数据库三大范式的学习与数据库表设计的了解
内容简单介绍
对于数据库三大范式的理解以及一些设计表示要注意的方面
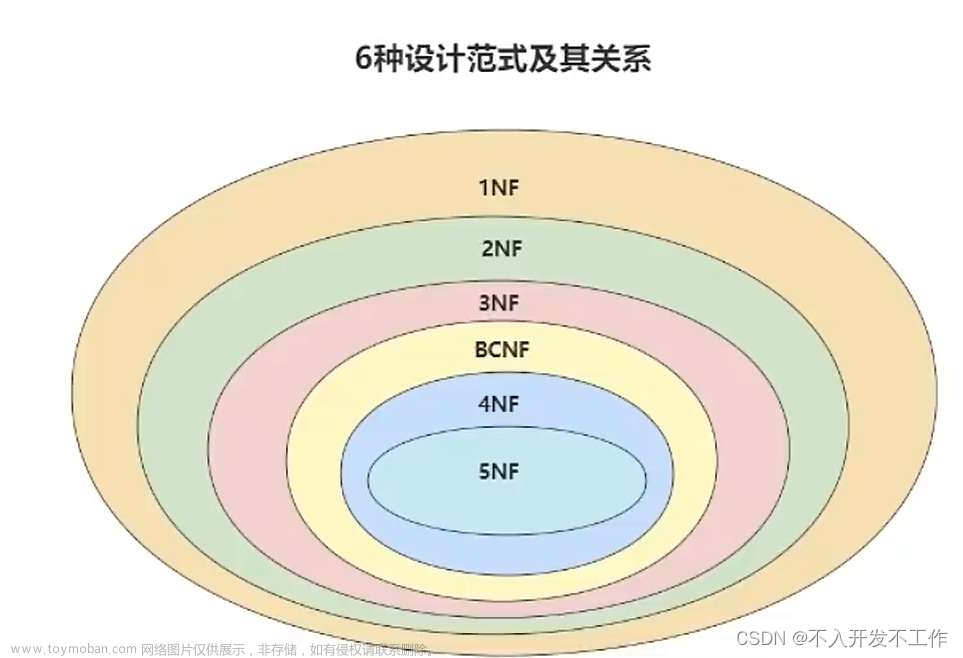
本章内容梳理图
数据库三大范式比较官方的定义
数据库的三大范式(Normal Forms)是关系数据库设计中用于确保数据结构化、减少数据冗余、并提高数据完整性的指导和规则。
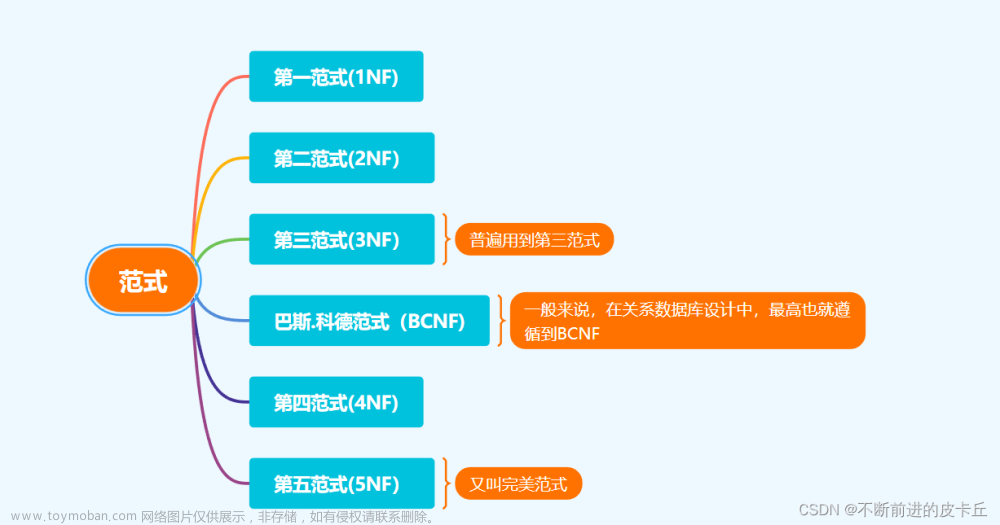
以下是三大范式的简述:
-
第一范式(1NF)
- 定义:如果关系模式R的每个属性都是不可分的数据项,则R∈1NF。简单来说,就是表中的每个字段都是最基本的单元,不可再分。
- 目的:消除字段中的重复组和确保每个字段的原子性。
- 注意:在现代的关系型数据库管理系统中,通常都默认满足第一范式。
-
第二范式(2NF)
- 前提:满足第一范式。
- 定义:如果关系模式R∈1NF,且每一个非主属性都完全函数依赖于任何一个候选键,则R∈2NF。
- 目的:消除部分函数依赖,即非主属性不应仅依赖于主键的一部分(在复合主键的情况下)。
- 做法:通常通过拆分表来实现,确保非主属性完全依赖于整个主键。
-
第三范式(3NF)
- 前提:满足第二范式。
- 定义:如果关系模式R中不存在非主属性对主属性的传递依赖,则称R在第三范式。
- 目的:消除传递依赖,确保非主属性不依赖于其他非主属性。
- 注意:有时为了查询效率,可能会故意违反第三范式,但这需要权衡冗余和查询效率之间的关系。
数据库三大范式个人简要理解版
第一范式:每个属性都是不可分割的,原子性的,例如地址这个字段,它还可以分为省、市、区或县
第二范式:在满足一范式的情况下,所有非主键属性必完全依赖于主键,这里完全是指非主键属性依赖于主键的所有部分(会有复合主键),而非主键属性之间存在依赖则不是第二范式关心的重点,这是第三范式的重点内容,第二范式的重点是非主键属性与主键有无直接完全依赖关系。要是非主键属性依赖于主键的一部分或者非主键属性与主键无直接完全依赖,那么需要拆分成多个表进行满足第二范式
第三范式:在满足二范式的情况下,非主键不能有传递依赖,传递依赖是指a依赖于b,而b又依赖于主键,这就是a间接依赖于主键,比如某一属性依赖于另一属性,然后另一属性依赖于主键,这就是传递依赖,出现这种情况的话,需要根据实际进行拆分成多个表来完成满足第三范式
数据库三大范式个人详细理解版
数据库第一范式的理解
这里要理解这个不可分割的原子项,这个主要指一个字段所表达的内容是单一的,不可在分割,例如省份,就是指山西省、河北省等,这种从内容上不能够分割的,要是地址的话就可以分为国家、省份、市、区县、乡村,这样就达到不可分割的原子项了,再来说一下另一种情况,先来举个例子吧
学生ID、学生姓名、课程1、课程2、课程3,这是一个表,看是否满足第一范式,答案是满足的,每一列都是不可分割的原子项,但是我们设计表得遵循数据库表设计规范,而三大范式只是一部分,按照表设计规范的话,上方的表示不满足的,有以下几个点考虑:
- 可扩展性问题:每个学生只能记录三门课程,如果需要记录更多或更少的课程,表结构就需要调整。
