🉑 近期大模型更新消息一览:Sora 影响涟漪犹在,Mistral 不愧欧洲 LLM 之光
🧩 法国大模型初创公司 Mistral AI 发布 Large 和 Small 两款大模型**
mistral.ai/news/mistra…
体验网址 chat.mistral.ai/chat
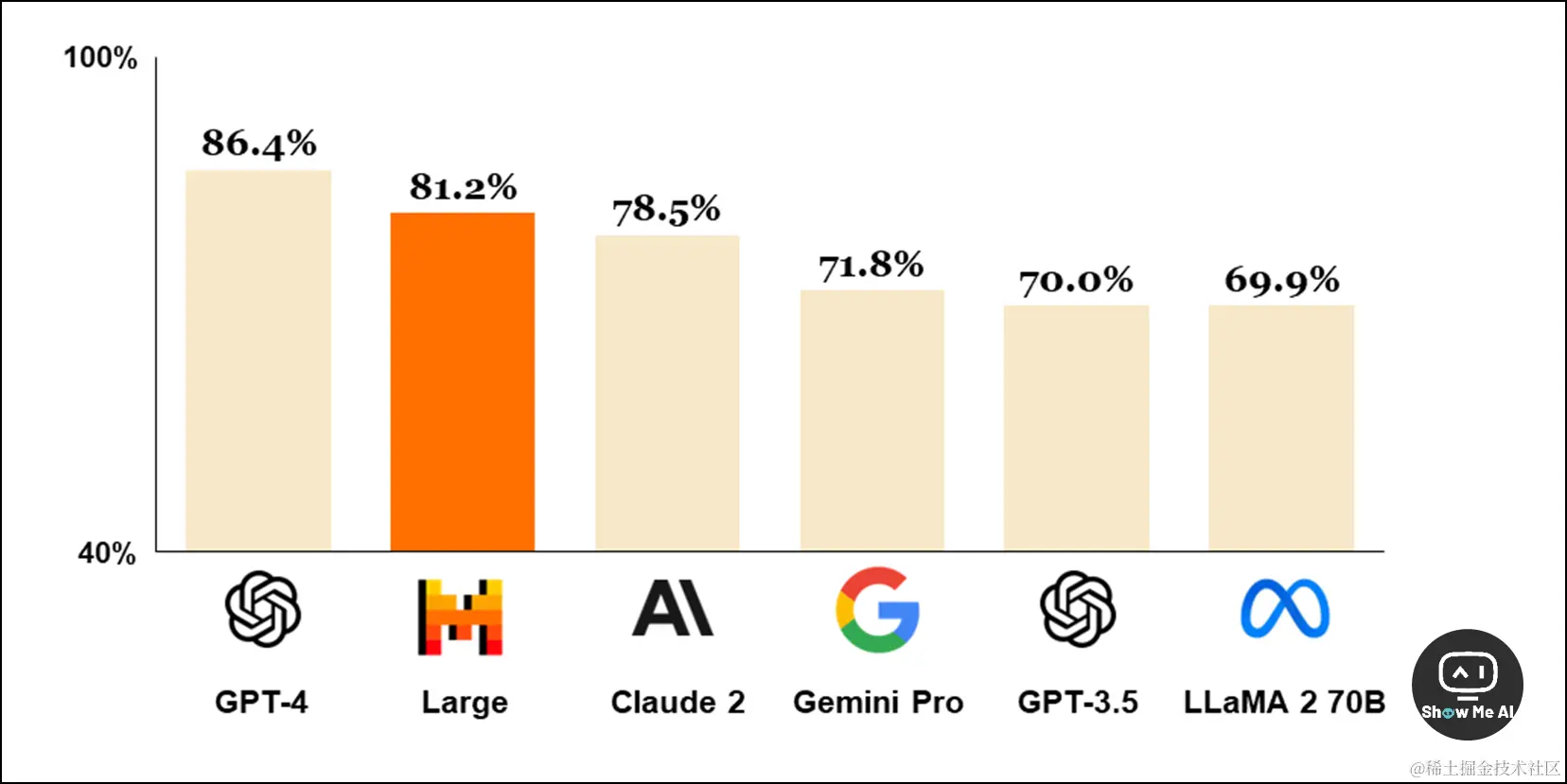
继推出 Mixtral 8x7B、Mistral Medium 后,Mistral AI 这次发布了性能比肩 GPT-4 的旗舰大模型Mistral Large,以及针对低延迟和成本优化的新模型 Mistral Small。
根据 Mistral AI 官网的消息,Mistral Large 在行业内公认的基准测试中表现出色,仅次于 GPT-4,成为通过 API 提供的全球第二顶尖模型。
Mistral Large 调用方式
- Plateforme:Mistral AI 在欧洲基础设施上安全托管的接入点,使开发者能够利用广泛模型范围创建应用和服务
- Azure:在 Azure AI Studio 和 Azure 机器学习上,提供与 API 同样流畅的用户体验 (表示已经与 Microsoft 开展合作)
- 自我部署:模型可部署于客户自己的环境中,适用于最敏感用例,并提供模型权重访问
🧩 Pika Labs 正式上线唇形同步功能,生成视频里的人物能说话了
twitter.com/pika_labs/s… | 观看视频
目前对 Pro 用户开放,体验地址:pika.art/home | 一线测评
2月27日,Pika 官推正式宣布上线 Lip Sync (唇形同步) 功能,也就是 Pika 生成的视频中,人物说话时口型和声音能对上,直接一步到位。这样,生成者就可以决定视频中的人物说什么话、具体用什么风格说话了!
