一、 智能文档处理介绍
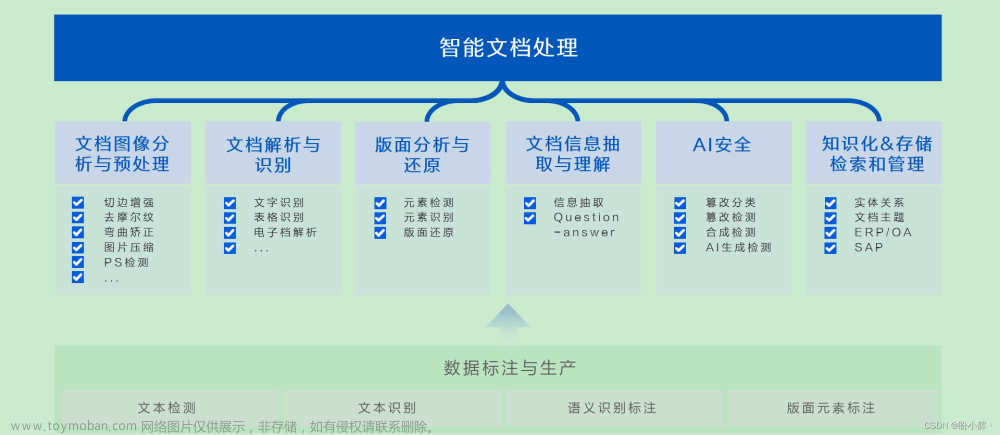
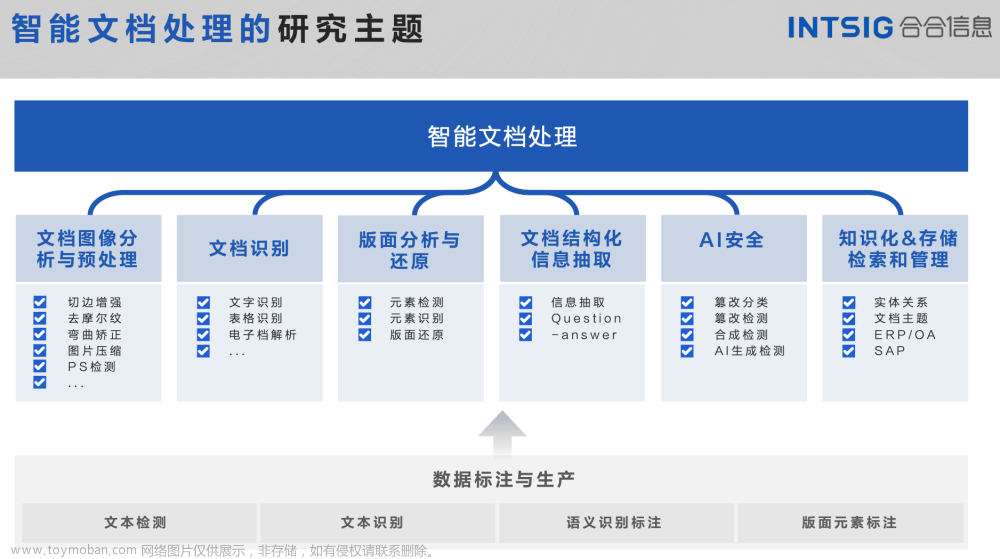
智能文档处理(Intelligent Document Processing, IDP)是利用人工智能(AI)、机器学习(ML)、计算机视觉(CV)、自然语言处理(NLP)等技术自动化地捕获、理解、处理和分析文档内容的过程。不同于传统的文档管理系统,IDP能够处理结构化、半结构化和非结构化的文档,从而提取有用信息并将其转换为可操作的数据。在数字化转型的大背景下,企业和组织面临着处理大量文档数据的挑战。传统的方法依赖于人工输入,不仅效率低下,而且容易出错。智能文档处理技术的出现,标志着从手动到自动化处理文档的重要转变,它通过将AI技术应用于文档管理过程,极大地提高了处理速度和准确性,同时降低了成本。
智能文档处理的发展离不开机器学习、深度学习、OCR(光学字符识别)和自然语言处理等关键技术的进步。早期的文档处理主要依赖于模板匹配和规则-based的方法,这些方法在处理结构化文档时效果不错,但面对复杂的非结构化文档时则显得力不从心。随着深度学习技术的突破,尤其是卷积神经网络(CNN)和循环神经网络(RNN)在图像识别和文本处理领域的应用,使得IDP技术能够更加精准地识别和理解文档内容。此外,BERT、GPT等预训练语言模型的出现,进一步推动了IDP技术在理解复杂语言结构和语义上的能力。
智能文档处理技术的应用意义广泛,涵盖了金融、医疗、法律、教育等多个领域。在金融领域,IDP可以帮助银行和保险公司自动化处理贷款申请、保险理赔等大量的文档工作,提高审批速度和服务质量。在医疗领域,IDP能够自动化处理病历记录、实验报告等,提高医疗记录的准确性和可访问性。在法律领域,IDP可以辅助律师和法官快速查找和分析大量的法律文件和案件记录,提高工作效率。智能文档处理技术正处于快速发展之中,它不仅为企业带来了高效率和成本节约,也为AI技术的应用开辟了新的领域。通过不断的技术创新和应用实践,IDP有望解决更多行业的痛点问题,为数字化转型提供强有力的支持。
<合合TextIn textin.com - 合合信息旗下OCR云服务产品 智能文档处理云台,提供一站式智能文档处理产品服务,提供领先的智能文档处理技术>


二、文档格式解析
文档格式解析是智能文档处理(IDP)流程中的首要步骤,它涉及对文档的结构和内容进行理解,为后续的图像预处理、文字识别和信息提取等环节打下基础。这一过程要求系统能够处理和解析各种文档格式,包括但不限于PDF、DOCX、XLSX、图片格式(如JPG、PNG)等。
文档格式解析指的是将各种格式的文档转换为机器可读和可处理的数据结构的过程。这一过程涉及识别文档的编码格式、提取文本和元数据、理解文档结构(如标题、段落、列表、表格等)以及处理嵌入的元素(如图像、链接等)。
文档格式解析在IDP流程中占据着至关重要的地位。首先,它直接影响到后续处理步骤的效率和准确性。正确解析文档结构和内容能够为文字识别和信息提取提供准确的输入,减少错误传递。其次,文档格式解析的灵活性和广泛性决定了IDP系统能够处理的文档种类,进而影响系统的应用范围和用户体验。
文档格式解析技术主要由以下几部分组成:
1. 格式识别与转换:通过分析文件头信息或使用文件扩展名,确定文档的格式。针对特定格式的解析器将文档转换为统一的数据结构,以便进一步处理。
2. 结构分析:识别和提取文档的逻辑结构,如章节、标题、段落、列表等。这一步骤通常需要利用机器学习或规则-based的方法来实现。
3. 元数据提取:从文档中提取作者、创建日期、修改日期等元数据信息,这些信息在某些应用场景下非常重要。
