「AI 的 iPhone 时刻已经到来。」黄仁勋在英伟达 GTC 2023 上的金句言犹在耳,这一年,AI 的发展也印证了其所言非虚。
多年来,伴随 AI 发展提速,加之英伟达的技术与生态护城河难以撼动,GTC 已经从最初的技术会议逐渐升级为全产业链共同关注的 AI 行业盛会,英伟达秀出的「肌肉」或许就是行业革新的重要催化剂。
今年的 2024 GTC AI 大会如约而至,在 3 月 18 日至 3 月 21 日期间,将有超 900 场会议与 20 余场技术讲座。当然,最受瞩目的仍然是「皮衣黄」的演讲。在前期公布的日程中,黄仁勋的演讲从北京时间 3 月 19 日凌晨 4:00 开始,持续到 6:00。就在刚刚,老黄在长达 2 小时的分享中,接连扔下「AI 核弹」:
-
新一代 GPU平台 Blackwell
-
首款基于 Blackwell 的芯片 GB200 Grace Blackwell
-
下一代 AI 超级计算机 DGX SuperPOD
-
AI 超级计算平台 DGX B200
-
新一代网络交换机 X800 系列
-
量子计算云服务
-
气候数字孪生云平台 Earth-2
-
生成式 AI 微服务
-
5 种全新的 Omniverse Cloud API
-
专为生成式 AI 应用设计的车载计算平台 DRIVE Thor
-
BioNeMo 基础模型
直播回放链接:
https://www.bilibili.com/video/BV1Z6421c7V6/?spm_id_from=333.337.search-card.all.click
cuLitho 投入使用
在去年的 GTC 大会上,英伟达推出了一个计算光刻库——cuLitho,称能够将计算光刻加速 40 倍以上。今天,黄仁勋介绍道,台积电与新思科技已经将 NVIDIA cuLipo 与其软件、制造流程和系统集成在一起,以加快芯片制造。在共享工作流程上测试 cuLitho 时,两家公司共同实现了 curvilinear flows 速度提高 45 倍,更加传统的 Manhattan-style flows 效率提高近 60 倍。
此外,英伟达还开发了应用生成式 AI 的算法,以进一步提升 cuLitho 平台的价值。具体而言,在基于 cuLitho 实现生产流程提效的基础上,这一生成式 AI 算法还能额外提高 2 倍的速度。
据介绍,通过应用生成式 AI,可以创建近乎完美的反向掩膜解决方案,将光的衍射纳入考虑,进而通过传统的物理方法得出最终光罩,最终将整个光学近似校正 (optical proximity correction, OPC) 流程的速度提高了 2 倍。
面向万亿参数规模生成式 AI 的 Blackwell 平台

上述对于 cuLitho 应用情况的介绍更像是一道「开胃菜」,展示计算光刻技术的发展前景,也在一定程度上英伟达 AI 芯片的代际升级提供了基础保障。
接下来,正餐开始。遵循英伟达每两年更新一次 GPU 架构的传统,老黄带来的第一个重磅产品便是全新的 bigger GPU——Blackwell 平台。他表示,Hopper 很棒,但是我们需要更强大的 GPU。
Blackwell 架构的命名是为了纪念首位入选美国国家科学院 (National Academy of Sciences)的非裔学者 David Harold Blackwell。
在性能上,Blackwell 拥有 6 项革命性技术加持:
- 世界上最强大的芯片:
Blackwell 架构 GPU 采用定制的 4NP 台积电工艺制造,内含 2080 亿个晶体管,通过 10 TB/秒 的 chip-to-chip 链路,将两个极限 GPU 芯片连接成一个统一的 GPU。 第二代 Transformer 引擎:Blackwell 将基于新的 4 位浮点人工智能推理能力支持双倍的计算和模型规模。
- 第五代 NVLink:
最新迭代的 NVIDIA NVLink 为每个 GPU 提供了突破性的 1.8TB/s 双向吞吐量,确保在多达 576 个 GPU 之间进行无缝高速通信,以实现最复杂的 LLM。
- RAS 引擎:
Blackwell 驱动的 GPU 包括一个用于可靠性、可用性和可维护性的专用引擎。此外,Blackwell 架构还增加了芯片级功能,利用基于 AI 预防性维护来运行诊断并预测可靠性问题。这最大限度地延长了系统正常运行时间,提高了大规模 AI 部署的恢复能力,使其能够连续不间断地运行数周甚至数月,并降低运营成本。
- Secure AI:
可在不影响性能的情况下保护人工智能模型和客户数据,并支持新的本地接口加密协议,这对医疗保健和金融服务等隐私敏感行业至关重要。
- 解压缩引擎:
专用解压缩引擎支持最新格式,可加速数据库查询,为数据分析和数据科学提供最高性能。
目前,AWS、谷歌、Meta、微软、OpenAI、特斯拉等企业都已经率先「预约」Blackwell 平台。
GB200 Grace Blackwell

首款基于 Blackwell 的芯片命名为 GB200 Grace Blackwell Superchip,其通过 900GB/s 的超低功耗 NVLink chip-to-chip 的互连,将两个 NVIDIA B200 Tensor Core GPU 连接到 NVIDIA Grace CPU 中。
其中,B200 GPU 的晶体管数量是现有 H100 的两倍多,拥有 2080 亿个晶体管。其还能通过单个 GPU 提供 20 petaflops 的高计算性能,而单个 H100 最多只能提供 4 petaflops 的 AI 计算能力,此外,B200 GPU 还配备了 192 GB 的HBM3e 内存,提供高达 8 TB/s 的带宽。

GB200 是英伟达 GB200 NVL72 的关键组件,NVL72 是多节点、液冷、机架式系统,适用于计算最密集的工作负载,结合了 36 个 Grace Blackwell 超级芯片,其中包括 72 个 Blackwell GPU 和 36 个 Grace CPU,通过第五代 NVLink 互连。
此外,GB200 NVL72 还包括 NVIDIA BlueField®-3 数据处理单元,可在超大规模人工智能云中实现云网络加速、可组合存储、零信任安全和 GPU 计算弹性。与相同数量的英伟达 H100 Tensor Core GPU 相比,GB200 NVL72 在 LLM 推理工作负载方面的性能最多可提升 30 倍,成本和能耗最多可降低 25 倍。
下一代 AI 超级计算机 DGX SuperPOD
英伟达 DGX SuperPOD 采用高效的新型液冷机架式架构,由 NVIDIA DGX GB200 系统构建而成,可在 FP4 精度下提供 11.5 exaflops 的 AI 超级计算能力和 240 TB 的快速内存,并且可通过额外的机架扩展到更高性能。DGX SuperPOD 具有智能预测管理功能,可以不断监测硬件和软件上的数千个数据点,以预测和拦截造成停机和效率低下的 sources,从而节省时间、能源和计算成本。
其中,DGX GB200 系统搭载了 36 个 NVIDIA GB200 超级芯片,其中包括 36 个 NVIDIA Grace CPU 和 72 个 NVIDIA Blackwell GPU,通过第五代 NVLink 连接为一台超级计算机。
而每个 DGX SuperPOD 能够搭载 8 个或更多的 DGX GB200,可扩展到通过 NVIDIA Quantum InfiniBand 连接的数万个 GB200 超级芯片。例如,用户能够将 576 个 Blackwell GPU 连接到 8 个基于 NVLink 互联的 DGX GB200 中。
AI 超级计算平台 DGX B200
DGX B200 是一个用于人工智能模型训练、微调和推理的计算平台,采用风冷式、传统机架式 DGX 设计。DGX B200 系统在全新 Blackwell 架构中实现了 FP4 精度,可提供高达 144 petaflops 的 AI 计算性能、1.4TB 的海量 GPU 内存和 64TB/s 的内存带宽。与上一代相比,万亿参数模型的实时推理速度提高了 15 倍。
