目录
Git 初识
Git 安装(Linux-ubuntu)
Git 基本操作
创建 Git 本地仓库
配置 Git
认识工作区、暂存区、版本库
添加文件
查看 .git 文件
修改文件
版本回退
撤销修改
情况一:对于工作区的代码,还没有 add
情况二:已经 add ,但没有 commit
情况三:已经 add ,并且也 commit 了
删除文件
分支管理
理解分支
创建分支
切换分支
合并分支
删除分支
合并冲突
分支管理策略
分支策略
bug 分支
删除临时分支
通过学习 Git ,我希望我们能够达成以下目标:
• 技术目标: 深入掌握Git在企业级应用中的运用,包括对Git操作流程和原理的深刻理解,以及对工作区、暂存区和版本库的含义的准确把握。
• 技术目标: 掌握Git版本管理的各种操作方式及其背后的操作原理,包括但不限于版本回退、撤销、修改等操作,以实现对代码版本的灵活管理。
• 技术目标: 从分支的创建、切换、合并到删除等整个生命周期的掌握,能够灵活应对各种场景下的分支管理,并学习常见的分支管理策略。
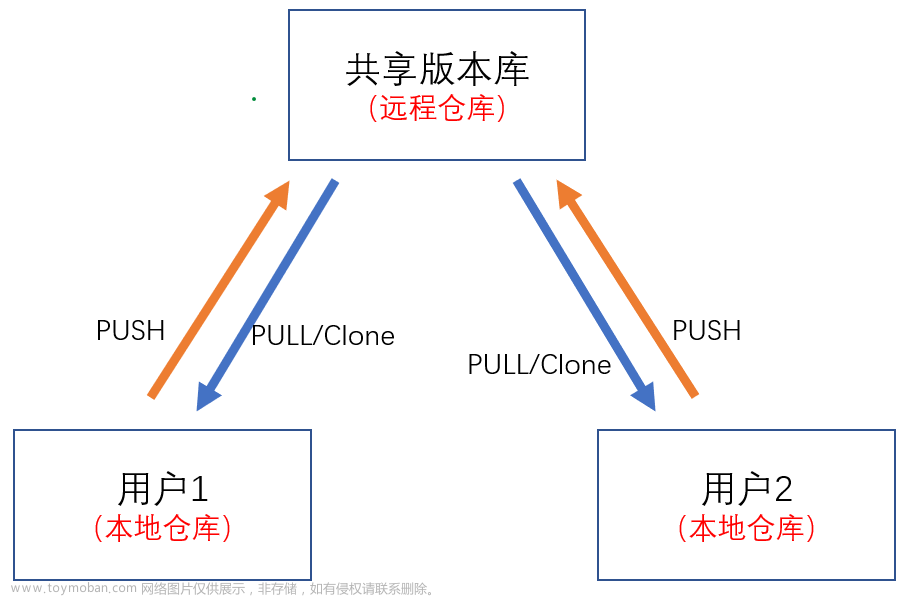
• 技术目标: 结合版本管理与分支管理,熟练掌握Git远程仓库与本地仓库的交互操作,实现基于分支级别的个人级开发。
• 技术目标: 理解分布式版本控制系统的原理,学习多人协作开发模式,掌握远程仓库与本地仓库之间的协同操作。
• 协作目标: 学习企业级常见的分支策略,如master/release/develop/feature/hotfix等,理解不同公司、不同环境下适用的分支模型。通过案例引入工程师、测试人员、技术经理等不同角色,展示项目开发过程的整体流程,从而深入理解Git在其中的作用。
Git 初识
在工作或学习过程中,经常会遇到需要对文档或项目代码进行版本管理的情况。这种情况下,我们会发现随着版本的不断迭代,手动管理多个版本的文档或代码变得非常混乱和困难。
通常情况下,我们会为了保留文档或代码的不同版本而不得不创建多个副本,每个副本都带有不同的版本号或描述,比如“报告-v1”、“报告-v2”等。这种做法可能会导致以下问题:
-
版本混乱和记忆困难: 随着版本的增多,很容易忘记每个版本所做的修改或者特定版本的内容。这使得在需要时很难回溯到特定版本或者了解每个版本的变化。
-
副本过多导致管理困难: 随着版本的不断增加,每个版本都会产生一个副本,这会导致文件系统中出现大量的副本文件,增加了管理的复杂性。同时,找到特定版本的文件也变得更加困难。
-
工作效率低下: 每次创建新版本或者回滚到之前的版本都需要手动复制、重命名或者移动文件,这样的操作会消耗大量的时间和精力,降低了工作效率。
-
无法有效协作: 如果多人共同编辑同一份文档或同一个项目,手动管理多个版本的文件会带来沟通不畅、协作困难等问题,容易导致冲突和误解。
因此,了解和掌握Git这样的版本控制工具变得至关重要。Git可以帮助我们有效地管理文档和代码的版本,轻松地回溯到特定版本,跟踪修改历史,协作开发,提高工作效率,并减少由手动管理版本所带来的错误和混乱。
什么是版本控制工具?我们来详细了解一下。
如何解决——版本控制器
正如先前所提到的,通常情况下,我们可能会遇到需要维护多个版本的文档或代码,以便于回溯修改、找回之前的版本或者与团队成员共享不同的进度。在没有版本控制工具的情况下,我们可能会通过复制粘贴副本的方式来管理不同版本,但随着版本数量的增加,会导致文件混乱、难以追踪每个版本的修改内容等问题。
为了解决这些问题,版本控制器应运而生。版本控制器能够记录文件的历史修改记录,展示其发展过程,为我们提供了一种系统化的管理方式。