4. 嵌入元素处理:对文档中嵌入的图像、链接、表格等元素进行识别和提取。对于图像,可能需要调用OCR技术进行文字识别。
<合合TextIn textin.com - 合合信息旗下OCR云服务产品 智能文档处理云台,提供一站式智能文档处理产品服务,提供领先的智能文档处理技术>
三、图像增强技术解析
图像增强技术是智能文档处理(IDP)中的一个关键步骤,它通过改善图像质量来提高后续文字识别(OCR)的准确率。这一技术不仅应用于传统的文档扫描图像,也适用于数字摄影和视频中的图像处理。图像增强技术指的是通过各种算法和处理技术改善图像质量的一系列方法。目标是通过提高图像的可视性或转换图像的形式,使其更适合特定的应用,如提高OCR的识别准确率。图像增强可以包括对比度增强、噪声去除、锐化处理、去模糊等多种技术。
在IDP流程中,图像增强的意义主要体现在以下几个方面:
● 提高准确率:清晰的图像可以显著提高文字识别的准确率,尤其是对于低质量或受损图像。
● 降低处理难度:增强后的图像简化了后续处理步骤,如版面分析和信息提取,因为图像噪声和失真等问题已经得到了解决。
● 增强可用性:某些情况下,原始文档可能因为年代久远、存储条件不佳等原因变得难以阅读,图像增强技术可以恢复这些文档的可用性。
图像增强技术主要包括以下几个方面:
1. 切边增强:切边增强是一种图像处理技术,通过增强图像中的边缘信息来提高图像的清晰度和对比度。该技术会突出显示图像中物体的边缘轮廓,使其更加清晰鲜明,从而改善图像的质量和可视效果。
2. 去摩尔纹:去摩尔纹技术是一种用于消除图像中出现的摩尔纹现象的方法。摩尔纹是由于图像采样频率与被拍摄物体纹理之间的相互作用而产生的干扰,常见于数字图像和扫描图像中。去摩尔纹技术通过数学算法或滤波器处理来减少或消除这种干扰,从而提高图像的质量和清晰度。
3. 弯曲矫正:弯曲矫正技术是一种用于修正图像中出现的弯曲或畸变现象的方法。在图像采集或传输过程中,由于设备或介质的问题,图像可能会发生弯曲或失真,影响图像的观感和应用效果。弯曲矫正技术通过数学模型或几何校正算法来对图像进行修正,使其恢复到原始状态或更接近真实场景,提高图像的可用性和可视化效果。
4. 去模糊:去模糊技术是一种用于消除图像中模糊或不清晰部分的方法。图像模糊可能是由于摄像机晃动、焦点不准或运动模糊等因素引起的。去模糊技术通过分析图像模糊的原因并应用相应的算法或滤波器来恢复图像的清晰度和细节,使其更具可读性和观赏性。
<合合TextIn textin.com - 合合信息旗下OCR云服务产品 智能文档处理云台,提供一站式智能文档处理产品服务,提供领先的智能文档处理技术>
四、传统文字识别OCR技术解析
文字识别技术,通常称为光学字符识别(OCR),是智能文档处理(IDP)中的核心环节。OCR技术使计算机能够从图像中识别和转录打印或手写文本,将图像文件转换为可编辑和可搜索的文本数据。OCR技术通过分析图像中的文字区域,识别出其中的字符,并将这些字符转换为电子文本格式。这项技术能够处理各种来源的文档图像,包括扫描文档、照片中的文字以及屏幕截图等。
传统OCR技术的实现主要依赖以下几个步骤:
1. 文字定位:通过检测图像中的文字区域,确定文字的位置和边界。这一步骤通常采用边缘检测、连通区域分析等技术,以识别出图像中的文字部分,并对其进行标记或边界框定位。
2. 文字分割:将定位到的文字区域进行分割,将每个文字字符分离出来,为后续的文字识别做准备。文字分割通常使用投影分割、连通区域分割等方法,将文字区域划分为单个字符或单词。
3. 特征提取:对分割后的文字字符进行特征提取,将文字字符转换成计算机可识别的特征向量或特征描述子。常用的特征提取方法包括形状特征、结构特征、灰度特征等,用于描述文字字符的形态和结构特征。
