ACM MM22会议上的一篇文章,用于做表情微表情检测的。中科院Wang Sujing团队的工作,合作者是英国曼彻斯特大学的学者。
摘要:
Optical flow is susceptible to drift error,which introduces a serious problem for motions with long-term dependencies,such as high frame-ratemacro-expression.
光流对漂移误差敏感,特别是对于具有长期依赖性的运动,如高帧率宏表情,存在严重问题。
We propose a purely deep learning solution which,rather than tracking framedifferential motion,compares via a convolutional model,each frame with two temporally localreference frames.
提出了一种纯深度学习解决方案,与其追踪帧差异运动不同,通过卷积模型比较每一帧与两个时间局部参考帧。
drift error
漂移误差是指在光流方法中,由于一系列计算的累积效应,导致跟踪物体位置时逐渐偏离真实位置的现象。光流方法基于在图像序列中计算相邻帧之间的像素位移,以捕捉物体的运动。然而,由于多次计算和累积,计算中的一些不确定性或错误可能导致位置估计的逐渐偏离。
漂移误差可能是由于多种因素引起的,包括图像噪声、运动模糊、非刚性运动等。这些误差会随着时间的推移而累积,最终导致跟踪的物体位置与真实位置之间存在显著的偏差。漂移误差是光流方法的一个挑战,尤其是在需要准确追踪物体长时间运动的应用场景中,如高帧率宏表情的分析。
1.简介
Facial expressions can be classified into two groups:macro-expression(MaE)and micro-expression(ME).These classifications are based on their relative duration and intensity,
面部表情可分为宏表情(MaE)和微表情(ME)两组,基于它们的相对持续时间和强度进行分类。
As it is an involuntary reaction,the emotionalstate of a person can be revealed through analysing MEs.
由于微表情是一种无意识的反应,通过分析微表情可以揭示一个人的情感状态。
Most of the previous methods utilise long short-term memory(LSTM)[13,14]or optical flow[13,15,16,17]to detecttemporal correlation of video sequences.
大多数先前的方法利用长短时记忆(LSTM)或光流来检测视频序列的时间相关性,但它们在计算上都很昂贵。
We also noticed that previous attempts lack duration centred analysis.We takeadvantage of the major difference between ME and MaE(they occur for different duration,where ME occurs less than0.5s while MaE occurs in 0.5s or longer)and propose a two-stream network with a different frame skip based on theduration differences for ME and MaE spotting.
我们注意到先前的尝试缺乏基于持续时间的分析,因此提出了一个基于两者持续时间差异的两流网络,用于微表情和宏表情的识别。
全文贡献:
the first end-to-end deep learning ME and MaE spotting method trained from scratch usinglong video datasets.
第一个从头开始使用长视频数据集训练的端到端深度学习微表情(ME)和宏表情(MaE)识别方法。
Our method uses a two-stream network with temporal oriented reference frame.The reference frames are twoframe pairs corresponding to the duration difference of ME and MaE.The two-stream network also possessesshared weights to mitigate overfitting.
我们的方法采用了一个双流网络,其中包含针对时间的定向参考帧。这些参考帧是两个帧对,对应于ME和MaE的持续时间差异。另外,双流网络还具有共享权重以减轻过拟合的特点。
The network architecture consists of only 3 convolutional layers with the capability of detecting co-occurrenceof ME and MaE using a multi-label system.
网络架构仅包含3个卷积层,能够使用多标签系统检测ME和MaE的共同出现。
To make the network less susceptible to uneven illuminations,Local Contrast Normalisation(LCN)is includedinto our network architecture.
为了使网络对不均匀的光照更不敏感,我们在网络架构中引入了局部对比度归一化(LCN)。
2.提出的方法
By using the duration difference of ME and MaE,wepropose a two-stream 3D-Convolutional Neural Network(3D-CNN)with temporal oriented frame skips.
