本文首发于公众号:Hunter后端
原文链接:Python面试必备一之迭代器、生成器、浅拷贝、深拷贝
这一篇笔记主要介绍 Python 面试过程中常被问到的一些问题,比如:
- Python 中的迭代器和生成器是什么,有什么作用
- Python 中不可变类型有哪些
- 在 Python 函数中,传递参数传递的是什么,值还是引用
- 将一个列表或者字典传入函数,在函数内部对其进行修改,会影响函数外部的该变量吗
- Python 中的深拷贝和浅拷贝是什么,怎么用,区别是什么
针对以上问题,本篇笔记将详细阐述其原理,并用示例来对其进行解释,本篇笔记目录如下:
- 迭代器
- 生成器
- Python 中的可变与不可变类型
- Python 的函数参数传递
- 浅拷贝、深拷贝
1、迭代器
1. 迭代
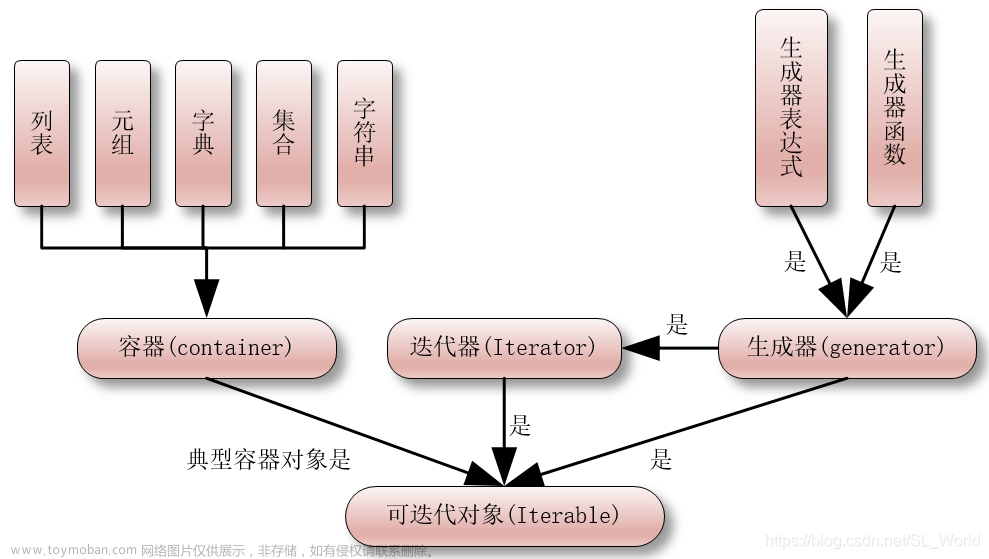
在 Python 中,对于列表(list)、元组(tuple)、集合(set)等对象,我们可以通过 for 循环的方式拿到其中的元素,这个过程就是迭代。
2. 可迭代对象
在 Python 里,所有的数据都是对象,其中,可以实现迭代操作的数据就称其为可迭代对象。
比如前面介绍的列表,元组,集合,字符串,字典都是可迭代对象。
如果要判断一个对象是否是可迭代对象,可以通过与 typing.Iterable 来进行比较:
from typing import Iterable
print(isinstance([1, 2, 3], Iterable)) # True
print(isinstance((1, 2, 3), Iterable)) # True
print(isinstance({1, 2, 3}, Iterable)) # True
print(isinstance({"a": 1, "b": 2}, Iterable)) # True
print(isinstance("asdsad", Iterable)) # True
3. 迭代器
我们可以将一个可迭代对象转换成迭代器,所谓迭代器,就是内部含有 __iter__ 和 __next__ 方法的对象,它可以记住遍历位置,不会像列表那样一次性全部加载。
迭代器有什么好处呢,正如前面所言,因为不用一次性全部加载对象,所以可以节约内存,我们可以通过 next() 方法来逐个访问对象中的元素。
我们可以使用 iter() 方法来将一个可迭代对象转换成迭代器。
1) 创建迭代器
我们可以通过 iter() 函数来将可迭代对象转换成迭代器:
s = [1, 2, 3]
s_2 = iter(s)
2) 判断对象是否是迭代器
迭代器的类型是 typing.Iterator,我们可以通过 isinstance() 函数来进行判断。
注意: 这里进行测试的 Python 版本是 3.11,所以需要从 typing 中加载 Iterator,如果是之前的某个版本,应该从 collections 模块中加载。
from typing import Iterator
isinstance(s, Iterator) # False
isinstance(s_2, Iterator) # True
3) 访问迭代器
我们可以通过 next() 函数来访问迭代器:
s = [1, 2, 3]
s_2 = iter(s)
next(s_2) # 1
next(s_2) # 2
next(s_2) # 3
next(s_2) # raise StopIteration
访问迭代器的时候需要注意下,如果使用 next() 函数访问到对象的末尾还接着访问的话,会引发 StopIteration 的异常。
我们可以通过 try-except 的方式来捕获:
s = [1, 2, 3]
s_2 = iter(s)
while True:
try:
print(next(s_2))
except StopIteration:
print("访问结束")
break
2、生成器
生成器也是一种迭代器,它也可以使用 next() 方法逐个访问生成器中的元素,并且能够实现惰性计算,延迟执行以达到节省内存的目的。
1. 生成器的创建
可以使用两种方式创建生成器,一种是使用小括号 () 操作列表生成式,一种是使用 yield 来修饰。
1) 使用列表生成式创建生成器
x = (i for i in range(10))
print(type(x)) # generator
前面介绍了生成器也是一种迭代器,下面可以进行验证操作:
from typing import Iterator
print(isinstance(x, Iterator)) # True
而生成器本身的类型为 Generator,也可以通过 typing 模块引入:
from typing import Generator