🧩 阿里巴巴视频生成框架 EMO,音频+图像即可生成视频,面部表情和口型都能对的上
humanaigc.github.io/emote-portr… | 观看视频
阿里巴巴提出了一个音频驱动肖像视频生成框架EMO,只需要输入一张参考图像和语音音频 (例如说话和唱歌),就可以生成具有面部表情、各种头部姿势的视频,而且还可以根据输入视频的长度生成任意时长的视频。
有了这个模型,那让图片唱歌或说话就完全不成问题啦!👆 链接给出的例子显示,不同语言、不同风格、快慢节奏等等,EMO 都可以处理得很好!
一个小插曲是,EMO 今天被AI社区里的伙伴们骂惨了,主要原因是演示效果如此炸裂但 GitHub 项目却是空的… 有点「空口无凭」的期待落差感 🙄
但是这个空GitHub 已经1K Star 了而且还在快速增长中!不来凑个热闹嘛 github.com/HumanAIGC/E…
🧩 Google DeepMind 发布 Genie:110 亿个参数,基于图片和提示词生成 2D 游戏

sites.google.com/view/genie-…
论文地址 arxiv.org/pdf/2402.15…
Sora 平地炸响一声雷后,Google 快速跟上了节奏,发布了可动作控制的世界模型 Genie,可以根据图像和提示生成可操作的二维世界。简单说就是,Genie 既可以将任何图像转换成可玩的二维世界,也可以让人类设计的草图等创作栩栩如生。
而关于 Sora 和 Genie 的区别,大概可以这样理解 (来自知乎答主 @平凡):
- Sora做的是:你给他一个prompt,比如生成一段在森林里顶蘑菇的视频,然后它就会在一段时间内给你提供一个顶蘑菇的视频。
- Genie做的是:你给他一张顶蘑菇的截图,给你一个游戏手柄,然后图片会动起来,动的逻辑会跟你手柄的操作逻辑是一致的。
- 这俩有本质上的不同,Sora是端到端的,你提供prompt,它提供视频,中间没有交互;Genie提供了交互的机会,理论上你不停,储存足够,电力不停,那视频就会一直持续。
- 这也是Genie名字的来源Generative Interactive Environment(生成式可交互环境)。
👀 在巴黎赛纳河左岸与梵高聊聊天:Hello Vincent!

