RFN-Nest: An end-to-end residual fusion network for infrared and visible images
RFN-Nest:红外与可见光图像的端对端残差融合网络
宝子们,今天学习了RFN-Nest这篇文献,和上一篇的DenseFuse同一个作者。下面是我的学习记录,希望对各位宝子们有所帮助~

介绍
设计可学习的融合策略是图像融合领域的一个极具挑战性的问题。前面我们学习的DenseNet就是手工融合策略。
本文提出一种新的端对端融合网络架构(RFN-Nest)的红外和可见光图像融合,提出了一种基于残差结构的残差融合网络(RFN),提出了一种新的细节保持损失函数和特征增强损失函数来训练RFN。融合模型的学习是由一个新的两阶段的训练策略,第一阶段,基于创新的嵌套连接(Nest)概念训练自动编码器,第二阶段,利用损失函数来训练RFN。
主要贡献
1、提出了一种新的残差融合网络(RFN)来代替手工的融合策略;
2、由于特征提取和特征重构能力是编码器和解码器网络的关键,因此设计了一个两阶段的训练策略来设计网络;
3、设计了一个能够保留图像细节的损失函数,以及一个增强损失函数的特征来训练RFN网络。
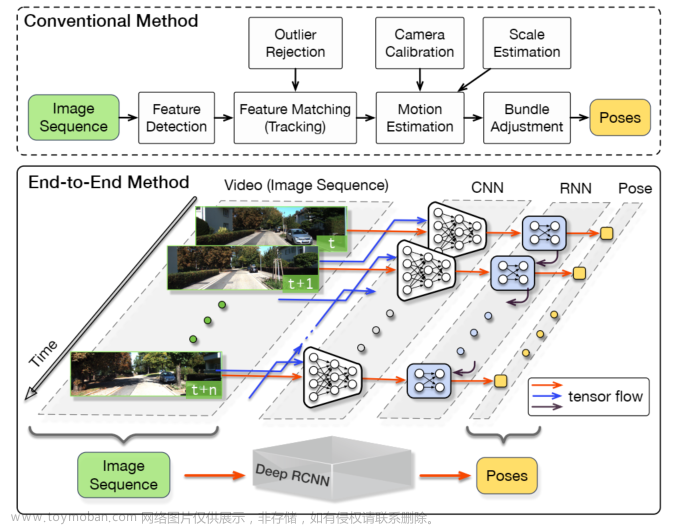
融合网络架构
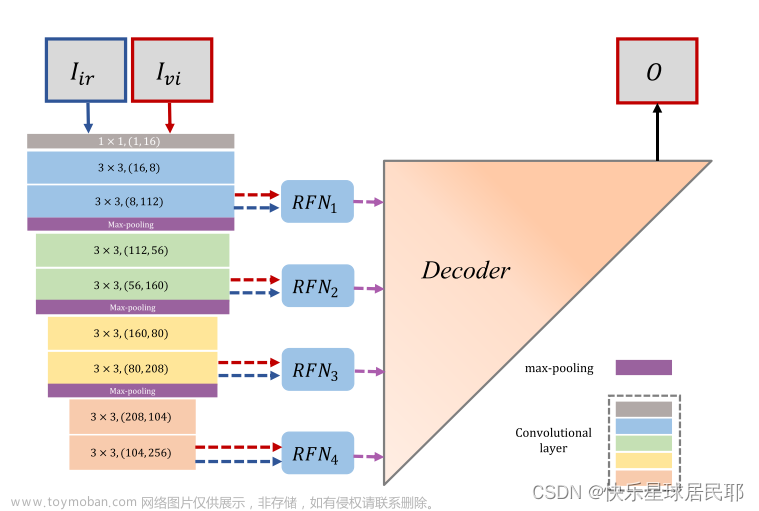
RFN-Nest包含三个部分:编码器(左)、残差融合网络(RFN 1-4)和解码器(右)。
对于卷积层:“k*k,(in, out)”,表示内核大小为k*k,输入通道为in,输出通道为out。通过编码器网络中的最大池化操作,可以从源图像中提取多尺度深度特征。
RFN用于融合在每个尺度上提取的多模态深度特征,浅层特征保留了更多的细节信息,而深层特征则传达了语义信息。
最后,融合后的图像重建的嵌套连接的解码网络,充分利用了多尺度结构的特征。
残差融合网络RFN
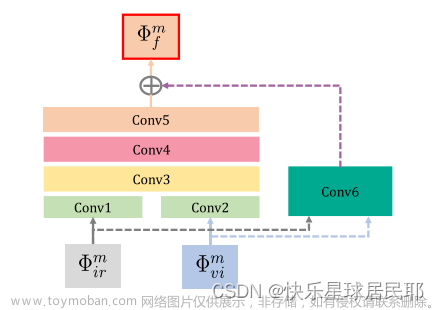
表示由编码器网络提取的第m尺度深度特征,其中m属于(1,2,3,4)。“Conv 1-6”表示RFN中的六个卷积层,在该残差网络中,“Conv1”和“Conv2”的输出作为“Conv3”的输入。“Conv6”是生成初始融合特征的第一个融合层。(有点儿像ResNet)
解码器网络
基于嵌套连接架构的解码器网络如下图所示:
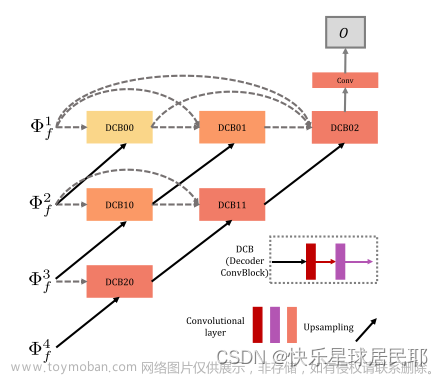
表示由RFN网络获得的融合多尺度特征,“DCB”表示解码器卷积块,其具有两个卷积层。在每行中,这些块通过类似于密集块架构的短连接连接,跨层链路连接解码器网络中的多尺度深度特征。
两阶段训练策略
自动编码器网络的训练
在第一阶段,编码器网络被训练以提取多尺度深度特征,训练解码器网络以重建具有多尺度深度特征的输入图像。
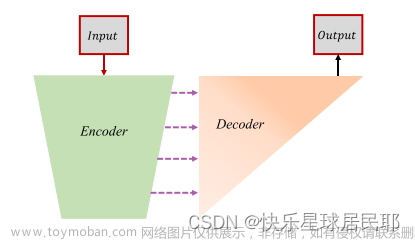
特征提取部分包括一个下采样操作(最大池化),它以四个尺度提取深度特征,这些多尺度深度特征被馈送到解码器网络中以重建输入图像。该算法利用短的跨层连接,充分利用多尺度深度特征对输入图像进行重构。
1、损失函数:
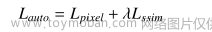
其中Lpixel和Lslim表示输入图像(Input)和输出图像(Output)之间的像素损失和结构相似性损失。λ是Lpixel和Lslim之间的折衷参数。
2、像素损失
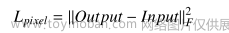
3、结构相似性(SSIM)损失

