DiffSpeaker: 使用扩散Transformer进行语音驱动的3D面部动画
code:GitHub - theEricMa/DiffSpeaker: This is the official repository for DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer
paper:https://arxiv.org/pdf/2402.05712.pdf
出处:香港理工大学,HKISI CAS,CASIA,2024.2
1. 介绍
语音驱动的3D面部动画,可以用扩散模型或Transformer架构实现。然而它们的简单组合并没有性能的提升。作者怀疑这是由于缺乏配对的音频-4D数据,这对于Transformer在扩散框架中充当去噪器非常重要。
为了解决这个问题,作者提出DiffSpeaker,一个基于Transformer的网络,设计了有偏条件注意模块,用作传统Transformer中自注意力/交叉注意力的替代。融入偏置,引导注意机制集中在相关任务特定和与扩散相关的条件上。还探讨了在扩散范式内精确的嘴唇同步和非语言面部表情之间的权衡。
总结:提出了一种将Transformer架构与基于扩散的框架集成的新方法,特点是一个带偏置的条件自注意/交叉注意机制,解决了用有限音频- 4d数据训练基于扩散的transformer的困难。能够并行生成面部动作,推理速度很快。
2. 背景
条件概率模型:学习语音和面部运动之间的概率映射,为语音驱动的3D面部动画提供了一种有效方法。目前的技术仍然倾向于在简短的片段中创建面部动画,严重依赖于GRU的顺序处理能力[Cho等人,2014]或卷积网络,导致在处理上下文方面表现差,不如Transformer。
Transformer架构整合到扩散框架的困难:需要在整个长度范围内对面部运动序列进行降噪,这对于数据密集型注意力机制来说要求很高。
语音驱动的3D面部动画,从音频语音输入中生成逼真的面部动作,需要同步捕捉语音的音调、节奏和动态。之前的工作遵循确定性映射的范式,即一个音频对应一个面部动作。比如:制定将语音(音素)与面部运动(视素)联系起来的人工规则,并使用系统测量音素对视素的影响。最近的研究认识到任务中固有的一对多关系,一个语音输入可以对应多个面部动作。CodeTalker 使用量化码本学习这种复杂的数据分布,显著提高了性能。
扩散模型的概率映射:FaceDiffuser 采用基于扩散的生成框架和GRU来单独处理音频段。扩散模型也被应用于头部姿势的并发生成[Park等人,2023;Sun等人,2023],对个人用户的定制[Thambiraja等人,2023],以及扩散蒸馏[Chen等人,2023a]等方法来加速生成过程。一些并行研究[Park and Cho, 2023;Aneja等,2023;Zhao等人,2024]专注于自定义数据集的混合形状级动画。
3. 方法
将语音驱动的三维面部动画作为一个条件生成问题,目标是通过从后验分布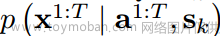 中采样,基于语音a1:T和第k个人的说话风格sk,生成面部运动x1:T,包含V个顶点的模板面网格上的一个顶点序列x i∈R T×V×3。ai∈RD是一个音频片段,只产生一帧运动。说话风格sk∈RK是一个one-hot嵌入,表示K个人物。n越大表示xn中的高斯噪声越多,xn为纯高斯噪声,x0为期望的面部运动。马尔可夫链依次将高噪声xn转换为低噪声版本,直到得到面部运动分布:
中采样,基于语音a1:T和第k个人的说话风格sk,生成面部运动x1:T,包含V个顶点的模板面网格上的一个顶点序列x i∈R T×V×3。ai∈RD是一个音频片段,只产生一帧运动。说话风格sk∈RK是一个one-hot嵌入,表示K个人物。n越大表示xn中的高斯噪声越多,xn为纯高斯噪声,x0为期望的面部运动。马尔可夫链依次将高噪声xn转换为低噪声版本,直到得到面部运动分布:

其中 。目标是得到
。目标是得到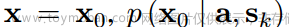 。为了在a和sk的指导下,从p(xn)推断出低噪分布p (xn−1),取神经元网络G,表达式为:
。为了在a和sk的指导下,从p(xn)推断出低噪分布p (xn−1),取神经元网络G,表达式为:
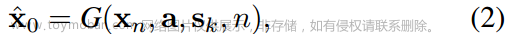
G作为去噪器,根据音频a、说话风格sk和扩散步长n,从xn中恢复面部运动x0。然后使用x0来构造马尔可夫链下一步的分布p(xn−1)。即DDIM过程,构造了相对较短的马尔可夫链,实现高效生成。
3.1 Diffusion-based Transformer Architecture
接下来介绍如何将语音a、风格sk和扩散步骤n的条件合并到Transformer体系结构中:网络g采用编码器-解码器架构,如图2所示,条件分别由Ea、Es、En编码,并提供给解码器D,解码器D对输入进行去噪:

音频编码器ea = ea (a 1:T)∈RT×C是预训练的音频编码器,样式编码器es = es (sk)∈R1×C是线性投影层,步进编码器en = en (n)∈R1×C首先将标量n转换为频率编码,然后将其传递给线性层。重要的是,网络G并行处理所有帧步长t ={1,···,t},但在扩散步长n中发生变化。

图2:DiffSpeaker利用基于扩散的迭代去噪技术,从语音音频a 1:T和说话风格sk合成面部运动x 1:T。核心特征是带偏置的条件注意机制,该机制在自我/交叉注意中引入静态偏置,并采用编码和en来整合说话风格和扩散步骤信息。
Attention with Condition Tokens
将说话风格条件和扩散步骤融入自注意力和交叉注意力层中。传统的自注意机制使面部动作序列能够自我反映,而交叉注意机制整合了条件输入。假设面部运动输入xn是噪声输入的,为了准确处理运动,自注意力必须是扩散步长感知的,用n表示。由于步骤编码 en 和风格编码 es 都是一维嵌入,可以同时将它们引入作为条件标记到自注意力和交叉注意力层中。采用标准的Transformer架构,自注意力层(As)和交叉注意力层(Ac)的输出计算如下:
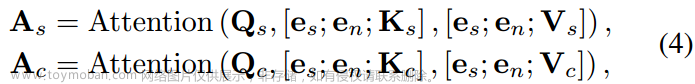
Qs、Ks、Vs∈R ×C表示自注意,Qc、Kc、Vc∈R T ×C表示交叉注意。方括号表示沿着序列维度进行连接。引入注意机制之前,风格编码e和步骤编码en被附加在键特征之后。
Static Attention Bias
为自注意和交叉注意机制引入了固定偏差,这些机制是专门为使用条件令牌而设计的。将包含条件令牌和静态偏差的注意操作称为有偏差条件注意。考虑长度为T的输入序列,计算第i个查询qi∈R1×C的注意分数,K对应Ks或Kc,注意得分计算如下:
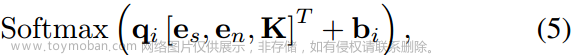
bi表示自注意或交叉注意机制的唯一偏差项。
Biased Conditional Cross-Attention.
交叉注意机制促进了面部动作序列与相关条件之间的交互,包括语音表征、风格编码和扩散步长编码。对于大小为T × (T + 2)的特征图,包括T个面部运动标记和2个附加条件标记,对于第i个查询,将bi(j)表示为第j个值的注意偏差,j的范围从1到T + 2。交叉注意偏差:

如图2所示,该设计的设置使特定帧的面部运动仅限于与其相应的语音表示以及es和en相关联。这一约束确保了音频信息的及时同步传递,同时还包含了有关扩散步骤和说话风格的信息。
Biased Conditional Self-Attention.在形状为T × (T + 2)的自注意映射中,偏差bi(j)表示为:
p表示与面部运动序列的帧速率相等的常数。如图2所示,对于最接近对角线的2p元素,这种一致的偏差为零,并随着与对角线的距离增加而减小。这种偏置通过将自我注意限制在一个集中的范围内,减轻了面部运动序列中噪声的破坏性影响。