4. 文字识别:利用模式识别算法,对提取到的文字特征进行分类和识别,将文字字符转换成对应的文本信息。
<合合TextIn textin.com - 合合信息旗下OCR云服务产品 智能文档处理云台,提供一站式智能文档处理产品服务,提供领先的智能文档处理技术>
五、深度学习OCR技术解析
光学字符识别(Optical Character Recognition, OCR)技术,特别是基于深度学习的OCR,已成为智能文档处理(IDP)领域的核心技术之一。深度学习OCR利用复杂的神经网络模型来识别和转换图像中的文字为机器可读的形式。 深度学习OCR技术是指使用深度学习模型,特别是卷积神经网络(CNN)和循环神经网络(RNN),来识别图像中的文字的技术。不同于传统OCR技术,深度学习OCR能够更好地处理字体变化、布局复杂、背景嘈杂等问题,显著提高了文字识别的准确率和鲁棒性。
在IDP流程中,文字识别是将扫描的纸质文档或数字图像中的文字内容转换为电子文本的关键步骤。深度学习OCR的应用不仅提高了识别精度,还极大地扩展了OCR技术的应用范围,包括复杂文档的处理、多语言识别、手写文字识别等。此外,它还为后续的信息提取、内容理解提供了高质量的输入。
深度学习OCR技术的实现主要依赖以下几个步骤:
1. 数据收集与标注:收集大规模的带有标注的图像数据集,包括不同字体、大小、颜色和背景的文字图像。这些图像需要经过手工标注,标注每个字符的位置和对应的文本内容,以用于深度学习模型的训练。
2. 数据预处理:对收集到的图像数据进行预处理,包括图像去噪声、尺度归一化、灰度化、裁剪等操作,以减少数据的噪声和干扰,提高深度学习模型的训练效果。
3. 模型选择与训练:选择合适的深度学习模型架构,如卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)、转录者(Transformer)等,进行模型的训练和优化。在训练过程中,使用标注好的图像数据集,通过反向传播算法和梯度下降优化算法,不断调整模型参数,使其能够准确地识别文字。
4. 模型评估与调优:通过验证集或测试集对训练好的深度学习模型进行评估,包括识别准确率、召回率、精确率等指标的评估。根据评估结果,对模型进行调优和改进,以提高模型的识别准确性和泛化能力。
<合合TextIn textin.com - 合合信息旗下OCR云服务产品 智能文档处理云台,提供一站式智能文档处理产品服务,提供领先的智能文档处理技术>
六、深度学习版面分析技术解析
版面分析是智能文档处理(IDP)中的关键环节,它涉及对文档页面的结构和布局进行分析,以识别和分类文档中的各种元素,如文本块、图像、表格等。随着深度学习技术的发展,版面分析的能力得到了显著提升,使得处理复杂文档布局成为可能。 深度学习版面分析技术利用深度神经网络,尤其是卷积神经网络(CNN)和循环神经网络(RNN),对文档页面的布局和结构进行自动分析和理解。这项技术能够识别页面上的不同元素类型,并理解它们之间的空间关系和逻辑结构,为后续的文本识别、内容提取和信息理解提供基础。
在IDP流程中,版面分析的意义主要体现在以下几个方面:
支持复杂文档处理:深度学习技术使版面分析能够处理多样化和复杂的文档布局,提高了系统的适用范围。
● 自动化内容提取:准确的版面分析为提取特定信息(如表格数据、标题、摘要等)提供了可能,进一步促进了文档自动化处理的实现。
深度学习版面分析技术主要包括以下几个关键步骤:
1. 元素检测:利用深度学习模型,如目标检测模型(如Faster R-CNN、YOLO、SSD等),对文档图像中的各种元素进行检测和定位。这些元素可以包括文字、图像、表格、标题等。通过元素检测,可以确定文档中不同元素的位置和边界框,为后续的分析和处理提供基础。
