用于点击率预测的深度行为路径匹配网络
摘要
用户在电子商务应用程序上的行为不仅包含对商品的各种反馈,有时还隐含着用户决策的认知线索。为了解用户决策背后的心理过程,我们提出了行为路径,并建议将用户当前行为路径与历史行为路径相匹配,以预测用户在应用程序上的行为。此外,我们还设计了用于行为路径匹配的深度神经网络,并解决了行为路径建模中的三个难题:稀疏性、噪声干扰和行为路径的精确匹配。特别是,我们利用对比学习来增强用户行为路径,提供行为路径自激活来减轻噪声影响,并采用两级匹配机制来识别最合适的候选路径。我们的模型在两个真实世界的数据集上表现出色,优于最先进的点击率模型。此外,我们的模型已部署在美团外卖平台上,累计提高了 1.6% 的点击率和 1.8% 的广告收入。
引言
美团外卖 APP 是一款餐饮零售类应用。通过该软件,用户可以浏览和选择 POI(兴趣点,如餐馆、食品店和咖啡馆),并下单购买食物,这些食物将快速送到用户手中。该应用有望了解用户决策背后的心理,并向用户推送相关候选项,从而提高点击率(CTR),进一步增加交易量和广告收入。
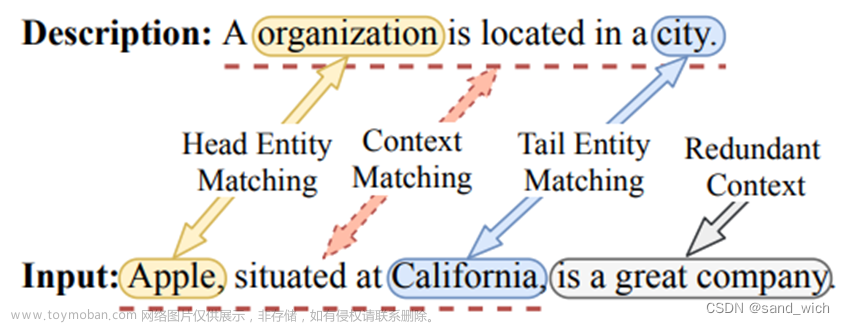
我们注意到,用户在应用程序上的行为是用户决策心理的重要体现。然而现有的一些点击率预测模型虽然对用户行为进行了分析,但都是从长序列或多种行为的角度出发,对历史行为序列中的候选行为和单个行为采用点对点的激活方式,没有考虑到包含用户决策轨迹的连续行为的影响。因此,对于点击目标 POI 这一行为,我们将用户在此之前的连续行为(包括浏览 POI、下单等)视为一条行为路径。通过观察美团外卖 APP 的历史数据,我们发现行为路径与点击行为之间存在密切的相关性。
上述观察结果促使我们开发出一种可进行行为路径匹配以预测用户下一次点击的模型。其核心思想是从用户行为路径中学习与决策心理相关的潜在因素,从而生成其嵌入。有了行为路径的嵌入,模型就会在历史行为路径和当前行为路径之间进行匹配,并估算候选行为的点击率。
然而,用户行为路径建模具有挑战性,因为存在三个困难:行为路径的稀疏性、行为路径中的噪声干扰以及行为路径之间的精确匹配。首先,对于单个用户来说,用户与应用程序之间的交互并不多,这就导致难以捕捉用户的所有行为模式。为了解决行为路径稀少的问题,我们利用对比学习来增强用户行为路径的正向性,优化用户行为路径的学习。其次,用户行为路径中存在大量噪声。例如,用户因某个 POI 的封面吸引而点击该 POI,但一旦用户觉得不喜欢该 POI,就会立即返回。这种行为实际上成了路径中的噪音。为了减少噪音的影响,我们建立了一个动态激活网络,重点关注路径中的几个主要行为。与平等对待路径中的所有行为相比,动态激活更加有效和高效,因为某些行为确实会对后续行为产生更明显的影响。 最后,我们提出了一种两级匹配机制。在第一层,对于当前路径,我们计算每个历史行为路径的激活权重,然后选择前 k 个最相似的历史路径。在第二层,给定候选路径和已选路径后,我们计算跟随已选路径的点击行为的激活权重,以预测点击率。
主要贡献总结如下:
我们首次将用户行为路径匹配引入工业点击率预测中。我们确定了行为路径建模的挑战,即行为路径的稀疏性、噪声和匹配问题。
我们提出了一种用于预测点击率的深度行为路径匹配网络(DBPMaN),它可以增强行为路径,提供行为路径自激活功能,并执行两级匹配(先是行为路径级,然后是点击行为级)来预测点击率。
我们在两个不同规模的真实数据集上进行了离线实验,并在美团广告中进行了在线 A/B 测试。实验结果表明 DBPMaN 是有效的,并达到了最先进的性能。
相关工作
点击率预测作为推荐系统的核心部分,一直是业界和学术界关注的热点话题[18]。