3.2 Training Objective
训练如图2,包括预训练的音频编码器,目标是从任意扩散步骤n∈{1,···,n}中恢复原始信号。对于从数据集中采样的任意a, sk, x0,用以下损失来监督恢复的x = G(xn, a, sk, n):
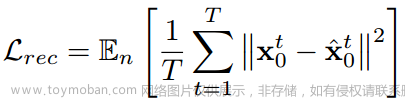
还使用速度损失来解决抖动,并平滑运动:

总体损失为两者和:

λ1 = λ2 = 1。
4. 实验
4.1 Datasets and Implementations
两个开源3D面部数据集BIWI和VOCASET进行训练和测试。这两个数据集都有4D面部扫描以及短句的录音。
BIWI数据集包含14名受试者(8名女性和6名男性)所说的40个句子的音频。每个主题将每个句子说两次——一次充满感情,一次中立。每句话记录的平均时间为4.67秒。记录以每秒25帧的速度捕获,每个3D面部扫描帧有23370个顶点。
VOCASET数据集包含从12个受试者中捕获的480对音频和3D面部运动序列。面部运动序列以每秒60帧的速度记录,长度约为4秒。VOCASET中的3D人脸网格注册到FLAME拓扑,每个网格有5023个顶点。
4.2 Implementation Detail
网络体系结构
Transformer模型,包括512维的隐藏层,1024维的前馈网络,4个头的多头注意和一个Transformer块。Transformer中的自注意/交叉注意用残差连接。对于BIWI数据集的实验[Fanelli et al ., 2010],它提供了更复杂的数据,通过将隐藏状态维数增强到1024,前馈网络维数增强到2048,模型进行了缩放,其他配置与VOCASET中概述的配置保持一致。
训练
用PyTorch框架和Nvidia V100 gpu开发。在VOCASET数据集上训练,批处理大小32,并在单个V100 GPU上运行训练大约24小时。BIWI数据集训练分布在8个V100 GPU上,每个GPU处理32个批处理大小,总训练时间为12小时。采用AdamW优化算法,学习率0.0001。