www.musee-orsay.fr/en/articles…
补充一份背景知识:奥赛博物馆(Musée d’Orsay)位于法国巴黎赛纳河左岸,拥有世界上最丰富的印象派和后印象派艺术收藏品,馆藏精品包括加雷特磨坊舞会、梵高的自画像以及莫奈的蓝色睡莲等等
前段时间,法国奥赛博物馆举办了「Van Gogh in Auvers-sur-Oise (梵高在奥弗尔-苏瓦)」主题展,主办方在出口处设置了一个「Hello Vincent」智能应用程序,可以让参观者通过麦克风与梵高进行对话互动。

正如视频所示,梵高坐在他的「Wheatfield with Crows (麦田上的鸦群)」画作前,一边说话一边运动着手臂和肩膀,回答提出的问题。
想象一下!刚看完主题展就可以与画家「本人」进行交流!这沉浸感!这冲击力! 观看视频
进一步搜索了这款应用的研发公司 Jumbo Mana,他们在推上公布「Hello Vincent」基于梵高约 900 信件训练而成,并通过多幅梵高自画像生成了逼真的 3D 人物形象。
感觉这类应用场景很靠谱啊!把 Charater.ai 里受欢迎的对话模式迁移到了线下,而且就设定在博物馆展览刚刚结束、参观者意犹未尽的时候。是一次既有趣又有教育意义的尝试哇~

👀 Image to Music:使用AI把图片生成音乐 (可免费体验)

imagetomusic.top | 查看图片并收听音乐片段
Image to Music 是一个免费的AI工具,可以根据上传的图片生成符合调性的音乐片段 (10s左右)。
官网支持免费体验哦!甚至不用登录 (需要魔法)!上传图片,从 MAGNet、AudioLDM-2、Riffusion、Mustango、MusicGen 几个模型中选择一个,然后等待 1-2 分钟就可以听音乐啦!!
看网站弹框显示的进程消息,应该是先用 image caption 理解图像,然后生成与音乐相关的提示词,最后生成音乐片段。
用上方图片这个「electronic music」主题的图片试了一下,还是挺准确的!提示词准确捕捉到了风格,音乐片段也是动感十足 🎶 | 查看图片并收听音乐片段


🉑 零一万物黄文灏:没有做出 Sora 的几点反思 & Sora之后视频生成怎么做

zhuanlan.zhihu.com/p/683185877
补充一份背景:黄文灏是零一万物的技术副总裁及Pretrain负责人,曾先后任职于微软亚洲研究院和智源研究院;他的知乎账号很活跃,推荐 Follow~
红博士在 去魅Sora: OpenAI 鲜肉小组的小试牛刀 这篇文章中,根据技术报告和公开信息猜测了 Sora 的算法框架,并且以业内视角分析了背后核心人员的发展路径。文章把专业和通俗两个方面兼顾的非常好,推荐阅读!
🔔 跟上 Sora 进度没多难
黄文灏在文章中也表达了和红博士相同的观点:仔细看 Sora 的技术报告会发现,其实没太多东西,跟上 Sora 的进度也没有多难
- Sora = Magvit + DiT + NaViT + Video Caption,技术上没有太多的创新,但工程上做了大量的工作
- 要给年轻人充足的算力,这个是现在大模型公司最难决策的事,找到那些年轻人,解决组织问题
- Sora 不是世界模型,不一定用了UE数据
🔔 没有做出Sora的几点反思
零一万物从去年10月开始做视频生成,在技术路线选择上与 Sora 基本一致,但结果和Sora有一些差距。那为什么又是 OpenAI先做出了 Sora 呢?
- 技术发展的速度比想象中快很多。在视频生成技术领域,原预计技术爆发需要一年时间,但实际发展速度远超预期,仅三个月就出现了Sora。这表明在技术预判时,应该更加激进地缩短预期时间,以保持竞争力
- 需要把目标定高两个台阶。由于对技术成熟速度的低估,导致目标设定没有足够前瞻性。在技术快速发展的背景下,应将目标设定得更高,直接以超越当前领先者为目标,而不是逐步追赶
- 做更多「因为相信所以看到」的事。在技术发展中,应更多地基于信念采取行动,而不是仅仅基于已经看到的结果。
🔔 Sora之后视频生成怎么做
- 路径一:用最快的速度去复现Sora。当有人给出了一个方法可以做到很高的水平的时候,即使中间缺乏很多细节,follow一条有大体框架的路,把里面的细节一点点补上
- 路径二:有更好的视频生成方案吗?如果没有,就直接scale up,跳过复现Sora的阶段。如果有,那这个方案是什么呢?