- 数据冗余:如果多个学生选修了同一门课程,那么该课程的名称将在表中多次出现,违反了避免数据冗余的原则。
- 更新和维护困难:如果课程名称需要更改,那么所有相关的课程字段(课程1、课程2、课程3)都需要更新,这增加了维护的复杂性。
- 查询困难:查询特定学生选修的所有课程或查询选修了特定课程的所有学生都变得更加困难,因为课程信息分散在不同的字段中。
所以在考虑上方四个问题的话,我们将上方的表设计为
- 学生表:包含学生ID和学生姓名。
- 课程表:包含课程ID和课程名称。
- 学生课程关联表:包含学生ID、课程ID和可能的其他相关信息(如成绩)
此做法消除了数据冗余,提高了可扩展性,并简化了更新和查询操作,而且还要注意的是那个个学生课程关联表这种做法非常常见,尽量去学习一下
这就是数据库第一范式学习与理解
数据库第二范式的理解
这里要理解所谓的依赖,像我自己想的就是:我们在数据库中使用sql语句查询不就是非主键依赖于主键吗,这其实是不正确的,虽然有一定的关系,但我们要分清主次,就是第二范式这个依赖,主要是基于业务逻辑的关系,比如学生学号与学生姓名等其他学生信息这种含有关联的业务逻辑,我们要看非主键与主键是否符合这种业务逻辑关系,而且还得必须是完全符合,接着拿一个例子来说明一下这个判断过程
一个订单表:订单ID、产品ID、产品名称、产品价格、订单数量、客户ID和客户姓名,看一下这个表是否满足第二范式
我们假设这个订单表主键为订单ID,订单在业务上与产品有关联的,这个订单是买的啥产品了,并不是那种直接的业务逻辑关系,产品名称只是依赖于产品ID,所以不是依赖于订单ID,虽然按这样设计表,通过查询订单ID可以得出产品名称来,这是在查询中的一种关系吧,而这里的时候要满足业务逻辑这个依赖的,所以不满足第二范式的,那么改进为
将订单表拆分为三个表:订单表、产品表和客户表。订单表包含订单ID、产品ID、订单数量和客户ID字段;产品表包含产品ID、产品名称和产品价格字段;客户表包含客户ID和客户姓名字段
对了除了满足这种依赖的话,第二范式是非主键完全依赖主键,注意这里的完全,是指非主键要依赖于主键的所有,有可能主键的话就是复合主键,要是我们把上方例题的表的主键假设为(订单ID、产品ID),产品名称仅依赖于产品ID,只是一部分,所以不满足第二范式,改进结果与上方一致
还有比较重要的点就是:第二范式是基于第一范式的基础上来进行判断与改进的,另一个关注点就是第二范式主要看非主键与主键的关系,不用关注非主键之间的关系
这就是第二范式的学习与理解
数据库第三范式的理解
这里主要理解的就是一个非主键有依赖于另一个非主键,然后另一个非主键直接依赖于主键这种情况,这样就构成了一个非主键对主键的传递依赖,要满足第三范式就得消除这种依赖,请看下方的例子实操
一个员工表:员工ID、员工姓名、部门ID、部门名称和部门经理,看一下是否满足第三范式
一般员工表的主键为员工ID,所以我们假设主键为员工ID,我们看一下有没有传递依赖的情况,部门名称和部门经理就可以依赖于部门ID,然后再依赖于员工ID,就形成了传递依赖,那我们需要拆分表
