原作:Jason Wei
引言:此博客文章不代表我的雇主OpenAI的立场(过去、现在或未来)。
/Gemini翻译/
我将回顾在讨论大型语言模型的涌现能力时出现的一些常见论点。去年,我们撰写了一篇立场文件,将涌现能力定义为“小语言模型中不存在但在大语言模型中存在的能力”。我表明了涌现能力广泛存在,并且它们因以下几个原因而引人注目:
-
仅仅通过推断较小模型的缩放曲线,无法预测涌现。
-
语言模型的训练者并未明确指定涌现能力(仅限“预测下一个单词”)。
-
由于我们尚未测试所有可能的任务,因此我们不知道已经涌现出的能力的全部范围。
-
可以预期进一步的扩展将引发更多涌现能力。
自 GPT-4 以来,一些人认为涌现被夸大了,甚至是一种“海市蜃楼”。我认为这些论点并不能令人信服地揭穿涌现现象,但它们值得讨论,而且用怀疑的眼光审视科学现象是件好事。我将尝试以最强有力的形式重述它们,然后解释我对它们的思考。
涌现取决于评估指标
论点:涌现能力通常出现在“hard”评估指标中,例如精确匹配或多项完全匹配,这些指标不会对部分正确的答案给予奖励。例如,多步算术要求每一步都正确——即使失败一步也可能导致错误的答案。如果你采用相同的任务,但使用“软”评估指标,例如正确目标的对数概率,你可能会发现随着时间的推移,性能平稳提高,而没有性能上的大幅跃升。
多篇论文对此提供了证据——BIG-Bench 论文表明,目标的对数概率在各个尺度上平稳提高(“突破性行为对任务规范的细节很敏感”中的图 9),并且还表明,在加法或乘法上使用令牌编辑距离之类的度量标准似乎会平稳提高,而不是像在使用完全匹配时看到的那样以涌现方式提高。
Response: 虽然有证据表明,在精确匹配下看起来涌现的一些任务在另一个度量标准下性能平稳提高,但我认为这并不能反驳涌现的重要性,因为精确匹配之类的度量标准是我们最终希望针对许多任务进行优化的。考虑询问 ChatGPT 15 + 23 是多少——您希望答案是 38,而不是其他任何内容。也许 37 比 -2.591 更接近 38,但为该答案分配一些部分分数似乎无助于测试执行该任务的能力,并且如何分配它将是任意的。专注于最能衡量我们关心的行为的指标很重要,因为基准本质上是研究人员的“优化函数”。
然而,值得注意的是,如果找到一个平稳改进的“替代”指标非常重要,因为它提供了更多信息,使我们能够预测更重要的紧急指标。不过,我还没有看到任何实质性证据表明可以使用平滑替代指标来预测完全匹配或多项选择性能。在我们的论文中,我们表明交叉熵损失甚至在小模型规模上也有所改善,其中下游指标接近随机且没有改善,这表明目标序列的对数似然性的改进可能会被此类下游指标掩盖。但此分析并未使我们能够仅使用较小的模型来预测紧急性能。
目前尚不清楚替代指标是否可以预测精确匹配或多项选择等指标的出现。例如,给定一堆小模型的准确性和交叉熵损失,你能否预测大模型的交叉熵损失,然后将其映射到出现的精确匹配性能?人们可能会期望,如果替代指标上存在平滑的缩放曲线,那么最终会出现下游指标的出现,但这种关系在预测出现时间和准确性方面尚未得到充分的研究。
最后,我想强调的是,在某些任务的某些指标上表现出平滑性并不意味着这种情况会发生在所有任务上。本文中的两个示例如下。
此处,修改后的算术的交叉熵损失略微平滑,但对于 IPA 音译,交叉熵损失中仍然存在一个很大的扭结,打破了趋势并且难以预测:
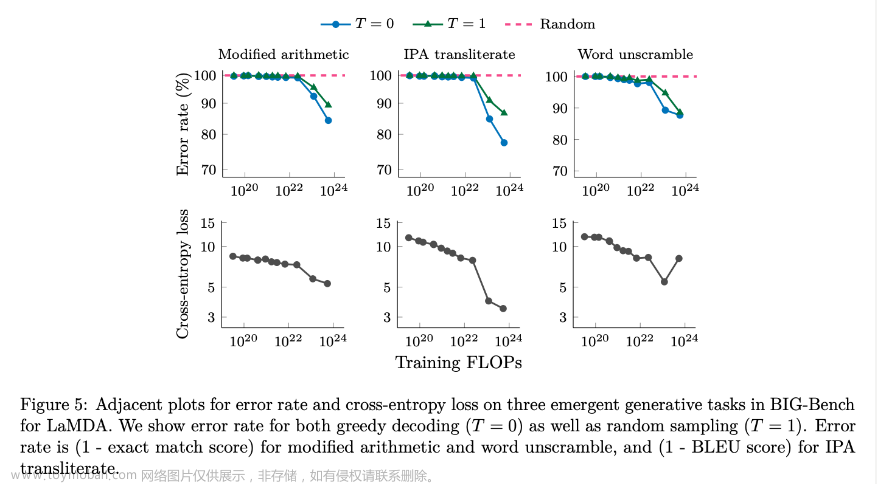
在这里,我们可以提取 BIG-Bench 中可用的多个指标,这些指标会授予一些部分学分,并且我们看到性能仍然在相同的阈值处急剧增加:

涌现是缩放曲线图的伪像
参数 (Argument ): 针对出现情况缩放绘图使用对数刻度 x 轴,如果您使用线性 x 轴刻度,绘图的形状将是平滑的。
回复(Response):仍然可以在线性 x 轴刻度上查看涌现。我在下面绘制了我们涌现论文中的图 2A,你仍然会看到从 7B 到 13B 的相同涌现峰值(尽管以不太可读的方式)。

除了证据表明出现仍然可以在线性范围内查看之外,默认情况下使用对数刻度 x 轴是合理的,因为我们训练的模型以指数方式更大。例如,PaLM 模型大小为 8B → 62B → 540B(8 倍),而 LaMDA 模型大小增加 2 倍。因此,对数刻度适用于传达我们在实践中如何缩放模型(并且这已经在文献中进行了多年的研究)。
论点:本文隐含地声称,我们应该能够将线性曲线拟合到具有 log-x 和线性-y 轴的图上。为什么我们不应该拟合指数或其他曲线?
回复:绘制对数 x 和对数 y 缩放曲线也很有意义,对数 y 缩放曲线上的错误率而不是准确度(因为准确度通常为 0,而 log(0) 为负无穷大)。然而,即使你这样做,曲线的形状也保持不变。

涌现是 x 轴上模型数据点不足的产物
论点 [1]:这种涌现的定义(较大模型的行为无法从较小模型中预测)在某种意义上必须过于强烈——如果你对 x 轴(参数数量)进行足够密集的采样,那么准确性的提高肯定应该是连续的或平滑的?例如,一个拥有 1,000,000 个参数的模型不太可能具有 50%(随机)的准确性,而一个拥有 1,000,001 个参数的模型将具有 90% 的准确性。
回复:虽然从理论上来说这是一个合理的观点,但实际上我们没有如此精细的模型大小。但假设我们确实有,并且如果你足够放大,准确性的提高将是平滑的,我仍然认为有一个显着的现象——对于低于某个特定参数阈值的模型,模型的性能是平坦的,然后在某个阈值以上它开始增加,并且外推平坦点无法使我们预测性能的提高。
请注意,对于大多数任务来说,这个定义对于足够小的 N 来说是无趣的(例如,具有一个或两个参数的模型将具有随机性能),因此正如 Tal Linzen 所建议的,指定一个特定的 N 阈值可能是好的,尽管我认为没有多少人会提出这个异议。总体而言,虽然某些行为非常可预测(例如,可以通过计算量少于 1,000 倍的模型预测 GPT-4 在某些评估中的损失),但其他行为即使计算量减少 2 倍也无法预测。这两种类型行为之间的差异是天壤之别。
最后一点
虽然保持普遍怀疑态度通常是好的,但似乎有大量证据表明新兴能力(对我来说)使其成为一种令人信服的现象和框架。即使某些新兴能力是噪音造成的,许多其他实例也非常可靠。考虑 U 形缩放和 GPT-4 论文中的以下图表:性能实际上会随着多个模型规模的减小而降低,直到突然激增。这是一个很好的涌现示例,我怀疑更改指标或可视化会使它看起来平滑或可预测。

另一个流行的涌现示例也强调了模型中的定性变化,即思维链提示,对于小模型而言,其性能比直接回答差,但比大模型直接回答好得多。直观地说,这是因为小模型无法产生扩展的推理链,最终会让自己感到困惑,而较大的模型可以以更可靠的方式进行推理。

总体而言,我很高兴新兴能力的想法正在被更多地讨论,人们正在质疑它。我特别对能够使我们预测新兴行为的工作感到兴奋,因为新兴现象既包括风险,也包括能力。我很乐意在推特上或在下次会议上与您进行更多讨论!文章来源:https://www.toymoban.com/news/detail-843492.html
感谢 Tatsunori Hashimoto、Percy Liang 和 Rishi Bommasani 提供有益的讨论(并且针对此博客的任何批评都应针对我,而不是他们)。文章来源地址https://www.toymoban.com/news/detail-843492.html
到了这里,关于【译】关于涌现能力的常见论点的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





![[论文阅读] (30)李沐老师视频学习——3.研究的艺术·讲好故事和论点](https://imgs.yssmx.com/Uploads/2024/02/478901-1.png)