通过利用ME和MaE的持续时间差异,我们提出了一种带有时间定向帧跳跃的双流3D卷积神经网络(3D-CNN)。
We define thetwo“streams"as ME and MaE pathways,as illustrated in Fig.1.They are structurally identical networks with sharedweights,but differ in frame skips.We use 3 convolutional layers and pool all the spatial dimensions before the denselayers using global average pooling.This design constrains the network to focus on regional features,rather than globalfacial features.
我们将这两个“流”定义为ME和MaE路径,如图1所示。它们是结构相同但具有共享权重的网络,不同之处在于帧跳跃。我们使用3个卷积层,并在密集层之前使用全局平均池化来合并所有空间维度。这个设计限制了网络关注区域性特征,而不是全局的面部特征。
we further propose that normalising the brightness and/or contrast of the images.
我们进一步提出对图像的亮度和/或对比度进行归一化。
整个模型的框架,双流代表两个任务,表情检测与微表情检测。

2.1预处理
LCN[23]was inspired by computational neuroscience models that mimichuman visual perception[24]by mainly enhancing low contrast regions of images.
使用 Local Contrast Normalisation (LCN) 进行图像对比度的归一化,该方法受计算神经科学模型启发,主要通过增强图像的低对比度区域来模拟人类视觉感知。
这个是LCN的效果。

LCN normalises the contrast of animage by conducting local subtractive and divisive normalisations[23].It performs normalisation on local patches(per pixel basis)by comparing a central pixel value with its neighbours.
LCN 通过局部减法和除法归一化来规范化图像的对比度,通过比较中心像素值与其邻居的值,对每个像素进行局部补丁的归一化。
The unique feature of LCN is its divisivenormalisation,which consists of the maximum of local variance or the mean of global variance.
LCN 的独特之处在于其除法归一化,包括局部方差的最大值或全局方差的均值。这种方法对光照不均匀的情况具有鲁棒性,能够在亮度或对比度发生变化时保持面部特征的稳定。
In our implementation,Gaussian convolutions are used to obtain the local mean and standard deviation.Gaussian convolution acts as a low pass filter which reduces noise.
在实现中,使用高斯卷积获取局部均值和标准差,高斯卷积充当低通滤波器以减少噪音。
LCN的计算方式

2.2网络结构
We propose a two-stream network using a 3D-CNN(network architecture shown in Figure 1).Our network takesadvantage of the duration differences of ME and MaE and encouraging one network to be more sensitive to ME and theother to MaE.This is made possible by using a different number of skipped frames in each respective stream(usingthe maximum duration of a ME,0.5s,as the threshold for the duration difference).
我们提出了一个基于3D-CNN的两流网络(如图1所示),利用ME和MaE的持续时间差异,通过在每个流中使用不同数量的跳帧来使一个网络对ME更敏感,另一个对MaE更敏感。
The frame skips are determined based on the k-th frame.The k-th frame,described byMoilanen et al.[25],is the average mid-point of odd-numbered facial expression interval of the whole dataset.
跳帧的确定基于第k帧,该帧是数据集整个表情间隔的奇数平均中点。
To the best of our knowledge,we are the first in ME spotting to weight imbalanced datasetsusing a loss function.
我们是微表情(ME)识别中首次使用损失函数对不平衡数据集进行加权的先行者。
这个是整个网络的损失函数
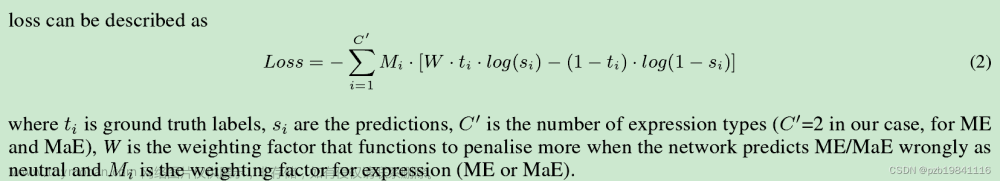
Depthwiseconvolution is convolution applied on individual channels instead of all channel at once(as in regular convolutional).Pointwise convolution is convolution that uses a 1×1 kernel with a third dimension of d(where d is the number ofchannels)on the feature maps.