🉑 ELAD GIL 关于大语言模型 (LLM) 的一千零一个问题:带你纵览AI全局
blog.eladgil.com/p/things-i-…
文章作者是一位大佬:Elad Gil 是一位非常出色的企业家和投资者,曾任职谷歌并创建了移动团队,创办的 Mixer Labs 被 Twitter 收购后担任 Twitter 副总裁;他也是众多知名科技公司的投资人和顾问,例如 Airbnb、Figma、Gitlab、Notion、Pinterest、Stripe,以及最近大火的Character、Mistral,Perplexity,Pika 等等。
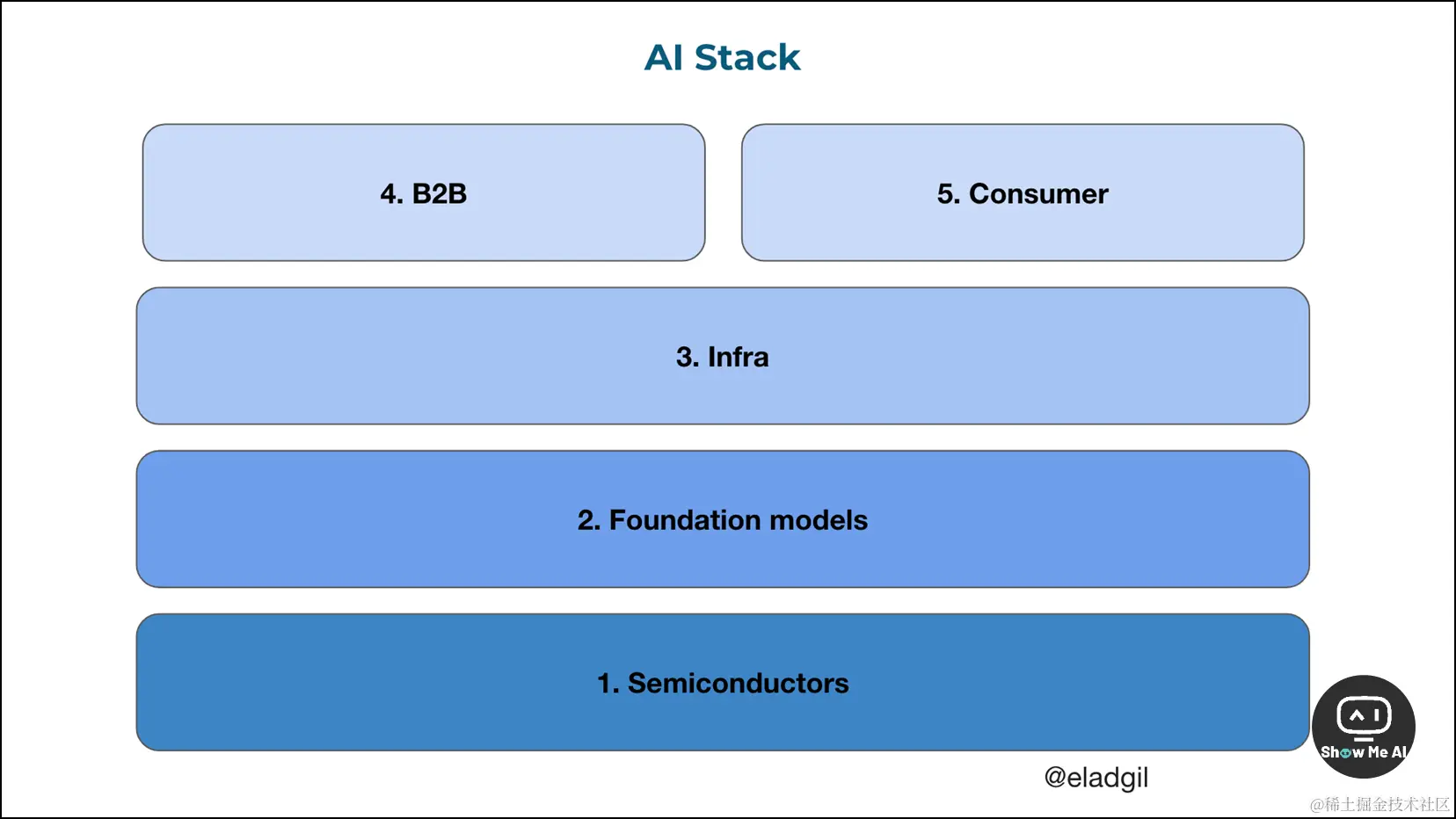
Elad Gil 这篇「Things I Don’t Know About AI」文章,把 AI 拆成了「Semiconductors (半导体)」「Foundation models (基础模型)」「Infra (基础设施)」「B2B」「Consumer (消费者)」5个板块,并对各部分提出了自己的判断&困惑,并进行了基本解释。
来!让我们跟随 Elad Gil,一起进行一场沉浸式思考!
