare = lines.map(row=>(row.split(",")(1),row.split(",")(2).toInt))
pare.mapValues(x=>(x,1)).reduceByKey((x,y) => (x._1+y._1,x._2 + y._2)).mapValues(x => (x._1 / x._2)).collect()

(7)使用累加器计算共有多少人选了 DataBase 这门课。
代码如下:
val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/data.txt")
val pare = lines.filter(row=>row.split(",")(1)=="DataBase").map(row=>(row.split(",")(1),1))
val accum = sc.longAccumulator("My Accumulator")
pare.values.foreach(x => accum.add(x))
accum.value

2.编写独立应用程序实现数据去重
对于两个输入文件 A 和 B,编写 Spark 独立应用程序,对两个文件进行合并,并剔除其
中重复的内容,得到一个新文件 C。下面是输入文件和输出文件的一个样例,供参考。
输入文件 A 的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件 B 的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件 A 和 B 合并得到的输出文件 C 的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
sacla代码:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.spark.HashPartitioner
object task1 {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("task2_1")
val sc = new SparkContext(conf)
val dataFile = "file:///home/hadoop/input1/A.txt,file:///home/hadoop/input1/B.txt"
val res = sc.textFile(dataFile,2) .filter(_.trim().length>0).map(line=>(line.trim,"")).partitionBy(new
HashPartitioner(1)).groupByKey().sortByKey().keys
res.saveAsTextFile("file:///home/hadoop/output1/result")
}
}
simple.sbt代码:
name := "RemDup"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"

3.编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生
名字,第二个是学生的成绩;编写 Spark 独立应用程序求出所有学生的平均成绩,并输出到
一个新文件中。下面是输入文件和输出文件的一个样例,供参考。
Algorithm 成绩:
小明 92
小红 87
小新 82
小丽 90
Database 成绩:
小明 95
小红 81
小新 89
小丽 85
Python 成绩:
小明 82
小红 83
小新 94
小丽 91
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
sacla代码:
import org.apache.spark.SparkConf
import org.apache.spark.HashPartitioner
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
object task2 {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("AvgScore")
val sc = new SparkContext(conf)
val dataFile = "file:///home/hadoop/input1/Algorithm.txt,file:///home/hadoop/input1/Database.txt,file:///home/hadoop/input1/Python.txt"
val data = sc.textFile(dataFile,3)
val res = data.filter(_.trim().length>0).map(line=>(line.split(" ")(0).trim(),line.split(" ")(1).trim().toInt)).partitionBy(new HashPartitioner(1)).groupByKey().map(x => {
var n = 0
var sum = 0.0
for(i <- x._2){
sum = sum + i
n = n +1
}
val avg = sum/n
val formattedAvg = f"$avg%1.2f".toDouble
(x._1, formattedAvg)
})
res.saveAsTextFile("file:///home/hadoop/output2/result")
}
}
simple.sbt代码:文章来源:https://www.toymoban.com/news/detail-843193.html
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"

 文章来源地址https://www.toymoban.com/news/detail-843193.html
文章来源地址https://www.toymoban.com/news/detail-843193.html
到了这里,关于【Spark编程基础】实验三RDD 编程初级实践(附源代码)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!









