原作:Jamie W
引言:当我第一次看到Sora演示视频时,我产生了一个惊人的想法:这个奇迹是否是由UE5和Render的结合驱动的?还有其他什么方式可以如此生动地呈现出咖啡杯海盗船上汹涌澎湃的海洋或者速度飞驰汽车后面翻滚扬尘呢?
/Gemini翻译/
然而,一位视觉算法专家迅速否定了我对Sora依赖像Unreal Engine或Blender等游戏引擎的想法。他澄清说,Sora操作时并不需要明确的物理模拟,就像ChatGPT在英语方面表现出色一样,并不受到语法严格规则的限制。这证明了Sora天生对物理和空间深度的把握。
一名来自a16z的投资者在Twitter上分享了一个流行但有缺陷的对Sora底层机制的分析,将其过程分解为使用CLIP作为基础,将文本转换为3D对象,并将这些对象与游戏引擎中的骨骼和路径进行集成以进行模拟。然后,结果据称被馈送到视频扩散模型中。
然而,任何熟悉 OpenAI Sora 技术报告的人都会看到其中的过度简化。
Sora 团队将他们的创作描述为“涌现能力”的产品——这些能力使 Sora 能够模拟物理世界中的人、动物和环境的某些方面,这是通过扩展训练实现的,由数万个 GPU 提供支持。从本质上讲,他们利用蛮力训练计算来创造奇迹。
Sora 的核心是 Diffusion Transformer,这是一个受大型语言模型 (LLMs) 启发的有远见的模型,旨在处理视觉数据。这涉及将视频数据压缩到时空补丁中,类似于 LLMs 理解的标记,然后对其进行训练并重新组装成新的高清视频序列。这种创新方法不仅简化了复杂的视频数据世界,而且还与 transformers 的处理能力保持一致,标志着从Unreal Engine 5(UE5)的手动精度到 Sora 的直观、数据驱动的见解的重大飞跃。
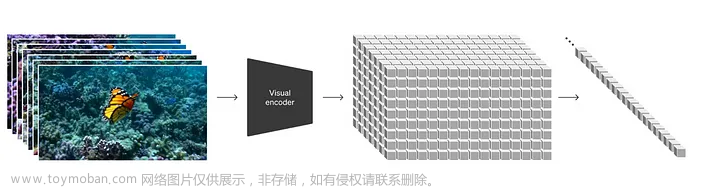
patches diagram
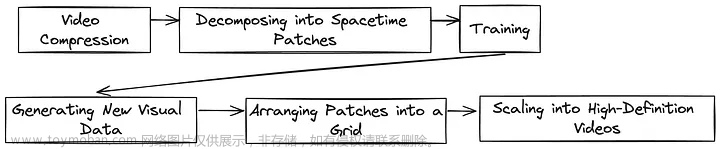
此外,Sora代表了向统一的视觉数据模型转变的趋势,能够生成图像和视频。这种多功能性扩展到各种功能,从文本、图像甚至其他视频生成视频,到增强和拼接视频。让Sora脱颖而出,真正令我印象深刻的是它在描绘角色、物体和场景方面的无与伦比的一致性,远远超过了诸如Runway和Stable Diffusion或Midjourney等图像生成器的能力。文章来源:https://www.toymoban.com/news/detail-843907.html
正如我们在Midjourney等平台上看到的,要实现这种一致性往往需要利用种子、上传图像,甚至借助流行文化中知名人物的形象。然而,Sora毫不费力地超越了这些方法,给现有工具投下了长长的阴影,并有可能重塑设计人员的格局。这反映了这样一种观点:未来设计领域的分歧可能确实存在于那些精通像Sora这样的人工智能技术的人和尚未接受这些技术的人之间,这表明对传统艺术、3D建模和引擎开发角色产生了变革性的影响。文章来源地址https://www.toymoban.com/news/detail-843907.html
到了这里,关于【译】OpenAI 的 Sora 如何通过涌现能力反噬物理世界的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!