简单来说,版本控制器就是能够记录每次工程改动和版本迭代的管理系统,同时也能方便多人协同作业。
具体来说,版本控制器可以看作是一种软件工具,旨在帮助开发团队有效地管理和协调其项目中的源代码和其他文件。其核心功能包括记录文件的历史修改记录、管理文件的不同版本、协调团队成员之间的合作以及管理项目的整体进展。
-
历史修改记录的记录和管理:版本控制器能够记录每次文件的修改,包括修改内容、修改时间、修改人等信息。这样可以轻松地追溯文件的演变历程,了解每个版本的变动细节。
-
版本的管理:版本控制器能够存储文件的不同版本,并支持方便快捷地切换和回溯到特定的版本。这样,开发团队可以在需要时方便地恢复到之前的版本,或者比较不同版本之间的差异。
-
多人协同作业:版本控制器为多人协同作业提供了便利。团队成员可以同时编辑同一个文件,版本控制器会自动合并他们的修改,并提供解决冲突的机制。这样可以避免因为多人同时编辑而产生的冲突和混乱。
-
分支管理:版本控制器支持分支管理,允许开发团队在不同的开发任务或功能之间创建独立的分支。每个分支都可以独立进行开发和测试,然后再合并回主分支。这样可以有效地组织项目的开发流程,提高开发效率。
-
远程仓库管理:许多版本控制器还提供了远程仓库的功能,允许团队将项目代码托管到云端服务器上。这样团队成员可以随时随地访问和共享项目代码,实现分布式团队的协作。
由此可见,版本控制器是一种强大的工具,为软件开发团队提供了有效的项目管理和协作平台。通过记录文件的修改历史、管理不同版本、支持多人协同作业和分支管理等功能,版本控制器可以帮助团队提高工作效率、降低开发成本,并保证项目的质量和稳定性。
而目前最主流的版本控制器是Git。Git具有管理电脑上所有格式的文件的能力,包括doc、excel、dwg、dgn、rvt等等。对于开发人员来说,Git最重要的功能之一就是能够帮助我们有效地管理软件开发项目中的源代码文件,使得团队成员能够协同工作,并且能够方便地追踪、回溯和管理代码的变更历史。
注意事项
需要明确的一点是,所有的版本控制系统,包括Git在内,实际上只能跟踪文本文件的改动,比如TXT文档、网页、以及所有的程序代码等等。版本控制系统能够告诉你每次的改动,比如在第5行添加了一个单词“Linux”,在第8行删除了一个单词“Windows”等等。
对于图像、视频等二进制文件,虽然它们也可以由版本控制系统管理,但版本控制系统无法跟踪文件的具体变化,它只能记录二进制文件每次改动的大小变化,比如从100KB变成了120KB,但无法知道具体修改了什么内容。因此,对于这些二进制文件,版本控制系统只能将它们的改动串联起来,而无法具体展示每次改动的细节。
Git 安装(Linux-ubuntu)
Git是一款开放源代码的分布式版本控制系统,最初是由Linus Torvalds为了管理Linux内核开发而开发的。起初,Git主要用于Linux平台,并且在Linux下得到了广泛的应用。随着时间的推移,Git逐渐被移植到了其他操作系统平台,如Windows、Unix和Mac OS等,现在已经可以在这几大平台上正常运行。
这种跨平台的特性使得Git成为了一款广泛使用的版本控制工具,无论是在开源项目中还是在商业项目中,都得到了广泛的应用。无论开发者使用的是哪种操作系统,他们都可以通过Git来管理和追踪项目的代码,实现代码的版本控制和团队协作。这也使得Git成为了现代软件开发中不可或缺的重要工具之一。
在 Ubuntu 平台上安装 Git 是非常简单的。以下是安装 Git 的步骤:
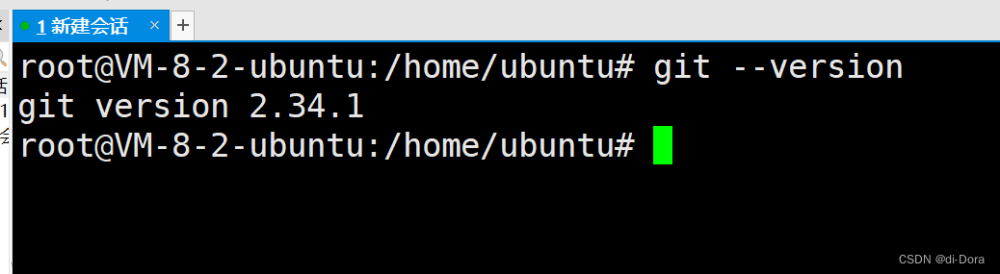
首先,我们可以尝试在终端输入 git 命令,看看系统是否已经安装了 Git。
如果系统没有安装 Git,会得到类似如下的提示:

此时这表示 Git 尚未安装。
通过以下命令安装 Git:

这条命令将使用 apt-get 包管理器来安装 Git。加上 -y 参数表示自动确认安装,无需手动确认安装过程中的提示信息。
安装完成后,我们可以通过以下命令来验证 Git 是否成功安装以及查看 Git 的版本信息:

这将显示已安装的 Git 版本号,确认安装成功。
通过上述步骤,我们就可以在 Ubuntu 上成功安装 Git,并开始使用它进行版本控制和开发工作。
Git 基本操作
创建 Git 本地仓库
仓库是进行版本控制的一个文件目录或者存储空间。
在Git中,仓库是用来存储项目的所有文件和历史变更记录的地方。我们要对文件进行版本控制,首先需要在本地或者远程创建一个仓库。
在Git中,我们可以通过以下两种方式创建仓库:
1、本地仓库:在本地计算机上创建一个Git仓库,用于存储本地项目的文件和版本记录。这种方式适用于个人项目或者本地开发。
若要在当前目录下创建一个新的Git仓库,可以使用以下命令:
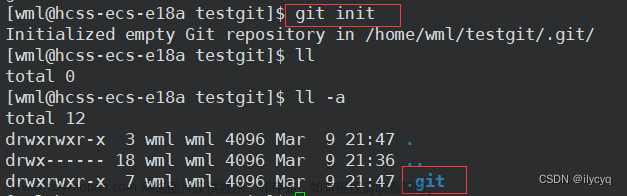
git init这将在当前目录下创建一个名为 .git 的隐藏文件夹,作为Git仓库,用来存储项目的版本历史和元数据。
2、远程仓库:在远程服务器上创建一个Git仓库,用于存储项目的文件和版本记录,并允许多个开发者之间共享和协作。这种方式适用于团队项目或者需要跨多个开发者协作的项目。
若要在远程服务器上创建一个新的Git仓库,可以使用Git托管服务(如GitHub、GitLab、Bitbucket等)提供的界面或者命令行工具。在网站上创建好仓库后,可以通过以下命令将本地仓库关联到远程仓库:
git remote add origin <远程仓库地址>这将在本地仓库中添加一个名为 origin 的远程仓库地址。
其中第二种远程操作我们后续会系统的学习,现在先不做过多了解。
我们此处就使用第一种方式来创建一个本地仓库:

上面我们已经使用 git init 命令初始化了一个空的Git仓库。在这个命令执行后,系统提示我正在使用 master 作为初始分支的名称,并给出了一些关于默认分支名更改的提示信息。同时,Git成功地在 /home/ubuntu/gitcode/.git/ 目录下初始化了一个空的Git仓库,该仓库将用于存储项目的版本历史和元数据。

你可以清楚地看到在当前目录下多了一个 .git 的隐藏文件, .git 目录是Git用来跟踪和管理仓库的关键组成部分,它包含了Git仓库的所有版本历史和元数据信息。在这个目录下存储了Git的配置、历史记录、分支信息等内容,对其进行手动修改可能会导致Git仓库损坏。
因此,在使用Git的过程中,我们千万不要手动修改 .git 目录下的任何文件,以免意外破坏了Git仓库的完整性。一般情况下,我们只需要通过Git提供的命令来管理和操作仓库,如添加文件、提交修改、切换分支等,Git会自动更新 .git 目录下的相关文件以反映这些操作的变化。
既然这个文件包含了 Git 仓库的诸多细节,那么我们就进去看看:


- branches:该目录用于存储分支的相关信息。
- config:Git 仓库的配置文件,包含了仓库的各种配置信息。
- description:该文件包含了对仓库的描述信息。
- HEAD:指向当前工作分支的指针。
- hooks:该目录包含了一系列 Git 钩子脚本,这些脚本可以在特定的 Git 操作触发时执行相应的动作。
- info:该目录包含了一些仓库的额外信息,如排除文件等。
- objects:该目录用于存储 Git 对象,包括文件内容、目录结构、提交信息等。
- refs:该目录包含了分支和标签的引用。
这些文件和目录构成了Git仓库的基本结构,每个部分都有其特定的作用和功能,用于存储仓库的各种信息和元数据。通过这些文件和目录,Git能够管理和跟踪项目的版本历史、分支、标签等内容,实现有效的版本控制和管理。
创建好仓库后,我们就可以开始向仓库中添加文件、提交修改、查看历史记录等操作,实现对文件的版本控制和管理了。
配置 Git
当安装 Git 后首先要做的事情是设置我们的 用户名称 和 e-mail 地址,这是非常重要的。
设置用户名称和电子邮件地址是安装Git后的重要步骤之一。这些信息将与每次提交的代码一起记录在Git的提交历史中,帮助其他开发者和团队成员识别谁提交了特定的更改,以及如何联系到该开发者。
要设置用户名称和电子邮件地址,可以使用以下Git命令:
设置用户名称:
git config [--global] user.name "Your Name"设置电子邮件地址:
git config [--global] user.email "your.email@example.com"