基于全新 Blackwell 架构的 DGX B200 搭载了 8 个 Blackwell GPU 和 2 个第五代英特尔至强处理器。用户还可以使用 DGX B200 系统构建 DGX SuperPOD。在网络连接方面,DGX B200 配备 8 个 NVIDIA ConnectX™-7 网卡和 2 个 BlueField-3 DPU,可提供高达每秒 400 千兆比特的带宽。
新一代网络交换机系列——X800
据介绍,新一代网络交换机 X800 系列专为大规模人工智能设计,打破了计算和AI工作负载的网络性能极限。
该平台包含 NVIDIA Quantum Q3400 交换机以及 NVIDIA ConnectX@-8 超级网卡,实现了行业领先的 800Gb/s 端到端吞吐量,比上一代产品提升了 5 倍带宽容量,同时还通过采用英伟达的可扩展分层聚合与还原协议 (Scalable Hierarchical Aggregation and Reduction Protocol, SHARPv4),实现了高达 14.4 Tflops 的网络内计算能力,较上一代产品的性能增幅高达 9 倍。
量子计算云服务,加速科研探索
英伟达量子计算云服务基于公司的开源 CUDA-Q 量子计算平台,目前业内部署量子处理单元 (QPU) 的企业有四分之三都在使用该平台。英伟达推出的量子计算云服务首次允许用户在云中构建并测试新的量子算法和应用,包括强大的模拟器和量子混合编程工具。
量子计算云具有强大的功能和第三方软件集成,可加速科学探索,包括:
-
与多伦多大学合作开发的生成式量子特征求解器,利用大型语言模型使量子计算机更快地找到分子的基态能量。
-
Classiq 与 CUDA-Q 的集成使量子研究人员能够生成大型、复杂的量子程序,并深入分析和执行量子电路。
-
QC Ware Promethium 可解决复杂的量子化学问题,如分子模拟。
发布气候数字孪生云平台 Earth-2
Earth-2 旨在对天气和气候进行大规模模拟和可视化,进而实现对极端天气的预测。Earth-2 API 提供 AI 模型,并采用 CorrDiff 模型。
CorrDiff 是 NVIDIA 新推出的生成式 AI 模型,它采用 SOTA Diffusion 模型,生成的图像分辨率比现有的数值模型 (numerical models) 高 12.5 倍,速度提升 1,000 倍,能源效率提高 3,000 倍。它克服了粗分辨率预测的不准确性,并综合了对决策至关重要的指标。

CorrDiff 是一种首创的生成式人工智能模型,可提供超分辨率,合成全新的重要指标,并从高分辨率数据集中学习当地细粒度天气的物理特性。
发布生成式 AI 微服务,促进药物研发、医疗技术迭代及数字健康
新推出的英伟达医疗健康微服务 (NVIDIA healthcare microservices) 套件包括优化后的 NVIDIA NIM™ AI 模型及行业标准 API 工作流,可作为创建和部署云原生应用的构建模块。这些微服务具备高级成像、自然语言与语音识别、数字生物学的生成、预测与模拟等能力。

此外,包括 Parabricks®、MONAI、NeMo™、Riva 和 Metropolis 在内的英伟加速软件开发工具包及相关工具,现已支持通过英伟达 CUDA-X™ 微服务访问。
推理微服务 (inference microservice)
发布数十种企业级生成式 AI 微服务,企业可以在保有知识产权的同时,使用这些服务在自己的平台上创建和部署自定义应用程序。

新的 GPU 加速 NVIDIA NIM Microservices 和 Cloud Endpoints,适用于经过优化的预训练 AI 模型,可在跨云、数据中心、工作站和 PC 的数亿个支持 CUDA 的 GPU 上运行。
企业可使用微服务来加速数据处理、LLM 定制、推理、 检索增强生成和防护;
被广泛的人工智能生态系统采用,包括领先的应用平台提供商 Cadence、CrowdStrike、SAP、ServiceNow 等。
NIM 微服务提供由英伟达推理软件支持的预构建容器(包括 Triton Inference Server™ 和 TensorRT™-LLM),可以将部署速度从几周缩短到几分钟。
发布 Omniverse Cloud API,为工业数字孪生软件工具赋能