将员工表拆分为两个表:员工表和部门表。员工表包含员工ID、员工姓名和部门ID字段;部门表包含部门ID、部门名称和部门经理字段。确保每个表中的非主键列都只直接依赖于主键列
这其实分析挺矛盾的,第三范式是基于第二范式的情况下判断,员工表第二范式并未满足,你用第二范式来做这个题其实直接就可以得出最终结果了,而且也满足第三范式的,但是题又让你分析,确实是存在依赖关系的,所以你要根据第三范式的主要点是否有传递依赖来分析,这也第三范式的重点
这就是第三范式的学习与理解文章来源:https://www.toymoban.com/news/detail-843760.html
总结
三大范式是设计表的基础,要是满足这三大范式的话,表的查询性能等其他方面也会下降,所以本章只是介绍三大范式的用法,实际设计表还得考虑很多因素,这里列出一些:文章来源地址https://www.toymoban.com/news/detail-843760.html
- 业务需求理解:
- 在设计数据库表之前,必须充分理解业务需求。这包括了解需要存储哪些数据、数据之间的关系、数据的访问模式等。
- 数据完整性:
- 确保数据的准确性和一致性。这包括使用主键、外键、唯一约束、检查约束等来维护数据的完整性。
- 性能优化:
- 考虑查询性能、数据插入、更新和删除的性能。可能需要创建索引、视图、存储过程等来提高性能。
- 安全性:
- 确保只有授权的用户可以访问和修改数据。这包括使用适当的身份验证和授权机制。
- 可扩展性:
- 设计数据库表时,应考虑未来的增长和变化。这可能包括使用分区表、归档旧数据等策略。
- 规范化与反规范化:
- 根据需要平衡规范化和反规范化的程度。规范化有助于减少数据冗余和提高数据一致性,但可能导致查询性能下降。反规范化则可以提高查询性能,但可能增加数据冗余和维护复杂性。
- 数据类型选择:
- 为每个字段选择合适的数据类型,以确保数据的准确性和存储效率。
- 命名规范:
- 使用清晰、有意义的命名规范来命名表、字段、索引等数据库对象,以提高可读性和可维护性。
- 文档化:
- 为数据库表设计提供充分的文档,包括表结构、字段说明、关系说明、索引说明等,以便于其他开发人员理解和维护。
- 备份与恢复策略:
- 设计数据库时应考虑备份和恢复策略,以确保在发生故障时可以恢复数据。
- 并发控制:
- 在多用户环境中,需要考虑并发控制机制,如乐观锁、悲观锁等,以防止数据冲突和不一致。
- 遵循最佳实践和标准:
- 遵循数据库设计的最佳实践和行业标准,如使用三大范式、避免使用保留字等。
到了这里,关于数据库三大范式的学习与数据库表设计的了解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[MySQL]数据库原理1,三大范式,E-R图,DataBase,数据库管理系统(DBMS),Relationship,实体、属性、联系 映射基数,关系型数据库,联系的度数等——喵喵期末不挂科](https://imgs.yssmx.com/Uploads/2024/02/766862-1.png)