你也可以使用
git config --unset user.name
git config --unset user.email命令删除相关配置项。
细心的话你会发现,我们上面的代码样例里面给出了[--global]。
当设置用户名称和电子邮件地址时,[--global] 是一个可选项,它影响了配置的作用范围:
-
--global选项的作用:
- 当使用 git config --global 命令来设置用户名称和电子邮件地址时,加上 --global 选项,表示这个设置将应用到当前用户的所有Git仓库中。
- 这意味着不论我们在哪个Git仓库中执行提交操作,都会使用相同的用户名称和电子邮件地址。这是因为这些配置信息保存在用户主目录下的一个特殊文件中(通常是 ~/.gitconfig),被所有的Git仓库共享。
-
不使用--global选项的情况:
- 如果在设置用户名称和电子邮件地址时不使用 --global 选项,则这个设置仅适用于当前所在的Git仓库。
- 这意味着这些配置信息只会应用于当前的Git仓库,而不会影响其他仓库或者全局的设置。这些设置将保存在当前仓库的 .git/config 文件中,只对当前仓库生效。
-
在不同仓库中使用不同的配置:
- 如果我们希望在不同的Git仓库中使用不同的用户名称和电子邮件地址,可以选择不使用 --global 选项,而是在每个仓库中单独设置。
- 要注意的是,如果我们在使用 --global 选项时设置了全局的用户名称和电子邮件地址,然后在某个仓库中又单独设置了不同的值,那么在该仓库中将会使用该仓库的设置而不是全局设置。
综上所述,使用 --global 选项可以方便地将用户名称和电子邮件地址配置应用到所有的Git仓库中,而不使用该选项则可以在不同的仓库中使用不同的配置。但无论使用哪种方式,都需要在仓库内使用 git config 命令来进行设置。

至于使用了 --global 设置的配置项怎么删除?
同样添加 --global 即可:
git config --global --unset user.name
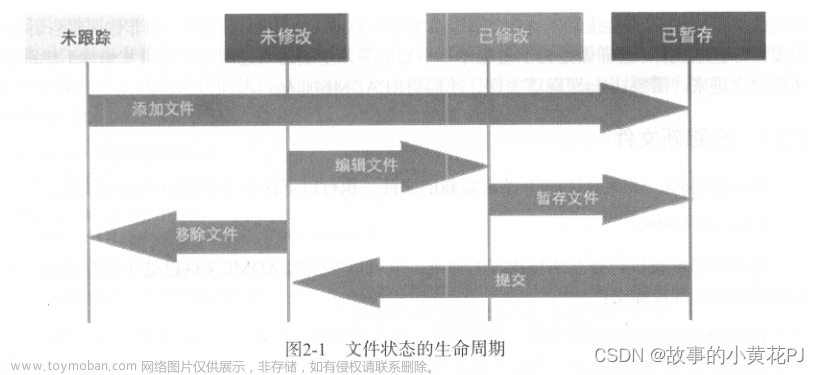
git config --global --unset user.email认识工作区、暂存区、版本库
-
工作区:
- 工作区是指我们电脑上用于编写代码或文件的目录。在这个目录下,我们可以创建、编辑和修改文件,进行开发工作。
- 通常情况下,我们的项目文件都会存放在工作区中,这些文件是我们正在进行开发和编辑的。
-
暂存区:
- 暂存区(英文称为 stage 或 index)是Git的一个重要概念,它是一个缓存区域,用于暂时存放我们已经修改的文件,但是还没有提交到版本库中。
- 暂存区一般存放在 .git 目录下的 index 文件(.git/index)中,因此有时也被称为索引(index)。
- 当我们对工作区中的文件进行修改后,可以通过 git add 命令将这些修改添加到暂存区中,然后通过 git commit 命令将暂存区中的修改提交到版本库中。
-
版本库:
- 版本库(又名仓库,英文名 repository)是Git的核心部分,它包含了我们项目的所有文件和相应的版本历史记录。
- 在我们的工作区中有一个隐藏目录 .git,这个目录就是Git的版本库。这个版本库中包含了我们项目的所有版本信息和元数据。
- Git会跟踪并记录版本库中所有文件的修改、删除等操作,因此我们可以随时追踪项目的历史,或者在需要的时候回溯到之前的某个状态。
- 版本库中的文件经过Git管理,我们可以使用各种Git命令来查看文件的历史记录、比较不同版本之间的差异、撤销修改等操作,以实现对项目的版本控制和管理。
总之,工作区是我们实际进行开发的地方,暂存区是用来暂存即将提交到版本库中的修改,版本库是Git用来存储项目的所有版本历史和元数据的地方。这三者共同构成了Git的基本工作流程,帮助我们有效地管理项目文件的版本和修改。
下面这个图展示了工作区、暂存区和版本库之间的关系:

在Git中,我们的工作区和版本库扮演着关键的角色。工作区代表了我们当前正在操作的目录,其中包含我们正在开发的代码文件或其他项目文件。在图中,我们可以看到左侧表示工作区,即我们实际进行编辑和修改的地方。而右侧则代表版本库,是Git用来存储项目的所有版本历史和元数据的地方。版本库中包含了我们项目的所有文件以及每个文件的历史版本信息。
通过上图,我们可以总结出Git中文件的管理流程:
- 创建Git版本库:当我们使用Git创建一个新的版本库时,Git会自动为我们创建一个默认的主要分支,通常称为 master 分支。同时,Git还会创建一个指向当前分支的指针,称为 HEAD。这两个概念是Git中非常重要的,它们帮助我们确定当前所在的分支或提交状态。
- 对工作区的文件进行修改或新增:当我们在工作区修改、删除或新增文件时,这些文件处于未跟踪状态,Git并不会自动将它们添加到版本库中。为了将这些修改、删除或新增的文件纳入Git的管理范围,我们需要使用 git add 命令。这个命令将工作区中的修改添加到Git的暂存区中,并更新暂存区目录树的文件索引。
-
执行提交操作:当我们确认要提交暂存区中的修改时,我们使用 git commit 命令。这个命令会将暂存区中的内容提交到版本库中,成为一个新的版本历史记录。这意味着暂存区中的修改会被真正写入到版本库中,从而成为项目的一部分。
在提交操作完成后,master 分支会相应地更新,指向新的提交,以反映项目的最新状态。这个过程中,我们的项目的发展历程得到了保留和记录,使得我们能够随时回溯项目的历史变化。
Git的文件管理流程包括将工作区中的修改添加到暂存区,然后将暂存区中的内容提交到版本库中。这个过程中,Git的分支和HEAD指针起到了重要的作用,帮助我们确定当前所在的分支和提交状态,并实现对项目的导航和操作。
根据上述描述,我们可以得知:仅仅通过新建或粘贴进工作区的文件,并不能称之为向仓库中新增文件,而只是在工作区新增了文件。要将文件添加到仓库中进行管理,必须通过使用 git add 和 git commit 命令来完成!
这个过程确保了我们对项目文件的修改是有意识的,并且能够明确地将这些修改记录到版本库中,以便日后追溯和管理。因此,Git的版本控制机制使得我们能够更加有效地管理项目的代码和文件。
但是我们还是有一些没搞明白的地方:git add 命令到底做了什么?git add 命令呢?版本库的版本控制具体又是怎么做到的呢?
当我们使用 git add 命令时,实际上发生了一系列的操作,主要是将工作区的修改内容添加到Git的暂存区中。具体来说,git add 命令执行以下几个步骤:
-
检查工作区的文件变化:首先,Git会检查工作区中的文件,比较当前文件和上一次提交时的版本之间的差异,以确定哪些文件发生了修改或新增。
-
创建新的Git对象:当检测到文件的修改或新增时,Git会为每个被修改的文件创建一个新的Git对象。这个对象包含了文件的内容以及相关的元数据,如文件名、修改时间等。
-
将对象写入对象库:这些新创建的Git对象会被写入到Git的对象库中,即.git/objects目录下。对象库是Git中用来存储所有版本历史和文件内容的地方。每个Git对象都有一个唯一的SHA-1哈希值,用于标识该对象。这个哈希值是根据对象的内容计算得到的,因此即使是内容微小的改动也会生成一个完全不同的哈希值。
-
更新暂存区的索引:同时,git add 命令也会更新暂存区的索引,以便记录哪些文件被修改了,以及它们的最新哈希值。暂存区实际上存储了文件内容的哈希值和路径信息,用于跟踪文件的修改状态。
通过以上步骤,git add 命令将工作区中的修改内容转化为Git对象,并将这些对象添加到暂存区中,以便后续提交到版本库中。
至于版本库的版本控制,实际上是通过维护对象库来实现的。
版本库的版本控制原理:
- Git的版本控制实际上是通过对象库来实现的。对象库中的每一个对象代表着项目的一个文件或目录的状态。在Git中,有四种类型的对象:blob对象(文件内容)、tree对象(目录结构)、commit对象(提交信息)和tag对象(标签)。
- 当我们对工作区的文件进行修改并执行 git add 命令后,Git会将修改的文件内容写入到对象库中,并生成一个新的blob对象。同时,Git会更新暂存区的索引,将文件名和新生成的blob对象关联起来。
- 当我们执行 git commit 命令时,Git会根据暂存区的索引创建一个新的commit对象,其中包含了提交的作者、提交时间、提交信息等元数据,并指向暂存区的目录结构。这个目录结构实际上是一个tree对象,它记录了当前提交时项目文件的状态。
- 最后,Git会将新生成的commit对象加入到版本库的分支中,例如master分支,同时更新分支指针,使其指向最新的提交,以反映项目的最新状态。
总的来说,Git的版本控制是通过对象库中的对象来实现的,每个对象代表了项目的一个状态或操作记录。通过不同类型的对象,Git能够跟踪和管理项目的所有历史记录,并提供强大的版本控制功能。同时,暂存区则是起到了一个中间状态的作用,帮助我们管理和提交工作区的修改。
另外,回顾我们打印出来的目录树,HEAD、objects,都存放在.git/目录树下。暂存区其实也在,它放在index中,没被打印出来是因为我们之前还没有进行任何add操作。

