提供五种常见的数据类型:String(字符串),Hash(哈希),List(列表),Set(集合)、Zset(有序集合)
1、为什么用Redis作为MySQL的缓存
Redis具有高性能和高并发两种特性
2、Redis为什么快
1、Redis 的大部分操作都在内存中完成,并且采用了高效的数据结构
2、采用单线程模型可以避免了多线程之间的竞争,省去了多线程切换带来的时间和性能上的开销,而且也不会导致死锁问题
3、Redis 采用了 I/O 多路复用机制处理大量的客户端 Socket 请求,IO 多路复用机制是指一个线程处理多个 IO 流,就是我们经常听到的 select/epoll 机制
3、Redis主从复制
将从前的一台 Redis 服务器,同步数据到多台从 Redis 服务器上,即一主多从的模式,且主从服务器之间采用的是「读写分离」的方式。
主服务器可以进行读写操作,当发生写操作时自动将写操作同步给从服务器,而从服务器一般是只读,并接受主服务器同步过来写操作命令,然后执行这条命令。
主从服务器之间的命令复制是异步进行的
4、Redis持久化
Redis 的读写操作都是在内存中,所以 Redis 性能才会高,但是当 Redis 重启后,内存中的数据就会丢失,那为了保证内存中的数据不会丢失,Redis 实现了数据持久化的机制,这个机制会把数据存储到磁盘,这样在 Redis 重启就能够从磁盘中恢复原有的数据。
AOF 日志:每执行一条写操作命令,就把该命令以追加的方式写入到一个文件里
RDB 快照:将某一时刻的内存数据,以二进制的方式写入磁盘
混合持久化方式:Redis 4.0 新增的方式,集成了 AOF 和 RBD 的优点
AOF日志/RDB快照是如何实现配合完成持久化
1、AOF持久化
AOF 持久化通过记录 Redis 服务器收到的写命令来记录数据变更。
每个写命令都会以文本方式追加到 AOF 文件末尾,保证了数据的持久化。
当 Redis 重启时,会通过重新执行 AOF 文件中的命令来还原数据状态。
2、RDB持久化
RDB 持久化通过生成一个二进制的 RDB 快照文件来保存 Redis 在某个时间点的数据快照。
RDB 快照是 Redis 数据在某个时刻的完整备份,通常用于全量恢复数据。
可以通过配置定时保存或手动触发生成 RDB 快照文件。
5、Redis和MySQL不一致如何解决
1、定期同步数据:定期将 MySQL 中的数据同步到 Redis 中,确保数据的一致性。可以通过编写脚本或使用定时任务来实现数据同步的操作。
2、使用消息队列:将 MySQL 的数据变更通过消息队列发送到 Redis,然后在 Redis 中进行相应的更新操作,确保数据的同步性。这种方式可以减少直接对数据库的读写操作,提高系统的性能。
3、采用双写模式:对于写操作,先更新 MySQL,然后再更新 Redis,确保两者数据的一致性。这种方式虽然会增加写操作的时间,但可以保证数据的准确性。
4、实现数据同步机制:可以通过监听 MySQL 数据库的 binlog 或者使用类似 Canal 这样的工具来捕获数据变更,然后同步到 Redis 中,保持数据的一致性。
5、处理数据冲突:如果出现数据不一致的情况,可以编写相应的逻辑来处理数据冲突,例如选择某个数据源作为主数据源,或者进行数据合并等操作。
6、Redis缓存【雪崩】【击穿】【穿透】
1、缓存雪崩:大量数据同时过期、redis故障
2、缓存击穿:热点数据缓存过期
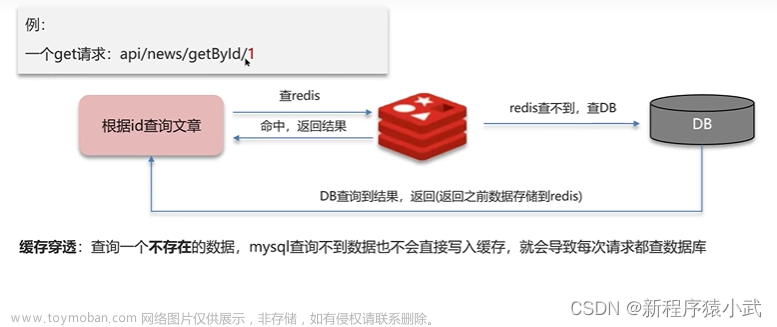
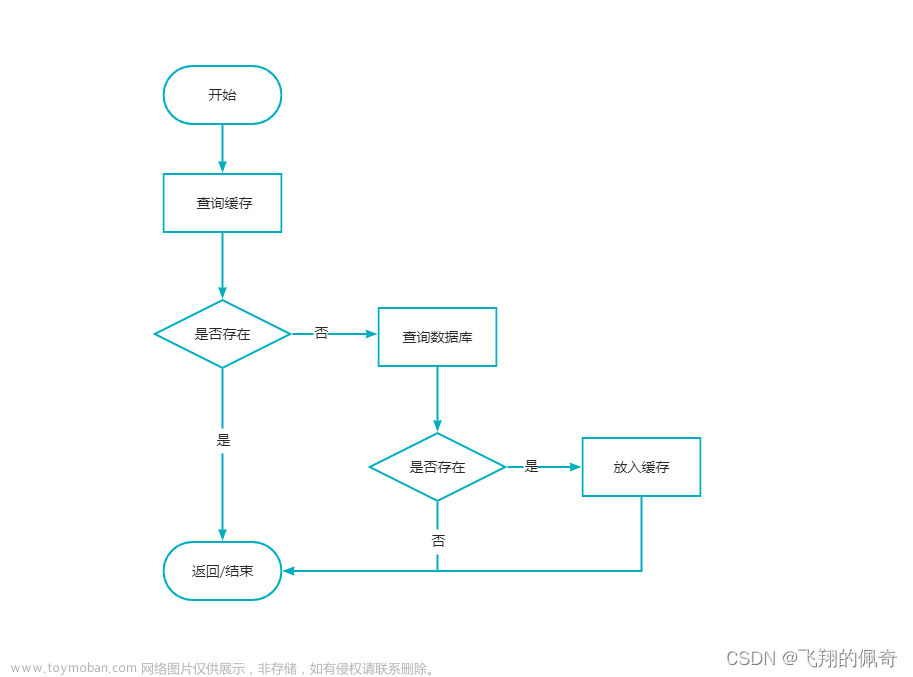
3、缓存穿透:数据既不在缓存,也不知数据库
7、Redis过期删除策略和内存淘汰策略
1、过期删除策略:对 key 设置过期时间
# 设置过期时间
set key1 20 ex 100 # 秒