2. 元素分类:对检测到的元素进行分类,区分文字、图像、表格等不同类型的元素。这一步骤可以采用深度学习中的图像分类模型或目标分类模型,对每个元素进行识别和分类,以便后续的结构解析和语义理解。
3. 结构解析:在元素检测和分类的基础上,进行文档的结构解析,识别文档中不同元素之间的关系和层次结构。这包括文本段落与标题的对应关系、表格中不同字段的关系等。深度学习模型可以通过对文档布局和语义信息的分析,实现对文档结构的自动解析和理解。
4. 版面校正:对检测到的文档元素进行版面校正,使其在整体文档中的位置和排布更加合理和统一。这一步骤可以包括文本对齐、图像矫正、表格对齐等操作,以提高文档的可读性和美观性。版面校正也可以通过深度学习模型来实现,例如基于生成对抗网络(GAN)的版面重构方法。
<合合TextIn - 合合信息旗下OCR云服务产品 智能文档处理云平台提供一站式智能文档处理产品服务,提供领先的版面分析技术产品>
七、文档分类
文档分类是智能文档处理(IDP)中的一个关键环节,它涉及自动将文档按照其内容、用途或结构分类到预定义的类别中。随着人工智能和机器学习技术的发展,文档分类的方法和效率都有了显著的提升。本章节将从定义、流程中的意义、技术组成、技术发展等多个维度全面介绍文档分类技术。文档分类指的是利用计算机程序自动识别和归类文档的过程。这涉及到理解文档的内容和结构,并将其分配到一个或多个预设的类别中。分类的依据可以是文档的主题、风格、作者、发布日期等多个维度。
文档分类技术主要包括:
1. 使用图片特征分类:图片特征的分类主要依赖于从文档中提取的视觉信息。这通常涉及到图像处理和计算机视觉技术,用于识别文档中的图形、布局和其他视觉元素。其中步骤包含特征提取、特征表示和降维、分类模型构建等步骤。
2. 使用文本特征分类:文本特征的分类依赖于文档中的文字内容,涉及自然语言处理(NLP)技术,用于理解和分类文档的语义内容。其中步骤包含文本预处理、特征提取、模型构建、模型评估等步骤。
<合合TextIn - 合合信息旗下OCR云服务产品 智能文档处理云平台提供一站式智能文档处理产品服务,提供领先的文档分类技术>
八、信息抽取
信息抽取(Information Extraction, IE)是智能文档处理(IDP)中的关键技术之一,它涉及从非结构化或半结构化文档中自动识别和提取出有价值的信息,如实体、关系、事件等。随着自然语言处理(NLP)和机器学习技术的发展,信息抽取的能力和应用范围不断扩大。
信息抽取技术指的是利用计算机算法从文本中自动识别和提取预定义类型的信息的过程。这些信息通常包括但不限于人名、地点、组织、时间表达、专有名词、事件和实体之间的关系等。
意义
在IDP流程中,信息抽取的意义主要体现在:
● 支持决策和分析:通过从大量文档中抽取关键信息,可以为决策制定和数据分析提供有价值的输入。
● 提高自动化程度:自动化的信息抽取减少了人工审核和录入的需要,提高了处理效率和准确性。
● 促进知识管理:信息抽取有助于构建知识库,支持知识检索和管理。
技术
信息抽取技术主要包括以下几个关键组成部分:
1. 实体识别(Named Entity Recognition, NER):识别文本中的具名实体,如人名、地点和组织。
2. 关系抽取:识别文本中实体之间的关系,如“公司-CEO”或“人物-出生地”等。
3. 事件抽取:识别文本中的事件及其相关属性和参与实体,如事件类型、时间、地点和参与者等。
4. 观点抽取(Opinion Mining):从文本中抽取观点、情感和评价,通常用于产品评论、市场分析等领域。
5. 术语抽取:从专业文档中识别和提取关键术语和定义,用于构建术语库或知识图谱。
发展
信息抽取技术的发展经历了以下几个阶段:
● 规则基础方法:早期的信息抽取系统主要依赖于手工编写的规则。这种方法在特定领域内效果明显,但缺乏通用性和扩展性。