- HEAD:HEAD 是一个指向当前分支的符号引用(Symbolic Reference),它实际上是一个指向目前所在分支的引用。在Git中,HEAD 始终指向当前所在的分支,或者在提交前指向即将提交的分支。通过 HEAD,Git 知道当前所在的分支,便于我们进行代码的提交、分支切换等操作。
- objects:objects 目录是Git对象库,它存储了Git中的所有对象,包括提交对象(commit)、树对象(tree)、标签对象(tag)以及文件内容对象(blob)。在Git中,一切皆为对象,每个对象都有自己的唯一哈希值来标识。这个目录中的对象组织形式复杂,通常我们无需直接操作它,而是通过Git命令来管理和访问对象。
- index:index 是暂存区的索引,它记录了即将提交到版本库的文件状态信息,包括文件的修改状态、路径信息以及文件的哈希值等。暂存区实际上是一个二进制文件,位于 .git 目录下的 index 文件中。在进行 git add 操作后,工作区的修改会被添加到暂存区中,暂存区的内容会在之后的提交操作中被写入版本库。
这些目录和文件的存在使得Git能够有效地进行版本控制和文件管理。通过将文件的修改和提交状态记录在这些文件中,Git可以跟踪文件的变化、管理版本历史,并支持多人协作开发。虽然这些目录和文件在平时的使用中不太直观,但它们是Git的核心组成部分,为Git的功能提供了基础支持。
添加文件
在包含 .git 的目录下新建一个 ReadMe 文件后(touch Readme),我们可以使用 git add 命令将文件添加到暂存区,以准备进行提交到本地仓库。下面是几种常见的 git add 命令用法:
-
添加一个或多个文件到暂存区:
git add [file1] [file2] ...这条命令将指定的一个或多个文件添加到暂存区,以便之后提交到版本库。
-
添加指定目录到暂存区,包括子目录:
git add [dir]这条命令将指定目录及其子目录下的所有文件添加到暂存区。
-
添加当前目录下的所有文件改动到暂存区:
git add .这条命令将当前目录下的所有文件改动(包括新增、修改和删除)都添加到暂存区。
添加到暂存区后,我们可以使用 git commit 命令将暂存区的内容提交到本地仓库中。常见的 git commit 命令用法包括:
-
提交暂存区全部内容到本地仓库中,并添加提交描述信息:
git commit -m "message"这条命令将暂存区中的所有修改内容提交到本地仓库,并附带一个提交描述信息,用于记录本次提交的目的和细节。
-
提交暂存区的指定文件到仓库区,并添加提交描述信息:
git commit [file1] [file2] ... -m "message"这条命令将暂存区中指定的文件提交到本地仓库中,并附带一个提交描述信息。
需要注意的是,在使用 git commit 命令时,后面的 -m 选项必须跟上本次提交的描述信息,这部分内容绝对不能省略。提交描述信息是用来记录我们的提交细节,对于其他团队成员或自己日后查看版本历史十分重要。因此,描述信息要清晰明了,准确地描述本次提交所做的修改或新增。

当成功执行 git commit 命令后,Git 会提供一些反馈信息,通常会告诉我们有几个文件被修改以及修改了多少行内容。例如,它可能会显示:“1 file changed”(1个文件被改动),“2 insertions”(插入了两行内容),这意味着我们新添加的 ReadMe 文件被成功提交到了本地仓库,并且其中的内容变动已经被记录下来。
在Git中,我们可以多次使用 git add 命令来添加不同的文件到暂存区,但只需执行一次 git commit 命令就可以将暂存区中所有的修改一次性提交到本地仓库。这是因为在我们执行 git add 命令时,需要提交的文件都被添加到了暂存区中,而后续的 git commit 命令会将暂存区的所有修改都一并提交。这种机制使得我们可以更加灵活地管理和提交文件,无需每次修改都进行一次提交操作,同时确保了提交的一致性和完整性。