print(isinstance(x, Generator)) # True
2) 使用 yield 字段创建生成器
如果要使用 yield 来创建生成器,则需要将其放置在函数内,以下是一个示例:
def test_yield(n):
for i in range(n):
yield i
x = test_yield(8)
print(type(x)) # <class 'generator'>
print(next(x)) # 0
在这里,yield 相当于 return 一个值,并且记住这个位置,在下次迭代时,代码从 yield 的下一条语句开始执行。
2. 生成器的使用
前面介绍了生成器就是一种迭代器,所以可以使用迭代器的方式来访问生成器,比如 for 循环,next() 方法等。
3. 生成器的应用示例
下面介绍两个运用生成器的实例,一个是用于斐波那契数列,一个是按行读取文件。
1) 斐波那契数列
使用生成器来操作斐波那契数列,其函数操作如下:
def fibonacci(max_number):
n, a, b = 0, 0, 1
while n < max_number:
yield b
a, b = b, a + b
n += 1
for i in fibonacci(6):
print(i)
2) 读取文件
如果有一个大文件,我们也可以使用生成器的方式来逐行读取文件:
def read_file(path):
with open(path, "r", encoding="utf-8") as f:
for line in f:
yield line
path = "path/to/file"
for line in read_file(path):
print(line.strip())
4. 迭代器与生成器的异同
首先,生成器本身就是一个迭代器,所以生成器具有迭代器的所有优点,比如不用一次性加载全部对象,节约内存。
不同点在于两者的创建方式是不一样的,而且使用 yield 构成生成器的应用程度是更广泛的。
3、Python 中的可变与不可变类型
首先,Python 中数据类型的可变与不可变的定义为当我们修改了它的值后它对应的内存地址是否变化。
如果一个数据类型,它的值修更改后,它的内存地址发生了改变,那么我们称其为不可变类型。
相反,如果我们修改某个数据类型的值后,内存地址没有发生变化,那么则称其为可变类型。
我们可以这样理解,对于同一个内存地址而言,如果可以修改变量的值,那么它就是可变类型,否则是不可变类型。
1. 不可变类型
Python 中不可变的数据类型有 int、string、tuple、bool 等,示例如下:
s = 1
print(id(s)) # 140713862796072
s = 2
print(id(s)) # 140713862796104
上面的两次输出可以看到 s 这个变量的内存地址在值修改后就变化了。
2. 可变类型
Python 中可变的数据类型有 list、set、dict,这些数据类型在修改原值后,其内存地址不变,因此属于可变类型。
s = [1,2,3]
print(id(s)) # 2116182318592
s.append(4)
print(id(s)) # 2116182318592
4、Python 的函数参数传递
这里的问题其实是在 Python 中,我们往函数里传参数时,是值传递还是引用传递。
所谓的值传递,就是把参数的值做一个拷贝,把拷贝的值传到函数内。
所谓的引用传递,就是把参数的内存地址直接传到函数内。
那么在 Python 里,函数的传参到底是哪一种呢,我们可以来做个实验:
def test(a):
print(id(a))
a = 1
print(id(a)) # 140713862796072
test(a) # 140713862796072
a = [1, 2, 3]
print(id(a)) # 2116183414208
test(a) # 2116183414208
可以看到,不管是不可变类型还是可变类型,我们传入函数内部的变量的内存地址和外部变量的内存地址都是一样的,因此,在 Python 中,函数的传参都是传递的变量的引用,即变量的内存地址。
可变类型与不可变类型的区别
这里需要注意的一点,对于可变类型和不可变类型,当我们在函数内对其修改后,其是否会影响到外部变量呢,我们还是可以接着做一个测试,这里对于两种类型分别进行测试。
先做不可变类型的测试:
def test_1(a):
print(f"函数内部修改前,a 的地址为: {id(a)}")
a = 2
print(f"函数内部修改后,a 的地址为: {id(a)}")
a = 1
print(f"调用函数前,a 的地址为:{id(a)}")
test_1(a)
print(f"函数外 a 的值是:{a},地址为:{id(a)}")
这里输出的信息如下:
调用函数前,a 的地址为:140713862796072