CTR 预测的经典解决方案是学习特征交互,其中 DeepFM [6]、xDeepFM [9] 和 ONN [17] 是早期具有代表性的深度神经网络模型,而 CAN [1] 则是目前开源 CTR 模型中性能最先进的。
最近,连续行为建模成为点击率预测的新动力。建模行为的粒度范围从单一行为(如 DIN [21])到多种行为(如 FeedRec [15]),从短序列(如 DIEN [20]、DSIN [5])到超长序列(如 MIMN [11]、SIM [12]、ETA [2])。这些模型旨在捕捉用户兴趣[5,19-21]或意图[8],通常采用点对点激活法,其输入只包含点击等单一行为,从概率角度估计用户对候选对象的兴趣/意图倾向。事实证明,它们不断提高了 CTR 预测的准确性。此外,随着 Transformer [14] 和 BERT [4] 在 NLP 领域的巨大成功,它们也被引入到推荐系统中,以实现不同的召回任务 [7, 13] 或 CTR 预测任务 [3]。
与上述工作相比,我们的工作强调暗示决策标志的行为路径,并采用行为路径作为 CTR 预测的证据基础。
OUR MODEL
概述
首先介绍文章使用到的定义:
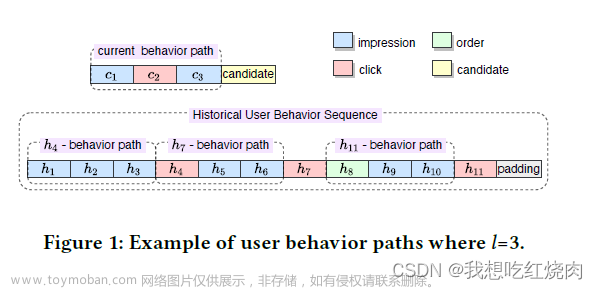
定义一(用户行为序列)使用 定义用户集。对于用户u ∈ 来说,ta的行为序列由ta的行为组成,按照发生时间排序,用 表示,其中bi是第i个行为,T是行为序列的长度。在本文的场景中,该序列包括用户在过去一年的行为(用户行为不足一年怎么办)。每个行为包括互动项目的ID、行为类型、发生时间与当前时间的间隔及在序列中的相应位置等。在这里,有三种行为类型:点击、印象和下单。
定义二(用户点击序列)在用户行为序列s中,存在大量的点击行为。因此我们可以从s中得到一个点击序列 : ,其中 t 为点击序列的长度。
定义三(用户行为路径)对于中第i个点击行为 ,令在行为序列s中对应的行为,m(i)表示第i个点击序列在s中对应的位置。与点击行为 相关的用户行为路径用pi表示,也就是s中的子序列,l表示该行为路径的长度。
从用户行为路径的定义中,我们可以明显地发现点击行为和行为路径是一一对应的。图 1 给出了用户行为路径的一个示例。在历史用户行为序列中,有三条用户行为路径,其长度预设为 3:其中一条在 点击h 4 时发生,一条在 点击h7 时发生,一条在 点击h11 时发生。
定义四(行为路径序列) 对于s中所有点击行为,我们可以获得他们相应的行为路径,构成行为路径序列
其次,我们给出DBPMaN模型的组成、结构和流程。
DBPMaN 由一个嵌入层和三个模块组成,即路径增强模块(PEM)、路径匹配模块(PMM)和路径扩充模块(PAM),其结构如图 2 所示。
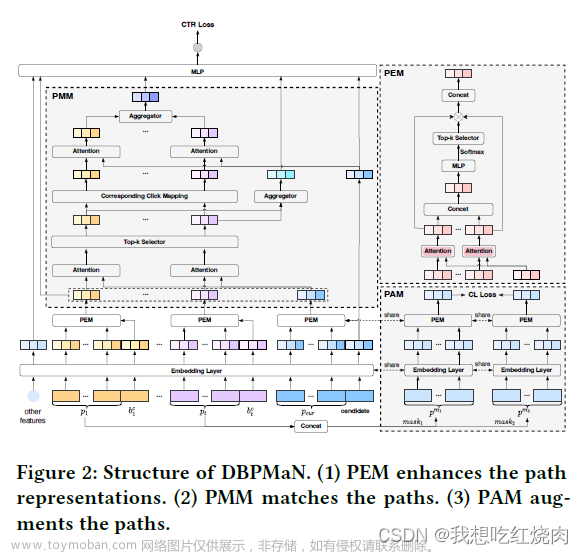
输入:DBPMaN 将多个特征作为输入,所选特征来自:(1) 物品档案,包括物品 ID 及其侧面信息(如类别、位置、评分等);(2) 用户档案,包括用户 ID 及其侧面信息(如年龄、性别、城市等);(3) 用户行为序列中的行为。这些特征被输入到嵌入层。对于所有特征,我们都可以通过查找嵌入表来获得其嵌入度。然后,我们对不同类型的特征进行求和池化处理,计算出用户行为序列 、用户嵌入值 和候选项嵌入值。
PEM:用户行为路径中的行为往往会对相应的下一次点击行为(即用户行为路径之后的点击行为)产生不同的影响。PEM 希望通过挖掘这些信息来学习更准确的路径嵌入。简而言之,给定每个行为路径及其对应点击行为的嵌入,PEM 首先激活行为路径中的重要行为,然后优化行为路径的嵌入,从而获得更准确的行为路径表示。