RFN的训练
RFN的提出,实现一个完全可学习的融合策略。在第二阶段,在编码器和解码器固定的情况下,RFN用适当的损失函数训练。训练过程如下图:
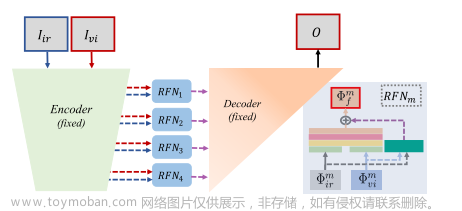
利用固定编码器网络从源图像中提取多尺度深度特征,对于每个尺度,RFN用于融合这些深特征,然后融合的多尺度特征被馈送到固定解码器网络中。
1、为了训练RFN,提出了一个新的损失函数LRFN:

其中Ldetail和Lfeature分别指示背景细节保留损失函数和目标特征增强损失函数。α是一个权衡参数。
2、背景细节信息主要来自可见光图像,背景细节保留损失函数:

3、由于红外图像比可见光图像包含更多的显著目标特征,因此设计了目标特征增强损失函数:
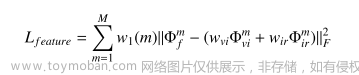
M是多尺度深度特征的数量,其被设置为4。由于尺度之间的幅度差异,w1是用于平衡损失幅度的折衷参数向量。它假定四个值{1,10,100,1000}。Wvi和Wir控制融合特征图中可见和红外特征的相对影响。
由于可见光信息受到Ldetail的约束,并且Lfeature的目的是从红外图像中保留显著特征,因此Wir通常大于Wvi。
训练
1、在第一阶段,使用数据集MS-COCO来训练自动编码器网络,选取80000幅图像构成训练集。这些图像被转换为灰度级并重新调整为256*256。参数λ被设置为100以平衡Lpixel和Lslim之间的幅度差。批量大小和epoch分别设置为4和2。学习率设定为1 × 10e−4。
2、在第二阶段,选择KAIST数据集来训练RFN网络,包含近90000对图像,在这个数据集中,选择了80000对红外与可见光图像进行训练,这些图像也转换为灰度级,并调整为256*256。批量大小和epoch分别设置为4和2。学习率也设定为1 × 10e−4,与第一阶段相同。
测试
1、测试图像来自TNO和VOT 2020-RGBT收集的两个数据集。第一个数据集包含从TNO收集的21对红外和可见光图像,第二个数据集包含从TNO和VOT 2020-RGBT收集的40对红外和可见光图像。
2、使用六个质量指标来客观评价融合算法:Entropy(En),标准差(SD),互信息(MI),改进的融合伪影测量(Nab f),用于评估融合图像中的噪声信息;差异相关性之和(SCD)以及多尺度结构相似性(MS-SSIM)。
结论
针对现有融合方法在图像细节保护方面的不足,提出了一种基于嵌套连接的端到端融合框架(RFN-Nest)。为了设计RFN-Nest,提出了一个两阶段的训练策略。在所提出的方案中,使用SSIM损失函数(Lssim)和像素损失函数(Lpixel)训练自动编码器网络。利用训练好的编码器从源图像中提取多尺度特征,设计基于嵌套连接的解码器网络,利用融合后的多尺度特征重构融合图像。RFN Nest的关键组件是残差融合网络(RFN)。在训练策略的第二阶段,训练四个残差融合网络(RFN)来保留图像细节,并分别使用Ldetail和Lfeature来保留显著特征。一旦两阶段训练完成,融合图像的重建使用编码器,RFN网络和解码器。文章来源:https://www.toymoban.com/news/detail-843820.html
参考文献
RFN-Nest: An end-to-end residual fusion network for infrared and visible images文章来源地址https://www.toymoban.com/news/detail-843820.html
到了这里,关于【论文笔记3】RFN-Nest: An end-to-end residual fusion network for infrared and visible images的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!