截止目前为止,我们已经成功将代码提交到了本地仓库。现在,我们可以使用 git log 命令来查看提交的历史记录。该命令会显示从最近到最远的提交日志,并且可以看到每次提交时的日志消息。

如果觉得输出的信息太多,导致眼花缭乱,可以尝试添加 --pretty=oneline 参数,这样输出的每条提交记录就会以一行的形式显示,更加简洁清晰。

需要说明的是,我们在 git log 中看到的一大串类似 23807c5...56eed6 的是每次提交的 commit id(版本号)。Git 的 commit id 不是简单的递增数字,而是通过 SHA1 计算得到的一个非常大的十六进制数字,用于唯一标识每次提交。每个人的 commit id 都是不同的,因此你\大家看到的 commit id 和我看到的肯定是不同的,以你们自己的为准。通过 commit id,我们可以在需要的时候精准地回溯到某次提交,查看具体的修改内容和提交信息。
查看 .git 文件
重开一个窗口,来看看我们新的的 .git 的目录结构(假设我们目前只提交了一个文件Readme):

在执行了 git add 命令之后,目录结构发生了变化。我们可以看到 .git/ 目录下新增了一些文件和目录:
- COMMIT_EDITMSG:这是一个临时文件,用于存放即将提交的修改的编辑消息。
- index:这是暂存区(也称为索引)的文件,它存储了当前暂存区的状态,包含了即将提交的修改的信息。
- logs 目录:包含了提交日志的信息,其中 HEAD 目录下存放了当前分支的提交历史,refs/heads/master 目录下存放了 master 分支的提交历史。
- objects 目录:这是对象库,用于存储 Git 对象。Git 对象是通过 SHA1 计算生成的哈希值来标识的文件和目录,这些对象包含了文件内容、目录结构等信息。
- refs 目录:这是引用目录,存放了 Git 中的引用信息,如分支和标签。在 heads 子目录下存放了分支的引用信息,而在 tags 子目录下存放了标签的引用信息。
这些变化反映了我们执行 git add 命令后的操作:将工作区的修改添加到了暂存区中,并提交到本地仓库。这些文件和目录的生成和变化是 Git 内部进行版本控制所必需的,它们帮助 Git 跟踪、管理和记录我们的项目历史和修改。
我们还需要验证一下HEAD指针究竟指向哪里:

也就是这个部分:

我们再来看一下master里面存放着什么:

你会发现这就是我们最新一次提交的commit的ID:

在对象库里其实也就对应着:

那么我们怎么查看对象里面的具体内容呢?