Elad Gil 的几个基础判断 (也就是首先要达成的共识)
- 大语言模型只分类两类:最先进的前沿大模型(们) & 其他大模型,并且前沿 LLMs 会形成一个寡头市场 (因为大模型实在太太太烧钱了)
- 前沿 LLMs 的规模不断增加,训练成本也随之增高,而这些资金的主要来源是云服务商和大型科技公司 (如 Microsoft、Amazon 、Google),或者体现国家意志 (如阿联酋 Falcon);英伟达 NVIDIA 对基础模型公司的投资规模并不高
- 虽然云服务商是资金来源的大头,但这与其盈利规模相比也不算什么 (例如,Microsoft 投资 OpenAI 100 亿美元,只需要6个星期就能挣回来)
🔔 Questions on LLMs
- Question:云服务提供商是否在通过其提供的计算或资本规模,制造少数玩家的王者地位,并通过这种方式锁定寡头市场?云服务提供商是 LLM > 基础模型的主要资助者,其资金支持可能会对市场动态产生扭曲效应,例如新进入者会因资本和人才不足而出局,或者云平台借助大模型实现更高的收入
- Question:开源模型是否会推动AI经济从基础模型转向云服务?Meta是否会继续资助开源模型?如果是,Llama-N 能否追赶到最前沿?
- Question:我们如何看待模型的速度、价格与性能之间的关系?模型的价值取决于多种因素,高性能但速度较慢的模型、小型但快速且成本低廉的模型,也各自有其市场定位。
- Question:基础模型的架构将如何演变?具有不同架构的 Agentic Model 是否有发展潜力?其他形式的记忆和推理何时能发挥作用?
- Question:政府是否支持 (或指导其购买) 地区AI获胜者?政府是否会像航空航天领域的波音/空客那样,对本地模型进行差异化支出?政府是否愿意支持反映本地价值观、语言等的模型?
- Question:中国会发生什么?中国大模型可能会得到本地科技巨头 (如腾讯、阿里巴巴、小米、字节跳动) 的支持,政府也会继续通过监管和防火墙来支持本地AI公司的发展;中国开源大模型的发展也值得注意 (如 阿里巴巴 Qwen 排名很高)
- Question:X.ai (马斯克的AI公司) 会发生什么?发展情况尚不明确,很可能成为一个不确定因素
