概要
基于QuantConnect的开源Lean引擎,生成本地数据源,并实现运行Python语言的Fama-French五因子策略
开发环境
- VS2022企业版,需要安装C#和Python组件;
- Anaconda3-2020.11-Windows-x86_64,这个版本对应Python3.8,是根据Lean环境要求选择的;
- git clone https://github.com/QuantConnect/Lean.git下载的Lean框架;
操作流程
- VS2022打开Lean工程,F5运行一遍进行Nuget包还原;
- Anaconda安装时需要选中注册环境变量,安装好后,pip install quantconnect-stubs安装包;
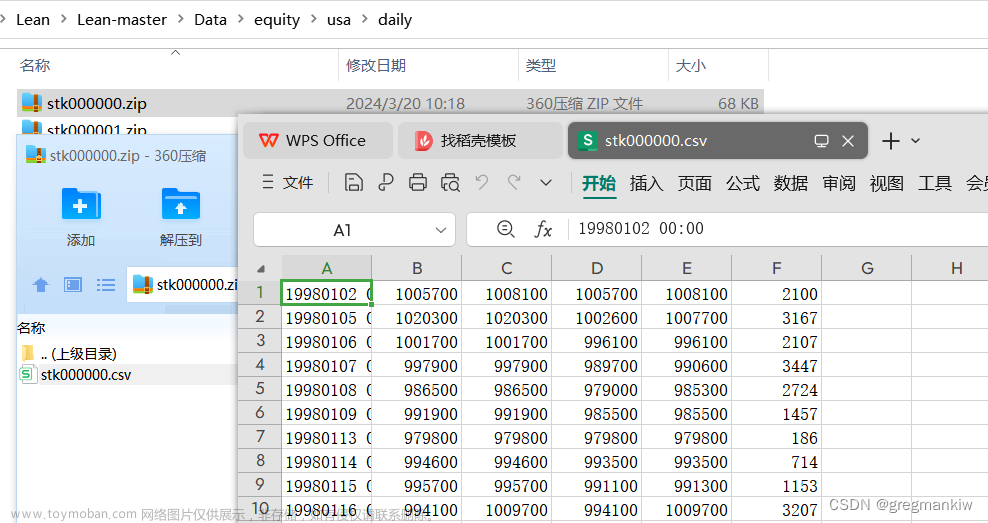
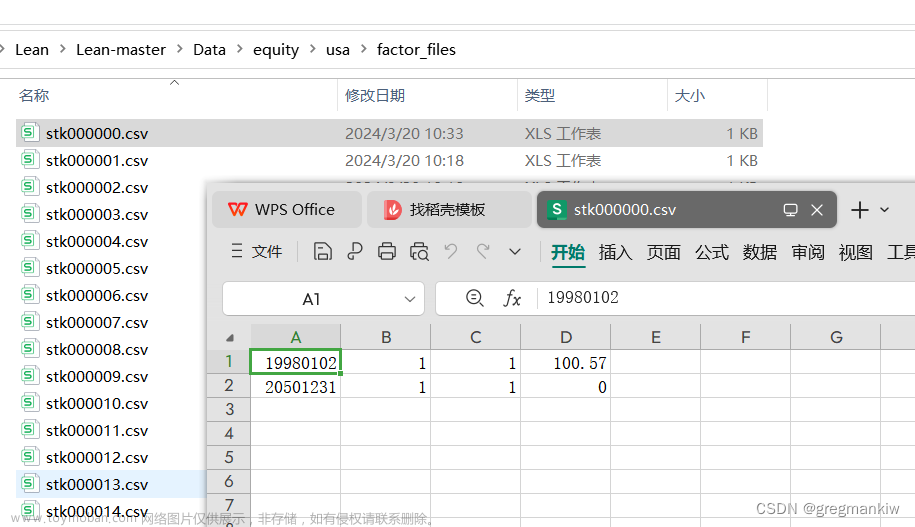
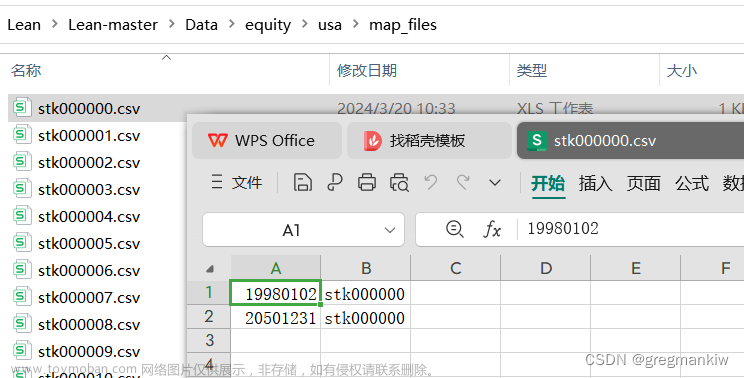
- Data\equity\usa下将daily、factor_files、fundamental、map_files文件夹清空自带Symbol;
- ToolBox\RandomDataGenerator下修改生成指定格式的Symbol;
public IEnumerable<Symbol> GenerateRandomSymbols()
{
if (!Settings.Tickers.IsNullOrEmpty())
{
foreach (var symbol in Settings.Tickers.SelectMany(GenerateAsset))
{
yield return symbol;
}
}
else
{
for (var i = 0; i < Settings.SymbolCount; i++)
{
//生成stk000000,stk000001,...stk000999格式的证券符号
var ticker = "stk" + i.ToString().PadLeft(6, '0');
var symbol = Symbol.Create(ticker, Settings.SecurityType, Settings.Market);
yield return symbol;
//foreach (var symbol in GenerateAsset())
//{
// yield return symbol;
//}
}
}
}
- QuantConnect.ToolBox项目设为启动项目,属性-调试-常规-打开调试启动配置文件UI-启动配置文件-命令行参数,进行配置后F5运行生成1000个证券数据;
--app=rdg
--start=19980101
--end=20240319
--symbol-count=1000
--resolution=Daily
--random-seed=123456
--rename-percentage=0.0
--ipo-percentage=0.0
--splits-percentage=0.0
--dividends-percentage=0.0
--dividend-every-quarter-percentage=0.0
 文章来源:https://www.toymoban.com/news/detail-843302.html
文章来源:https://www.toymoban.com/news/detail-843302.html
5.目录\ToolBox\CoarseUniverseGenerator\CoarseUniverseGeneratorProgram.cs下语句修改成var hasFundamentalData = true; 目录\Common\Data\UniverseSelection\CoarseFundamentalDataProvider.cs下语句修改成return coarse.HasFundamentalData;项目属性–app=rdg修改为cug然后F5生成基本面Fundamental的股票池Universe数据;文章来源地址https://www.toymoban.com/news/detail-843302.html
private static CoarseFundamental GenerateFactorFileRow(string ticker, SecurityIdentifierContext sidContext, CorporateFactorProvider factorFile, TradeBar tradeBar)
{
var date = tradeBar.Time;
var factorFileRow = factorFile?.GetScalingFactors(date);
var dollarVolume = Math.Truncate((double)到了这里,关于基于QuantConnect开源引擎Lean本地实现Fama-French五因子Python策略的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!