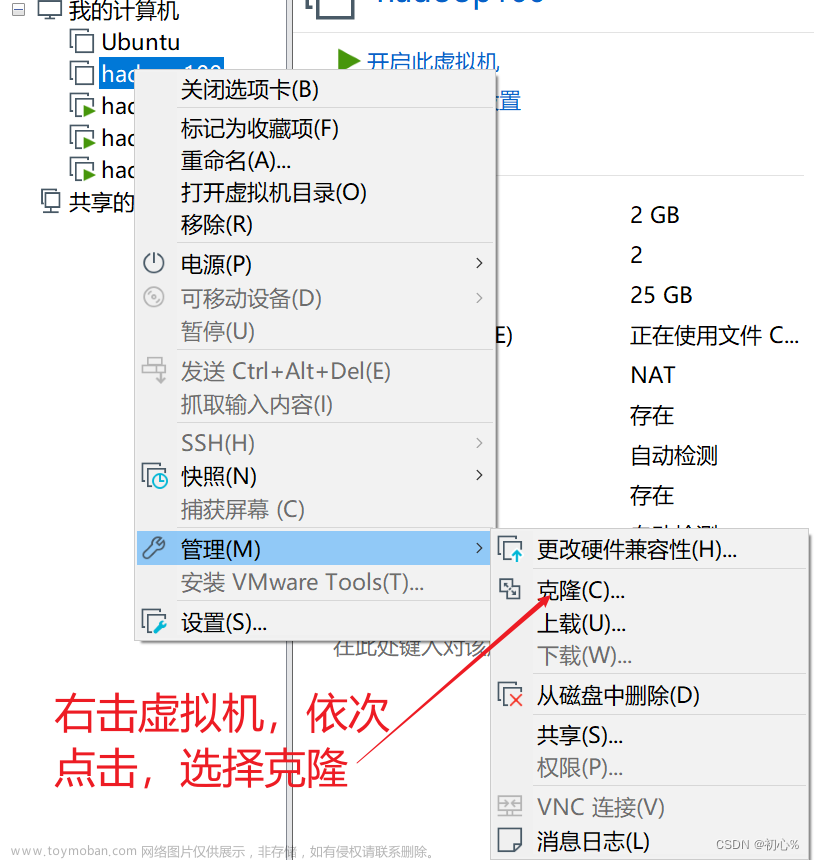
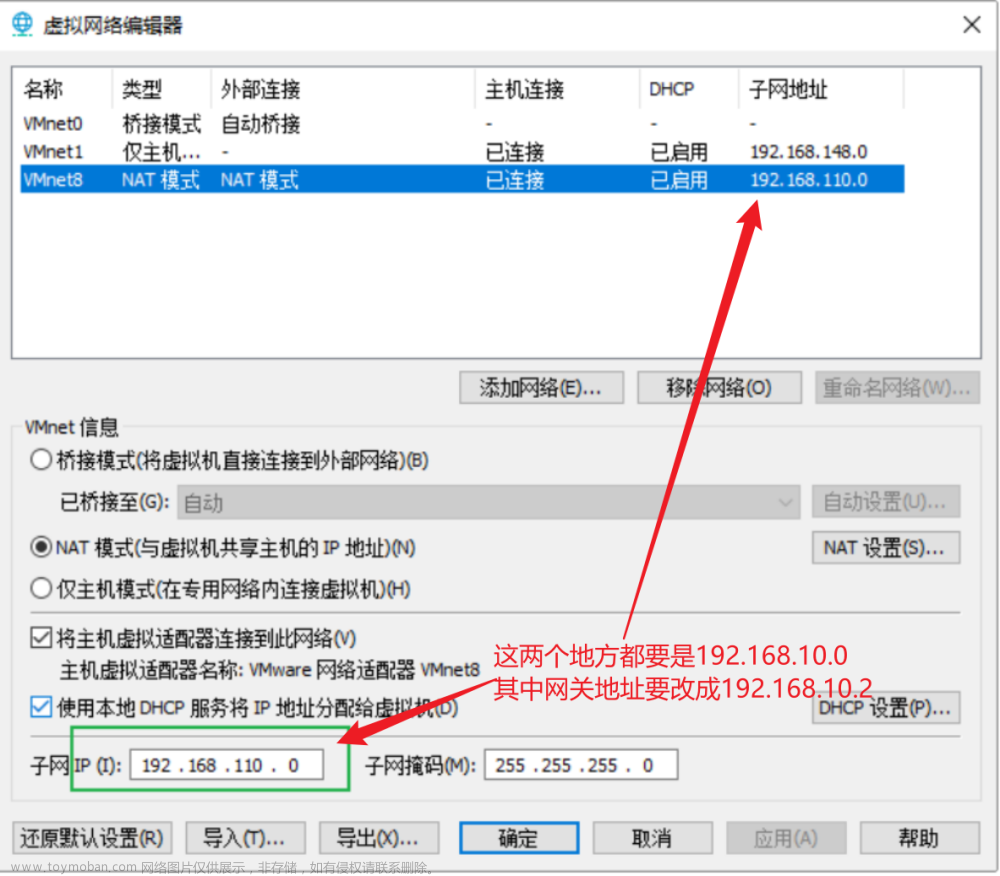
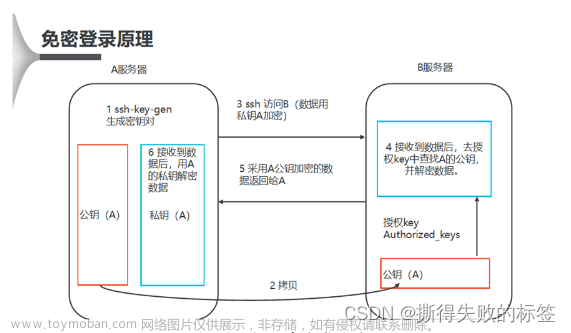
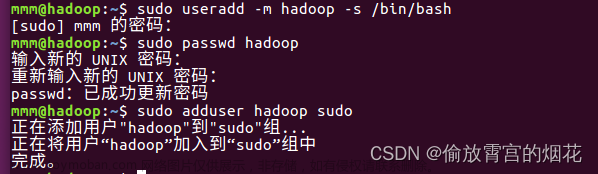
vi /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/hdfs-site.xml
修改其内容为:
dfs.replication
3
dfs.name.dir
/usr/local/hadoop/hdfs/name
dfs.data.dir
/usr/local/hadoop/hdfs/data
复制mapred-site.xml.template为mapred-site.xml
cp /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/mapred-site.xml
再修改mapred-site.xml配置文件
vi /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/mapred-site.xml
修改其内容为:
mapreduce.framework.name
yarn
mapred.job.tracker
http://onemore-hadoop-master:9001
修改yarn-site.xml配置文件
vi /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/yarn-site.xml
修改其内容为:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
onemore-hadoop-master
新建masters配置文件
vi /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/masters
新增内容为:
onemore-hadoop-master
配置slaves文件
vi /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/slaves
修改其内容为:
onemore-hadoop-slave1
onemore-hadoop-slave2
onemore-hadoop-slave3
从节点配置
下面以onemore-hadoop-slave1从节点为例进行叙述,您需参照以下步骤完成onemore-hadoop-slave2和onemore-hadoop-slave3从节点的配置。
下载Hadoop
还是从北京理工大学的镜像上下载Hadoop(如果下载速度慢,可以在主节点上发送到从节点):
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.10.0/hadoop-2.10.0.tar.gz
创建文件夹
mkdir /usr/local/hadoop
解压
tar -xzvf hadoop-2.10.0.tar.gz -C /usr/local/hadoop
配置环境变量
追加Hadoop的环境变量到/etc/profile文件中
cat >> /etc/profile <<EOF
#Hadoop
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.10.0
export PATH=$PATH:$HADOOP_HOME/bin
EOF
使环境变量生效
source /etc/profile
修改配置文件
删除slaves文件
rm -rfv /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/slaves
在主节点上把5个配置文件发送到从节点上
scp -r /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/core-site.xml onemore-hadoop-slave1:/usr/local/hadoop/hadoop-2.10.0/etc/hadoop/
scp -r /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/hdfs-site.xml onemore-hadoop-slave1:/usr/local/hadoop/hadoop-2.10.0/etc/hadoop/
scp -r /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/mapred-site.xml onemore-hadoop-slave1:/usr/local/hadoop/hadoop-2.10.0/etc/hadoop/
scp -r /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/yarn-site.xml onemore-hadoop-slave1:/usr/local/hadoop/hadoop-2.10.0/etc/hadoop/
scp -r /usr/local/hadoop/hadoop-2.10.0/etc/hadoop/masters onemore-hadoop-slave1:/usr/local/hadoop/hadoop-2.10.0/etc/hadoop/
启动Hadoop集群
格式化namenode
第一次启动服务前需要执行词操作,以后就不需要执行了。
hadoop namenode -format
启动hadoop
/usr/local/hadoop/hadoop-2.10.0/sbin/start-all.sh
访问http://onemore-hadoop-master:50070/,就可以查看Hadoop集群的相关信息了,如图:

常用命令
查看Hadoop集群的状态
hadoop dfsadmin -report
重启Hadoop
/usr/local/hadoop/hadoop-2.10.0/sbin/stop-all.sh
/usr/local/hadoop/hadoop-2.10.0/sbin/start-all.sh
启动dfs服务
/usr/local/hadoop/hadoop-2.10.0/sbin/start-dfs.sh
常见错误
Error: JAVA_HOME is not set and could not be found.
小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Java工程师,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注Java)
读者福利

更多笔记分享

因此收集整理了一份《2024年最新Java开发全套学习资料》送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。*
[外链图片转存中…(img-388b9DZw-1710411849546)]
[外链图片转存中…(img-fMQELFn6-1710411849547)]
[外链图片转存中…(img-Anjte00r-1710411849547)]
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注Java)
[外链图片转存中…(img-BppPcRgS-1710411849547)]
读者福利
[外链图片转存中…(img-pQ3pXYYr-1710411849548)]
更多笔记分享
[外链图片转存中…(img-8tL3y1Jm-1710411849548)]文章来源:https://www.toymoban.com/news/detail-843728.html
本文已被CODING开源项目:【一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码】收录文章来源地址https://www.toymoban.com/news/detail-843728.html
到了这里,关于写给大忙人看Hadoop完全分布式集群搭建的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!