利用 5 种全新的 Omniverse Cloud API,开发者可以直接将 Omniverse 核心技术集成到数字孪生现有设计及自动化软件应用中,也可以集成到测试及验证机器人或自动驾驶汽车等仿真工作流程中,如将交互式工业数字孪生流传输到 Apple Vision Pro。
这些 API 包括:
-
USD Render:生成全局光线追踪 OpenUSD 数据的 NVIDIA RTX™ 渲染
-
USD Write:允许用户修改 OpenUSD 数据并与之交互。
-
USD Query:支持场景查询和场景交互。
-
USD Notify:追踪 USD 更改并提供更新。
-
Omniverse Channel:链接用户、工具及现实,实现跨场景协作
黄仁勋认为,未来所有制造出来的东西都会有数字孪生,Omniverse 是构建和运行物理现实数字孪生的操作系统,Omniverse 和生成式人工智能是 50 兆美元重工业市场数字化的基础技术。
DRIVE Thor:具备 Blackwell 架构的生成式 AI 能力,为自动驾驶赋能
DRIVE Thor 是专为生成式 AI 应用设计的车载计算平台,可在集中式平台上提供功能丰富的模拟驾驶以及高度自动驾驶功能。作为下一代自动驾驶汽车中央计算机,它安全可靠,将智能功能统一到一个系统中,可以提高效率,降低整个系统的成本。
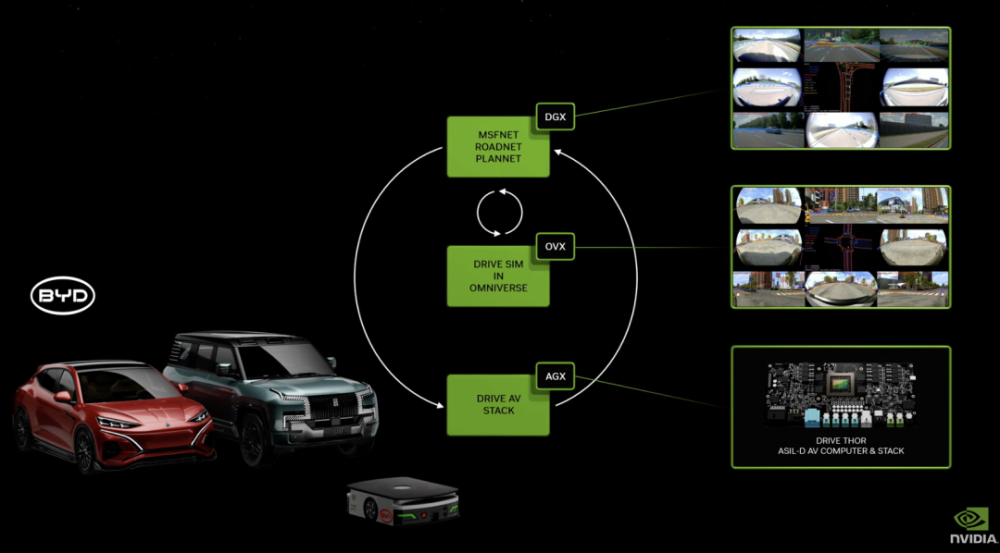
DRIVE Thor 也将集成全新的英伟达 Blackwell 架构,该架构专为Transformer、LLM和生成式人工智能工作负载而设计。
BioNeMo:辅助药物发现
BioNeMo 基础模型可以分析 DNA 序列,预测蛋白质在药物分子作用下的形状变化,并根据 RNA 确定细胞的功能。
目前,BioNeMo 所提供的第一个基因组模型 DNABERT,以 DNA 序列为基础,可用于预测基因组特定区域的功能,分析基因突变和变异的影响等。而其即将推出的第二个模型 scBERT,是根据单细胞 RNA 测序数据训练而成的,用户可将其应用于下游任务,如预测基因敲除的效果(即删除或停用特定基因),以及识别神经元、血细胞或肌肉细胞等细胞类型。
据介绍,目前全球已经有超百家企业在基于 BioNeMo 推进其研发进程,其中包括总部位于东京的 Astellas Pharma、计算软件开发商 Cadence、药物研发公司 Iambic 等等。
写在最后
除了上述提到的诸多新品外,黄仁勋还介绍了英伟达在机器人领域的布局。老黄表示,所有移动的东西都是机器人,而汽车工业将是其中的重要组成部分,目前 NVIDIA 计算机已经应用于汽车、卡车、送货机器人和机器人出租车。随后还推出了 Isaac Perceptor 软件开发工具包、人形机器人通用基础模型 GR00T、基于英伟达 Thor 片上系统的人形机器人新计算机 Jetson Thor,并对英伟达 Isaac 机器人平台进行了重大升级。
总结来看,长达 2 小时的分享中,充斥着高密集度的高性能产品、模型介绍,如此快节奏、内容丰富的发布会也恰如当下 AI 行业发展现状——高速且繁荣。
作为 AI 时代的底座,高性能芯片所代表的计算能力是决定行业发展周期与走向的关键。毫无疑问,目前的英伟达拥有难以撼动的护城河,尽管已经有多家企业开始朝着老黄发起冲击,加之 OpenAI、微软、谷歌等也在培养自家的「军队」,但这对仍处于高速向前的英伟达而言,或许也是一股更大的推力。文章来源:https://www.toymoban.com/news/detail-843730.html
现在,线上直播已经结束,黄仁勋的每一次新品发布后都会介绍哪些合作伙伴已经「预约」了新服务,大厂巨头们无一例外的榜上有名。未来,我们也期待着目前冲在行业最前排的企业能够利用行业先进生产力,带来更具革新性的产品与应用。文章来源地址https://www.toymoban.com/news/detail-843730.html
到了这里,关于英伟达黄仁勋发布GB200,比H100推理能力提高30倍,能耗降低25倍,将AI4S能力做成微服务的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!