函数内部修改前,a 的地址为: 140713862796072
函数内部修改后,a 的地址为: 140713862796104
函数外 a 的值是:1,地址为:140713862796072
在这里可以看到,虽然函数传参传入的是变量的引用,即内存地址,但因为它是不可变类型,所以对其修改后,函数内部相当于是对其重新申请了一个内存地址进行操作,但是不会影响函数外部原有的内存地址。
接下来测试一下可变数据类型:
def test_2(l):
print(f"函数内部修改前,l 的地址为: {id(l)}")
l.append(3)
print(f"函数内部修改后,l 的地址为: {id(l)}")
l = [1, 2]
print(f"调用函数前,l 的地址为:{id(l)}")
test_2(l)
print(f"函数外 l 的值是:{l},地址为:{id(l)}")
其输出的信息如下:
调用函数前,l 的地址为:2116196122176
函数内部修改前,l 的地址为: 2116196122176
函数内部修改后,l 的地址为: 2116196122176
函数外 l 的值是:[1, 2, 3],地址为:2116196122176
这里可以看到,函数内外 l 变量的地址都是不变的,但因为是可变类型,所以在函数内部修改了变量的值以后,并没有重新分配内存,所以在函数外部 l 变量同步被影响。
那么在函数内部对传入的可变类型变量进行任何操作都会影响到函数外部吗?
不一定,这里提供一个示例:
def test_3(l):
print(f"修改变量前,l 的地址为:{id(l)}")
l = l + [3]
print(f"修改变量后,l 的地址为:{id(l)}")
l = [1, 2]
print(f"调用函数前,l 的地址为:{id(l)}, 值为:{l}")
test_3(l)
print(f"调用函数后,l 的地址为:{id(l)},值为:{l}")
它的输出的信息如下:
调用函数前,l 的地址为:2116183414208, 值为:[1, 2]
修改变量前,l 的地址为:2116183414208
修改变量后,l 的地址为:2116200373376
调用函数后,l 的地址为:2116183414208,值为:[1, 2]
可以看到,在函数内部,对可变类型进行了操作之后,它的内存地址有所变化,而且修改后不会影响到原始变量。
这是因为在函数内部执行的操作是 l = l + [3],这个操作的本质并不是直接对变量的值进行修改,而是新建一个内存地址,然后对这个变量进行重新赋值,所以这个操作的 l 与函数传入的变量 l 已经不是同一个变量了,因此不会影响到外部的变量。
多说一句,可变类型变量的这个操作其实就跟不可变类型的变量的重新赋值是同一个意义:
a = 1
a = 2
这里其实也是因为对 a 进行了新的内存空间申请,然后重新赋值。
5、浅拷贝、深拷贝
1. 概念
在 Python 中,如果是不可变对象,比如 string,int 等,变量间的拷贝效果都是一致的,都会重新获取一个内存地址,重新赋值,拷贝前后两个变量不再相关。
而如果是可变对象,比如 list,set,dict 等,就需要区分浅拷贝和深拷贝。
浅拷贝的操作过程:为新变量重新分配内存地址,新变量的元素与原始变量的元素地址还是一致的。
但是如果原始变量的元素是不可变类型,那么修改原始变量或新变量的元素之后,不会引起两个变量的同步变化。
如果修改的是变量元素的可变类型,而可变类型进行修改后,其内存地址不会变的,则会引起两个变量的同步变化。
深拷贝的操作过程:为新变量重新分配内存地址,创建一个对象,如果原始变量的元素中有嵌套的可变类型,那么则会递归的将其中的全部元素都拷贝到新变量,拷贝过程结束之后,新变量与原始变量没有任何关联,只是简单的值相等而已。
上面这两个概念可能听起来比较绕,接下来我们用示例来对其进行展示。
2. 浅拷贝
1) 元素为不可变类型
浅拷贝的操作使用 copy 模块,引入和使用如下:
import copy
l1 = [1, 2, 3]
l2 = copy.copy(l1)
这里使用元素为不可变类型的 dict 进行示例展示:
d1 = {"a": 1, "b": 2}
d2 = copy.copy(d1)
print(f"d1 的地址为:{id(d1)}")
print(f"d2 的地址为:{id(d2)}")
print(f"d1 a 的地址为:{id(d1['a'])}")
print(f"d2 a 的地址为:{id(d2['a'])}")
它的信息输出如下:
d1 的地址为:2116196027264
d2 的地址为:2116200318400
d1 a 的地址为:140713862796072
d2 a 的地址为:140713862796072
可以看到,进行浅拷贝后,两个变量的内存地址是不一样的,但是内部的元素的地址都还是一样的。