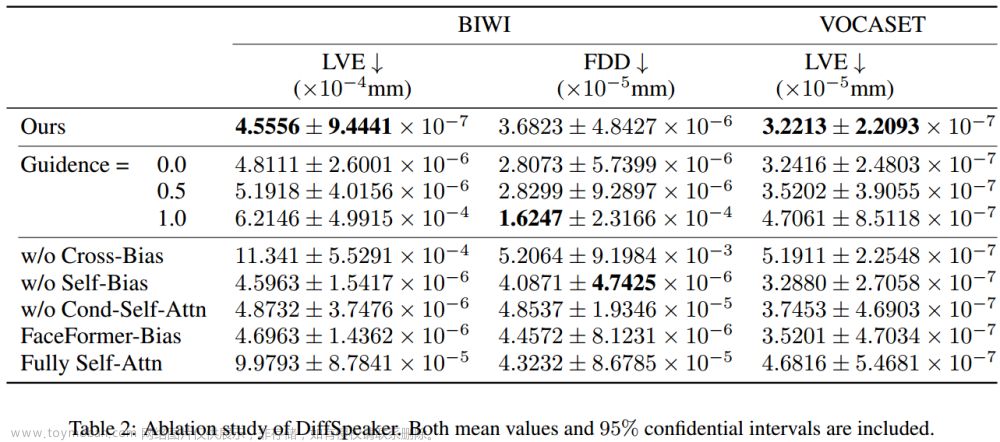
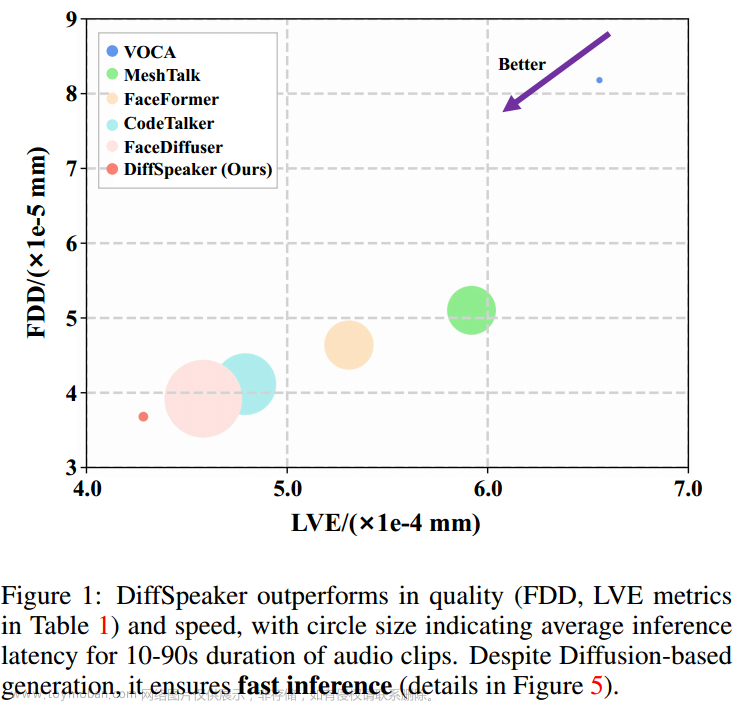
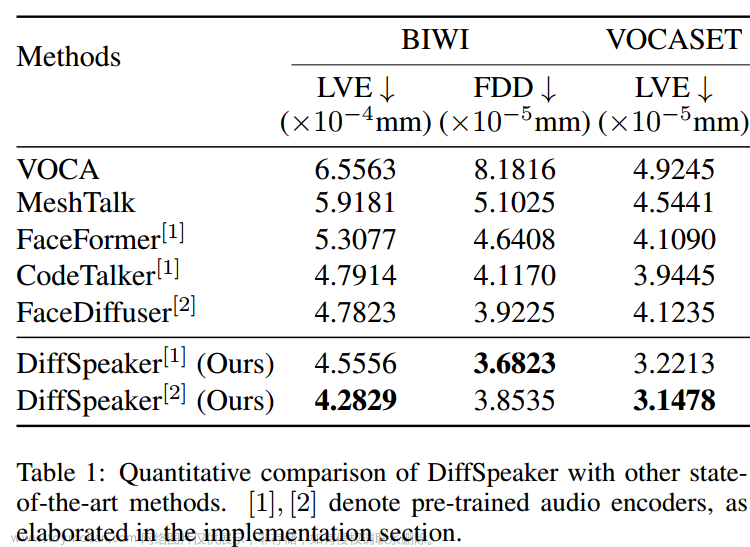
尽管人们普遍认为基于扩散的方法速度较慢,但我们的语音驱动3D面部动画方法证明了比大多数现有替代方法更快的推理速度。在3090 GPU上测量了不同长度的音频的延迟,图5中的结果显示,我们的方法在10秒以上的音频上优于除VOCA之外的所有其他方法。
由于使用了固定的去噪迭代,无论音频长度如何,这种速度优势在较长的音频剪辑中更明显。与并行处理所有音频窗口的VOCA不同,其他方法依赖于顺序地关注前面的片段以进行后续预测,从而导致扩展音频的迭代增加。文章来源:https://www.toymoban.com/news/detail-843714.html
 文章来源地址https://www.toymoban.com/news/detail-843714.html
文章来源地址https://www.toymoban.com/news/detail-843714.html
到了这里,关于【论文阅读】DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





![[论文阅读]Multimodal Virtual Point 3D Detection](https://imgs.yssmx.com/Uploads/2024/02/778145-1.png)