● 机器学习方法:随着机器学习技术的发展,信息抽取开始采用监督学习、半监督学习和无监督学习方法。通过训练模型识别文本模式,提高了抽取的准确率和灵活性。
● 深度学习方法:近年来,基于深度学习的信息抽取方法成为研究热点,尤其是利用CNN、RNN和Transformer等神经网络模型。这些模型能够更好地理解文本的深层次语义,显著提高了信息抽取的性能。
● 端到端信息抽取:最新的研究趋势是开发端到端的信息抽取系统,这些系统能够直接从原始文本中抽取出结构化信息,无需复杂流程。
<合合TextIn - 合合信息旗下OCR云服务产品 智能文档处理云平台提供一站式智能文档处理产品服务,提供领先的信息抽取技术>
九、系统集成:将IDP处理后的数据集成到企业系统
系统集成在智能文档处理(IDP)完成之后,将处理得到的结构化数据有效地集成到企业的业务系统中,对于提升企业的业务流程效率和推进企业信息化建设至关重要。这一过程需要将IDP系统与企业内部的各种业务系统(如CRM、ERP、CMS等)以及全球主流的企业软件平台进行有效对接。本章节将详细介绍IDP处理后的数据如何通过多种方式集成到中国及全球的主流各种业务系统里,服务于企业业务流程和企业信息化。
数据集成的方式
API集成
● 定义:应用程序接口(API)提供了一种让不同软件系统彼此通信的方法。通过开发和使用API,IDP系统可以将结构化数据直接发送到目标业务系统。
● 应用场景:实时数据传输、需要高度定制化集成的场景。
文件导入/导出
● 定义:一种基础但广泛使用的数据集成方法,涉及将数据导出为通用格式(如CSV、XML、JSON等),然后导入到目标系统。
● 应用场景:批量数据处理、非实时数据更新需求。
数据库集成
● 定义:直接通过数据库级别的操作,将IDP处理后的数据存储到企业的数据库系统中,再由各业务系统从数据库中读取所需数据。
● 应用场景:数据量大、需要长期存储和复用的场景。
集成到全球主流业务系统的示例
集成到CRM系统
● 场景:将客户相关的文档(如合同、通信记录)处理后的数据自动更新到客户关系管理(CRM)系统,以提供更准确的客户视图和服务。
● 技术方式:API集成、数据库集成。
集成到ERP系统
● 场景:将发票、订单等财务文档处理后的数据自动录入企业资源计划(ERP)系统,简化财务流程,提高财务处理速度和准确性。
● 技术方式:文件导入/导出、API集成。
集成到CMS系统
● 场景:将新闻、报告等内容文档处理后的数据自动归档和分类到内容管理系统(CMS),加速内容的发布流程。
● 技术方式:API集成、中间件技术。
集成到全球云平台
● 场景:将处理后的数据集成到阿里云、百度云、AWS、Azure、Google Cloud等全球云平台提供的数据库和应用服务中,利用云平台的强大计算和存储能力支持企业的大数据分析和应用开发。
● 技术方式:API集成、中间件技术。
<合合TextIn - 合合信息旗下OCR云服务产品 智能文档处理云平台提供一站式智能文档处理产品服务,提供API集成文档、全语言示例代码> 文章来源:https://www.toymoban.com/news/detail-843812.html
文章来源:https://www.toymoban.com/news/detail-843812.html
如有帮助,请多关注
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。文章来源地址https://www.toymoban.com/news/detail-843812.html
到了这里,关于智能文档处理技术综述的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!