然后,PMM 使用当前行为路径和历史行为路径的嵌入作为输入,搜索与当前行为路径相比最相似的k个历史行为路径,然后激活候选的相应k个点击行为。
此外,PAM 的目标是通过对比学习,学习更精确、信息量更大的行为路径嵌入。具体来说,我们对每条历史行为路径进行掩码,得到两条增强路径,然后将它们输入嵌入层和 PEM,计算它们的嵌 入,再以 InfoNCE 损失[10]作为对比损失,拉近来自相同行为路径的嵌入度。
Path Enhancing Module (PEM)
对于一条行为路径以及接下来的点击行为嵌入层会生成它们的embeddedings:及
我们首先在用户行为路径上应用局部激活单元,该单元会执行加权串联池化,以自适应地计算行为路径的嵌入,如公式 1 所示。

其中,a(-) 是一个 MLP,其输出被用作第一级激活得分。
然后,我们将 输入另一个 MLP,并通过 softmax 激活函数学习行为路径中每个行为的二级激活得分,如公式 2 所示。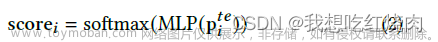
是一个l维向量,其条目代表行为路径中行为的二级激活得分。然后,只选取前 k 个得分。根据所选分数,我们将其与 中相应的行为嵌入相乘。通过连接与分数相乘后的嵌入,可以得到。
这样,我们就可以得到增强路径嵌入的序列 。
Path Matching Module(PMM)
对于一个用户来说,其行为序列中可能存在大量的行为路径。然而,只有少数行为路径与当前行为路径相似,而这些行为路径可以表明用户当前的兴趣所在。PMM 旨在搜索与当前路径最相似的前 k 个行为路径,然后获得相应的 k 个点击行为,这些行为被认为对用户的当前兴趣有相当大的贡献。
具体来说,给定增强的历史路径嵌入序列 和当前行为路径的增强嵌入 ,我们将每个 和 输入一个评分门,得到一个相似度评分 ,它反映了相应历史行为路径的重要性。评分门的计算如公式 3 所示:
其中,⊗ 表示哈达积,MLP(-) 作为前馈神经网络实现。
因此,我们可以得到一个相似性得分列表 。我们对所有得分进行排序,选出前 k 个得分。有了前 k 个得分,我们就可以得到相应的历史路径和与历史路径相对应的点击行为。对于所选的点击行为,这些点击行为嵌入的序列用 表示。此外,我们将每条所选路径的嵌入值乘以相应的分数,得到所选路径的调整嵌入值,如公式 4 所示。
其中,函数Filter (socre, embeding, k)将历史行为路径按得分排序,并选择前 k 个路径。
所有被选中的点击行为都应该对用户当前的兴趣做出不同的贡献。因此,我们采用与公式 3 相同的方法来计算候选点击行为与所选点击行为之间的相似度得分,从而通过考虑它们之间的相关性来自适应地计算用户兴趣的表示向量,如公式 5 所示。
最后,Pe , Ep , Ec , eu和ect被串联起来,然后送入 MLP 层,输出预测的 CTR。
实验
实验设置
数据集
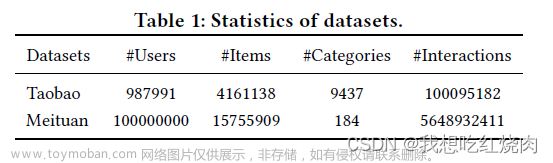
淘宝:公共数据集 [22],包含 10 天的互动。我们预处理数据的方法与 CAN 在 [1] 中的方法相同。
美团:美团外卖应用收集的行业数据集,包含 1 亿用户 14 天的互动。
对比模型
我们选择以下侧重于特征交互建模的点击率模型作为比较模型。
DeepFM [6]。它结合了因式分解机和深度学习,用于低阶和高阶特征交互。
xDeepFM [9]。它利用提出的压缩交互网络(CIN)生成特征交互,并进一步将 CIN 和基本 DNN 结合成一个统一的模型。