而如果对其元素的值进行更改,因为元素是不可变类型,所以更改之后其内部元素的地址也会不一样:
d2["a"] = "2"
print(f"d1 的值为:{d1}")
print(f"d2 的值为:{d2}")
print(f"d1 a 元素的地址为:{id(d1['a'])}")
print(f"d2 a 元素的地址为:{id(d2['a'])}")
其输出的内容如下:
d1 的值为:{'a': 1, 'b': 2}
d2 的值为:{'a': '2', 'b': 2}
d1 a 元素的地址为:140713862796072
d2 a 元素的地址为:140713862839480
2) 元素为可变类型
当需要拷贝的可变对象的元素也是可变类型的时候,比如,列表内嵌套了列表或者字典,或者字典内嵌套了列表或者字典,以及集合的相关嵌套,对其进行浅拷贝后,因其嵌套的元素是可变类型的,所以在对内部元素进行修改后,元素的内存地址还是会指向同一个,所以对外展示的影响就是,原始变量和新变量会同步更新数据。
接下来我们以字典内嵌套列表为例进行示例展示:
d1 = {"a": 1, "b": [1, 2]}
d2 = copy.copy(d1)
print(f"d1 的地址为:{id(d1)}, d1 的 b 元素的地址为:{id(d1['b'])}")
print(f"d2 的地址为:{id(d2)}, d2 的 b 元素的地址为:{id(d2['b'])}")
其输出内容如下:
d1 的地址为:2116201415808, d1 的 b 元素的地址为:2116195489024
d2 的地址为:2116183354816, d2 的 b 元素的地址为:2116195489024
这里可以看到 d1 和 d2 的内存地址是不一样的,但是内部的 b 元素的内存地址一致。
接下来我们对 d2 的 b 列表进行修改,再来看一看两者的地址和 d1 以及 d2 的值:
d2["b"].append(3)
print(f"d1 的值为:{d1}, d1 的 b 元素的地址为:{id(d1['b'])}")
print(f"d2 的值为:{d2}, d2 的 b 元素的地址为:{id(d2['b'])}")
其输出内容如下:
d1 的值为:{'a': 1, 'b': [1, 2, 3]}, d1 的 b 元素的地址为:2116195489024
d2 的值为:{'a': 1, 'b': [1, 2, 3]}, d2 的 b 元素的地址为:2116195489024
可以看到,对 d2 修改 b 元素的值后,也同步反映到了 d1 上。
总结: 综上,可以看到,在浅拷贝中,如果元素是不可变对象,那么修改原始变量或新变量后,不会引起两者的同步变化,如果元素是可变对象,那么修改原始变量或者新变量后,则会引起两者的同步变化。
3. 深拷贝
相对于浅拷贝而言,深拷贝的操作要简单许多,不管元素是可变对象还是不可变对象,进行深拷贝后,原始变量和新变量从外到内都是不一样的内存空间,而且修改任意一个都不会引起同步变化。
代码示例如下:
import copy
d1 = {"a": 1, "b": [1, 2]}
d2 = copy.deepcopy(d1)
d2["b"].append(3)
print(f"d1 的值为:{d1},d1 的 b 元素地址为:{id(d1['b'])}")
print(f"d2 的值为:{d2},d2 的 b 元素地址为:{id(d2['b'])}")
其输出内容如下:
d1 的值为:{'a': 1, 'b': [1, 2]},d1 的 b 元素地址为:2116199853248
d2 的值为:{'a': 1, 'b': [1, 2, 3]},d2 的 b 元素地址为:2116199512896
根据输出可以看到,它的内容是符合我们前面对其的解释的。
4. 总结
一般来说,如果没有特殊需求,不需要原始变量与新变量之间有所关联的话,建议使用深拷贝,因为浅拷贝的内部元素的关联性,在实际编程中很容易造成数据混乱。
以上就是本次 Python 面试知识的全部内容,下一篇将介绍 Python 中的 lambda 表达式、函数传参 args 和 kwargs 以及垃圾回收机制等。文章来源:https://www.toymoban.com/news/detail-844151.html
如果想获取更多后端相关文章,可扫码关注阅读: 文章来源地址https://www.toymoban.com/news/detail-844151.html
文章来源地址https://www.toymoban.com/news/detail-844151.html
到了这里,关于Python面试必备一之迭代器、生成器、浅拷贝、深拷贝的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!