- Question:Google 前途如何?Google拥有强大的计算能力、规模和人才,能够快速推进AI技术的发展,在AI领域的潜力巨大
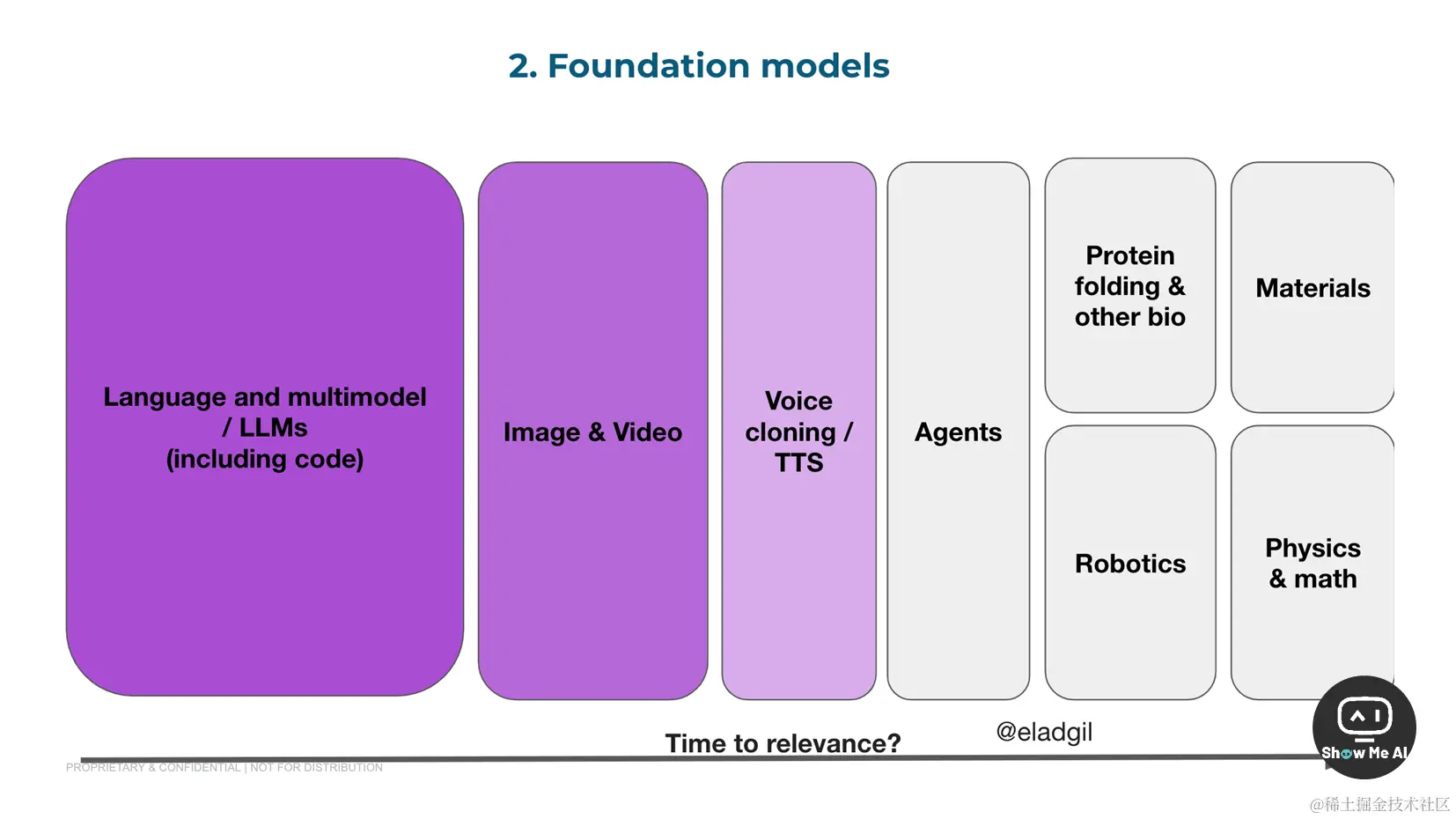
🔔 Questions on Infra Companies
AI Infra 最大的不确定性来自 AI Cloud Stack 及其发展路径,因为初创公司与大型企业对AI云服务的需求差别巨大:初创公司更愿意采用新的云服务商和工具 (如Anyscale、Baseten、Modal、Replicate、Together等),而大型企业的定制化需求也带来了更多开放性问题
- Question:当前的AI云公司是否需要为大型企业构建他们产品的本地部署 / BYOC / VPN版本?
- Question:采用AI云有多少是出于GPU限制 / GPU套利?云服务商普遍缺乏GPU,因此企业正在争相寻找足够的 GPU 来满足自己的需求,当然这对于拥有 GPU云的初创云服务商是好消息
- Question:GPU瓶颈何时才能结束?这对新的AI云提供商有何影响?当 GPU 不再是限制,那么拥有更多工具和服务的云服务商更容易存活下来
- Question:新的AI ASIC (如 Groq) 将如何影响AI云?
- Question:还有什么会被整合到AI云中?它们是否会交叉销售 embedding 和RAG?持续更新?微调?其他服务?这对数据标注公司或其他有重叠服务的公司有何影响?哪些服务会直接整合到模型提供商,哪些会通过云服务进行整合?
- Question:AI云公司有哪些商业模式?面向初创公司,更适合「GPU only」的商业模式,因为他们需要的云资源很少;面向大中型企业,更适合提供开发者工具、API端点、专业硬件等
- Question:新的AI云会有多大规模?会成为 Heroku、Digital Ocean、Snowflake、AWS 这样的庞然大物嘛?这类公司的产出规模和利用规模是多少?
- Question:随着超长上下文窗口模型的出现,AI堆栈将如何演变?如何看待上下文窗口与提示工程、微调、RAG和推理成本之间的相互作用?
- Question:FTC (和其他监管机构) 阻止并购对市场有何影响?在一个积极反对科技并购的政府下,人们如何看待退出?AI云本身是否应该在彼此之间整合以整合份额和服务提供?