DIN [21]。它设计了一个局部激活单元,从候选者的历史行为中学习用户兴趣的表示。
DIEN [20]。它设计了一个兴趣提取层和一个兴趣演化层,从行为序列中捕捉兴趣。
ONN [17]。它针对不同的操作学习不同的表征。
CAN [1]。它通过协同作用单元将表征学习和特征交互建模分离开来。
指标
我们在离线实验中使用 AUC 和 RelaImpr [16] 作为指标,在在线实验中使用 CTR 和 CPM(Cost-Per-Mille)作为指标。
实施细节
我们通过 Tensorflow 实现了 DBPMaN 1。对于所有模型,我们使用学习率为 0.001 的 Adam 作为优化器。模型参数初始化为高斯分布(均值为 0,标准差为 0.01)。项目嵌入维度设置为 18。
性能比较
我们进行了对比实验,将我们的模型与上述竞争对手进行了比较。不同模型在两个数据集上的性能结果如表 2 所示。
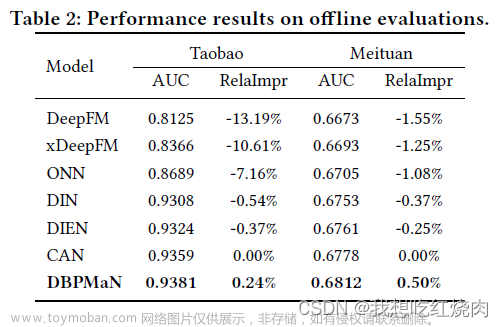
从结果来看,我们发现所有模型在两个数据集上的性能排名是相同的,而我们的 DBPMaN 超越了所有竞争对手。我们认为,DBPMaN 中路径到路径激活的注意力机制有助于打败其他模型,包括基于注意力的模型(即 DIN、DIEN 和 ONN),这些模型在历史行为序列中对候选行为和个体行为采用点到点激活。
一个有趣的发现是,在美团数据集而不是淘宝数据集上,我们的 DBPMaN 模型比其他模型取得了更显著的改进。这可能源于外卖场景的性质。用户周围的食品店相对较少,再加上用户对食品感兴趣的特点,导致用户行为历史中与同一家食品店的重复交互。这样就很容易激活与当前路径相关的历史路径。
消融实验
我们对美团数据集进行了消融研究,以评估 DBPMaN 关键模块的贡献。我们将我们的模型与三个变体(即 DBPMaN w/o PEM、DBPMaN w/o PMM 和 DBPMaN w/o PAM)进行了比较。结果如表 3 所示。
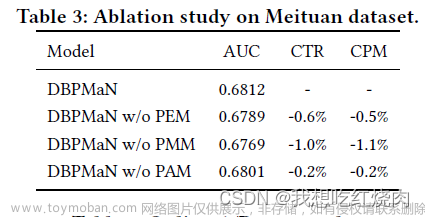
从表 3 中我们可以发现,与原始 DBPMaN 相比,三个变体的三个指标都有所下降。不含 PMM 的 DBPMaN 性能下降幅度最大,这表明 PMM 比其他两个模块发挥了更重要的作用。
在线A/B实验
A/B 测试在美团外卖平台上进行,从 2022-08-10 到 2022-08-23 共 14 天,其中基线模型是我们最后一个在线点击率模型,它只使用了点对点激活方法。结果如表 4 所示,其中,𝑙 表示行为路径的长度。现在,DBPMaN(𝑙=8)已在线部署,并为用户的主要流量提供服务。文章来源:https://www.toymoban.com/news/detail-844046.html
总结
在本文中,我们首次提出了将用户行为路径建模到点击率预测中的 DBPMaN。除了出色的性能,DBPMaN 还展示了通过行为路径建模探索用户决策心理的可能性。文章来源地址https://www.toymoban.com/news/detail-844046.html
到了这里,关于【论文阅读】A Deep Behavior Path Matching Network for Click-ThroughRate Prediction的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[论文阅读]Coordinate Attention for Efficient Mobile Network Design](https://imgs.yssmx.com/Uploads/2024/02/732600-1.png)