深度卷积是对各个通道进行卷积,而不是像常规卷积一样一次对所有通道进行卷积。点卷积使用具有第三维度d(其中d是通道数)的1×1内核对特征图进行卷积。
GAP
GAP层用于将卷积输出进行平均池化,以强制模型对局部面部运动进行建模。这有助于捕捉图像中的局部特征。实现: 在卷积输出上应用全局平均池化,将特征图的每个通道进行平均,生成一个全局平均值。这样可以减少整个特征图的维度,同时保留每个通道的重要信息。
A global average pooling(GAP)layer is used to flatten the convolution output andenforce modelling of localised facial movements.
全局平均池化(GAP)层用于压平卷积输出并强制对局部面部运动进行建模。这里采用GAP,而非1×1卷积再普通池化,感觉是为了降低计算量,因为GAP的能力应该弱于
1×1卷积+普通池化。
The output layer consists of two dense nodes with sigmoid activation representing the presence of MEand MaE.
输出层包含两个带有Sigmoid激活的密集节点,分别表示ME和MaE的存在。
3.实验
Randomised frame skips are used in training and validation.This creates a more realistic scenario as theduration of each facial expression is unknown in real life.
在训练和验证过程中使用随机帧跳过,以更真实地模拟实际情况,因为在现实生活中每个面部表情的持续时间是未知的。
4.结果
We apply the Intersection over Union(IoU)method used in Micro-Expression Grand Challenge(MEGC)III[16,29]tocompare with other methods.
我们应用了微表情大赛(MEGC)III中使用的交并比(IoU)方法来与其他方法进行比较。
计算的方法如下,与图像分割有些类似

实验的数据集是SAMM-LV和CAS(ME)2,实验结果肯定是本文的好。
Butterworth filter
Butterworth滤波器是一种常用的信号处理滤波器,属于低通滤波器类型。它的主要作用是通过去除信号中的高频噪声,同时保留低频信号,来平滑或清除信号中的不需要的频率成分。
The main advantage of this filter is it has a flat magnitude filter whereby signalswith frequency below cut-off frequency do not undergo attenuation.
该滤波器的主要优势在于其具有平坦的幅度响应,低于截止频率的信号不会受到衰减。
Multi-Scale Filter
Multi-Scale Filter(多尺度滤波器)通常用于增强信号中的特定频率成分,以帮助检测或突出感兴趣的信号特征。
5.结论
We presented a temporal oriented two-stream 3D-CNN model that shows promising results in ME and MaE spotting inlong video sequences.Our method took advantage of the duration difference of ME and MaE by making a two-streamnetwork that is sensitive to each expression type.Despite only having 3 convolutional layers,our model showedstate-of-the-art performance in SAMM-LV and remained competitive in CAS(ME)2.LCN has proven to have significantimprovement in our model and the ability to address uneven illumination,which is a major weakness of optical flow.
1. 我们提出了一种以时间为导向的两流3D-CNN模型,对长视频序列中的微表情(ME)和宏表情(MaE)有良好的检测效果。2. 我们的方法利用了ME和MaE的持续时间差异,通过创建一个对每种表情类型都敏感的两流网络来实现。3. 尽管我们的模型只有3个卷积层,但在SAMM-LV中表现出最先进的性能,并在CAS(ME)2中保持竞争力。4. LCN在我们的模型中取得了显著的改善,并且能够解决光流法的主要缺陷之一,即不均匀光照。
文章来源地址https://www.toymoban.com/news/detail-843862.html
文章来源:https://www.toymoban.com/news/detail-843862.html
到了这里,关于3D-CNN FOR FACIAL MICRO-AND MACRO-EXPRESSIONSPOTTING ON LONG VIDEO SEQUENCES USING TEMPORALORIEN阅读笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!