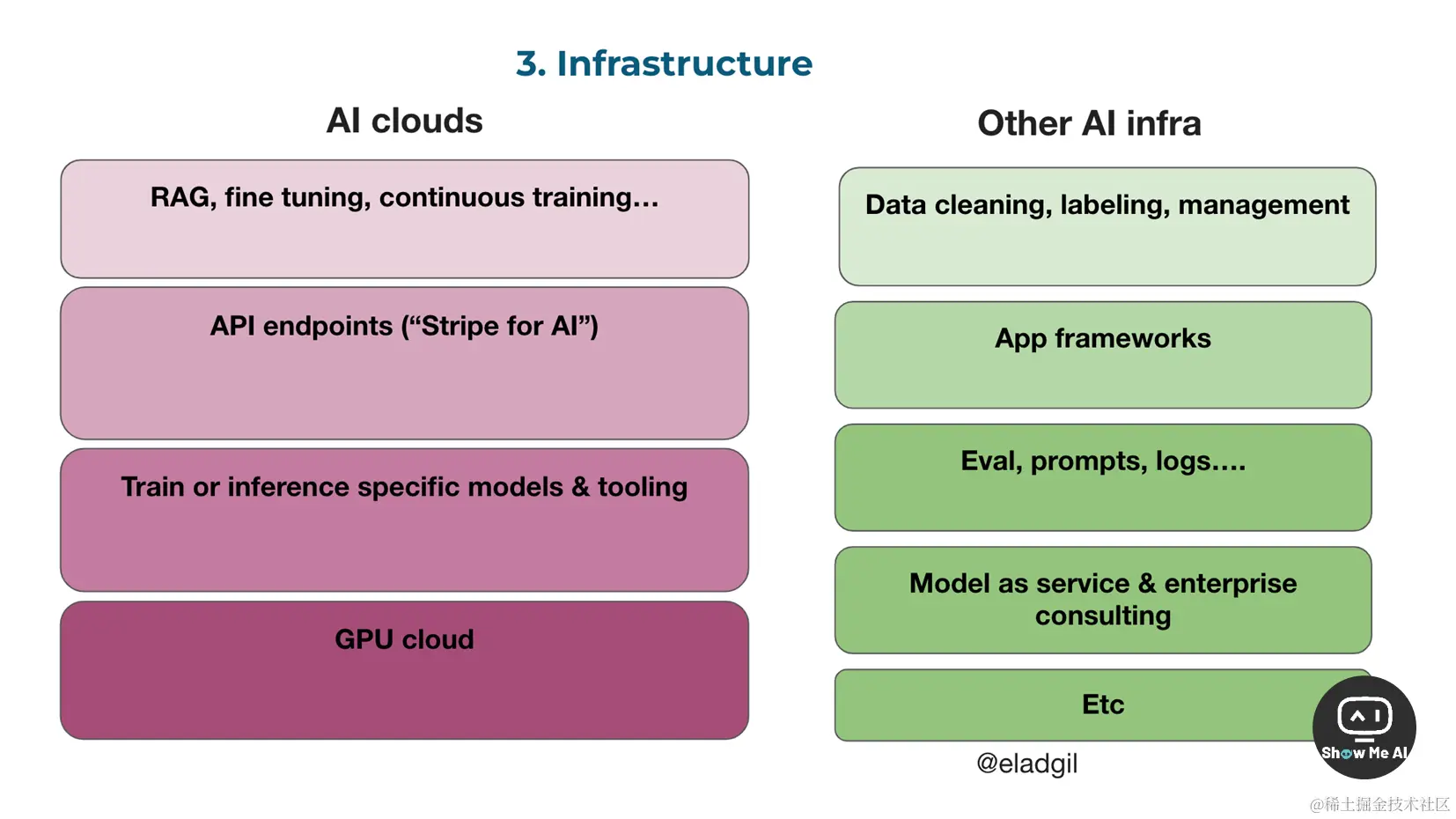
🔔 Questions on Apps
- 15个月前 ChatGPT 问世;距离模型&技术最近的AI研究员和 infra 工程师更能感知其带来的革命和转变,一般经历 9-12个月做出辞职创业的决定;辞职与创业头脑风暴又会花去几个月的时间 → 所以,我们很快就可以看到一波应用构建者集中出现
- Question | B2B:在新兴 B2B 应用浪潮中,需要重点关注哪些公司和市场?与初创公司相比,现有大型企业的优势体现在哪些方面?