setex key1 100 20 # 秒
set key1 20 px 100 # 毫秒
# 查看过期时间还剩多少
ttl key1
# 取消过期时间
persist key1
# 使用完 persist 命令之后,查下 key1 的存活时间结果是 -1,表明 key1 永不过期
> ttl key1
(integer) -1
2、内存淘汰策略:当 Redis 的运行内存已经超过 Redis 设置的最大内存之后,则会使用内存淘汰策略删除符合条件的 key,以此来保障 Redis 高效的运行
使用 config get maxmemory-policy 命令,来查看当前 Redis 的内存淘汰策略
通过“config set maxmemory-policy <策略>”命令设置。它的优点是设置之后立即生效,不需要重启 Redis 服务,缺点是重启 Redis 之后,设置就会失效。
通过修改 Redis 配置文件修改,设置“maxmemory-policy <策略>”,它的优点是重启 Redis 服务后配置不会丢失,缺点是必须重启 Redis 服务,设置才能生效。
8、Redis大Key问题
存储在 Redis 中占用大量内存空间的 Key
内存占用过高、影响性能、内存碎片问题
【解决】
1、分布式存储:将大 Key 拆分为多个小 Key,并分布存储在不同的 Redis 实例或节点中,避免单个 Key 过大造成问题。
2、数据分页:对于大数据量的 Key,可以采用分页查询的方式,按需加载数据,而不是一次性获取所有数据。
3、合理设计数据结构:根据业务需求合理设计数据结构,避免存储过大的数据对象,尽量将数据拆分为多个小 Key 存储。
4、定时清理:定期清理不再需要的大 Key,释放内存空间,避免内存占用过高。
5、监控和优化:通过监控 Redis 实例的内存占用情况,及时发现并优化存在大 Key 的情况,保持 Redis 实例的健康运行。
9、布隆过滤器是?底层原理是?
布隆过滤器(Bloom Filter)是一种空间效率高、适合大规模数据集的概率型数据结构,用于快速判断一个元素是否存在于一个集合中。它可以有效地减少对存储系统的查询压力,特别适用于需要快速判断某个元素是否可能存在于一个大型集合中的场景。
布隆过滤器的底层原理主要基于以下两个关键组件:
- 位数组(Bit Array):布隆过滤器使用一个足够长的二进制位数组来存储数据。数组的每一位都初始化为0,当向过滤器中添加元素时,会通过一系列哈希函数计算出元素在数组中的位置,并将这些位置对应的位设置为1。
- 哈希函数(Hash Functions):布隆过滤器使用多个哈希函数来计算元素在位数组中的位置。每个哈希函数都会将元素映射到位数组中的一个特定位置。当元素被添加到过滤器中时,所有哈希函数都会计算出对应的位置,并将这些位置的位设置为1。同样地,当查询一个元素时,也会使用相同的哈希函数来计算元素在位数组中的位置,并检查这些位置的位是否都为1。如果所有位置的位都为1,则认为元素可能存在于集合中;否则,认为元素一定不存在于集合中。
10、Redis实现分布式锁
Redis通过使用SETNX(SET if Not eXists)指令来实现分布式锁,客户端尝试在Redis中设置指定的键值对,如果该键不存在则设置成功并获得锁,否则设置失败表示锁已被其他客户端获取,这种方式能够确保在分布式环境下实现原子性的加锁操作。文章来源:https://www.toymoban.com/news/detail-843751.html
具体略文章来源地址https://www.toymoban.com/news/detail-843751.html
到了这里,关于【Redis】高频面试题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!