- Question | Consumer:最早的AI产品是面向C端消费者的,例如 ChatGPT、Midjourney、Perplexity、Pika等。但是为什么AI生态系统中2C产品并不多呢?是因为上面提到的时间延迟吗?
- Question | Agents:Agents 可以发生很多很多的事情。那么,哪些是强大的垂类产品的天下,哪些又是初创公司可以发挥的空间呢?

🉑 微软·面向初学者的生成式AI课程(第2版),增加了 RAG、AI Agents 和 Fine-Tuning 等内容

github.com/microsoft/g…
微软去年推出了「Generative AI for Beginners」课程,12小节,帮助非常多的学习者掌握了生成式AI的基础知识和开发技能。
前几天,这门课程更新了!官方发布了「Generative AI for Beginners (Version 2)」,不仅对已有章节的概念、作业等进行了更新,还增加了近期热度非常高的 RAG、AI Agents、Fine-Tuning LLMs 等6个新的章节。
课程章节分类「Learn (知识学习)」「Build (动手实践)」两种类型,内容则涵盖了视频介绍、图文讲解、示例代码、课程作业、拓展资源等部分,依旧是学习生成式人工智能基础知识和应用开发技能的首选入门课~
以下是课程核心内容的介绍,有感兴趣的内容,可以开始学习啦:
0. Course Setup
- 课程设置
- [Learn] 如何设置你的开发环境
1. Introduction to Generative AI and LLMs
- 生成性人工智能与大型语言模型简介
- [Learn] 理解生成性人工智能是什么以及大型语言模型 (LLMs) 如何工作
2. Exploring and comparing different LLMs
- 探索和比较不同的 LLMs
- [Learn] 如何为你的用例选择合适的模型
3. Using Generative AI Responsibly
- 负责任地使用生成性人工智能
- [Learn] 如何负责任地构建生成性人工智能应用
4. Understanding Prompt Engineering Fundamentals
- 理解提示工程基础
- [Learn] 实践提示工程最佳实践
5. Creating Advanced Prompts
- 创建高级提示
- [Learn] 如何应用提示工程技术以改善你的提示结果
6. Building Text Generation Applications
- 构建文本生成应用
- [Build] 使用 Azure OpenAI 构建文本生成应用
7. Building Chat Applications
- 构建聊天应用
- [Build] 高效构建和集成聊天应用的技术
8. Building Search Apps Vector Databases
- 构建搜索应用向量数据库
- [Build] 使用嵌入 (Embeddings) 搜索数据的搜索应用
9. Building Image Generation Applications
- 构建图像生成应用
- [Build] 一个图像生成应用
10. Building Low Code AI Applications
- 构建低代码人工智能应用
- [Build] 使用低代码工具构建生成性人工智能应用
11. Integrating External Applications with Function Calling
- 与外部应用集成通过函数调用
- [Build] 什么是函数调用及其在应用中的用例
12. Designing UX for AI Applications
- 为人工智能应用设计用户体验
- [Learn] 在开发生成性人工智能应用时如何应用用户体验设计原则
Version 2 新增内容
13. Securing Your Generative AI Applications
- 保护你的生成性人工智能应用
- [Learn] 人工智能系统面临的威胁和风险以及保护这些系统的方法
14. The Generative AI Application Lifecycle
- 生成性人工智能应用生命周期
- [Learn] 管理 LLM 生命周期和 LLMOps 的工具和指标
15. Retrieval Augmented Generation (RAG) and Vector Databases
- 检索增强生成 (RAG) 和向量数据库
- [Build] 使用 RAG 框架从向量数据库检索嵌入的应用程序
16. Open Source Models and Hugging Face
- 开源模型和 Hugging Face
- [Build] 使用 Hugging Face 上可用的开源模型构建应用程序
17. AI Agents
- 人工智能代理
- [Build] 使用人工智能代理框架构建应用程序
18. Fine-Tuning LLMs文章来源:https://www.toymoban.com/news/detail-843780.html
- 微调 LLMs
- [Learn] 微调 LLMs 是什么、为什么以及如何进行
感谢贡献一手资讯、资料与使用体验的 ShowMeAI 社区同学们!文章来源地址https://www.toymoban.com/news/detail-843780.html
到了这里,关于零一万物黄文灏:没有做出Sora的几点反思;大模型一千零一问;Mistral不愧欧洲之光;微软生成式AI入门课(第2版) | ShowMeAI日报的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!