我们可以得到以下信息:
- tree 行指示了当前提交所对应的树对象的哈希值(commit id)为 d8bf841c208ac376458fe45cac34d82c12c6bcfa。这表明此次提交涉及的所有文件和目录结构都在这个树对象中。
- author 行显示了提交的作者信息,包括作者的名称和电子邮件地址,以及提交时的时间戳。
- committer 行显示了提交的提交者信息,包括提交者的名称和电子邮件地址,以及提交时的时间戳。
- 在这个例子中,提交消息为 "add File1",表示此次提交添加了一个名为 "File1" 的文件。
综合起来,这个输出显示了提交对象的详细信息,包括提交涉及的树对象、作者、提交者以及提交消息等。
我们可以再打开它给出的这个对象看看内容:
我们执行了 git cat-file -p d8bf841c208ac376458fe45cac34d82c12c6bcfa 命令,显示了树对象 d8bf841c208ac376458fe45cac34d82c12c6bcfa 的内容。该树对象包含了一个文件条目,其文件模式为 100644,对象类型为 blob,哈希值为 6972ae3dc63ccc7e528ccfdb9b88b33b023c4da1,文件名为 Readme
我们又通过 git cat-file -p 6972ae3dc63ccc7e528ccfdb9b88b33b023c4da1 命令查看了哈希值为 6972ae3dc63ccc7e528ccfdb9b88b33b023c4da1 的 blob 对象的内容。该对象包含两行文本内容,分别为 "Hey~~~" 和 "Long time no see!!!"。
所以,通过这些命令我们可以查看提交对象、树对象以及 blob 对象的详细信息,以及它们之间的关联。
我们总结一下:
1. Index (暂存区)
- 概念: Index 是 Git 中的一个重要概念,也称为暂存区或者缓存区。它是一个存放在 .git 目录下的文件,用于暂时存放将要提交到版本库的修改。
- 作用: 当我们使用 git add 命令将文件添加到 Index 后,Git 会将这些文件的快照放入暂存区。这意味着这些文件的最新状态已经被记录并准备好被提交。
- 操作方式: 通过 git add 命令可以将工作区的修改添加到 Index 中,使其成为下一次提交的一部分。
2. HEAD
- 概念: HEAD 是 Git 中的一个指针,它指向当前所在的分支(或者某个具体的提交)。通常情况下,它指向默认分支,如 master 分支。
- 默认指向 master 分支的指针: 当我们初始化一个新的 Git 仓库时,master 分支是默认存在的,而 HEAD 则指向这个 master 分支。
- 保存的是当前最新的 commit id: HEAD 指向的位置存储的是当前所在分支的最新提交的 commit id。
3. Objects (对象库)
- 概念: 在 Git 中,objects 是用来存储版本库对象的地方。这些对象包括提交(commit)、树(tree)、标签(tag)等,它们的内容以及文件状态都被存储在 objects 中。
- 存储位置: objects 目录位于 .git 目录下,用来存储各种版本库对象及其内容。
- 对象的创建和更新: 当执行 git add 命令时,会将工作区修改的文件内容写入一个新的对象中,并更新暂存区的目录树。这个新对象会被存储在 objects 目录下。
- 对象查找: Git 使用 SHA-1 哈希算法来给每个对象一个唯一的标识符。当需要查找某个对象时,需要使用对象的哈希值(commit id)。这个哈希值的前两位作为目录名,后38位作为文件名,以此来查找对象文件。
- 查看对象内容: 一般情况下,对象文件是经过 SHA-1 加密的,无法直接查看其内容。但可以使用 git cat-file 命令来查看版本库对象的内容。
在学习的过程中,建议将常见的 Git 操作与 .git 目录中的结构内容变化相联系起来。这样做有助于我们更好地理解 Git 的详细流程。而且,随着我们继续学习,我们将探讨更多关于分支、标签等内容,因此后续的学习将会更加深入和有意义。对这些内容的深入研究将使我们对 Git 的工作原理有更清晰的认识,为我们更高效地使用 Git 提供了重要的基础。
修改文件
在 Git 中,跟踪并管理的是修改而不是文件,这一设计使得 Git 在版本控制系统中具有独特的优势。那么什么是修改呢?修改指的是对文件内容的任何更改,无论是添加、删除、修改、移动还是重命名等操作都被视为一个修改。以下是对修改的一些具体示例:
-
新增一行内容: 在文件中添加一行文字或代码,这被视为一个修改。
-
删除一行内容: 从文件中移除一行文字或代码,这也是一个修改。
-
更改某些字符: 修改文件中的某些字符,比如更改代码中的变量名或修正拼写错误,都属于修改的范畴。
-
删除一些内容并添加一些内容: 同时进行删除和添加操作,比如删除一段代码并替换为新的代码,这也被视为一个修改。
-
创建一个新文件: 在版本库中新增一个文件,这同样被认为是一个修改,因为它改变了版本库的状态。
在 Git 中,每次修改都被记录下来,并且以一种高效的方式存储和管理。通过跟踪修改而不是文件本身,Git 能够更准确地追踪文件的变化历史,并且可以更有效地处理大型项目中的文件重命名、移动和合并等操作。这也是 Git 在版本控制领域中被广泛使用的一个重要原因之一。
我们现在就对Readme进行一次修改:

此时,仓库中的 Readme 和我们工作区的 Readme 是不同的,何查看当前仓库的状态呢?
在 Git 中,要查看当前仓库的状态,即了解工作区和暂存区的状态差异,可以使用 git status 命令。
执行 git status 命令后,Git 会显示出当前仓库中所有文件的状态信息,包括:
- 哪些文件已修改但尚未添加到暂存区(工作区修改)。
- 哪些文件已经添加到暂存区但尚未提交(暂存区修改)。
- 是否存在需要提交的文件,或者是否工作区干净(没有未跟踪或未修改的文件)。

根据提供的 git status 输出,可以看出当前仓库中的 Readme 文件已被修改,但尚未添加到暂存区。在输出中,Git 提示了两个重要的信息:
- Changes not staged for commit: 这部分指示了有哪些修改还未被添加到暂存区,即工作区中的修改。
- no changes added to commit: 这部分指示了尚未添加任何修改到暂存区,因此还没有准备好提交。
目前,我们只知道文件被修改了,如果能知道具体哪些地方被修改了,就更好了。

git diff 命令是非常有用的工具,可以用来显示工作区和暂存区之间、或者版本库和工作区之间的文件差异。使用 git diff 命令可以帮助你具体了解文件的修改情况,包括哪些地方被修改了以及修改的具体内容。
显示工作区和暂存区之间的差异:
git diff [file]这会显示指定文件在工作区和暂存区之间的差异,包括哪些地方被修改了以及修改的具体内容。
显示版本库和工作区之间的差异:
git diff HEAD -- [file]这会显示指定文件在版本库和工作区之间的差异,即你当前工作的分支(通常是 master 分支)和工作目录中文件之间的差异。
git diff 命令显示的差异信息格式与 Unix 通用的 diff 格式一致。这种格式通常包含了修改的上下文信息以及具体的变更内容。一般来说,每个修改都以一个描述性的标记开头,例如:
- + 表示新增的内容。
- - 表示删除的内容。
- @@ 表示上下文信息,标识了修改的位置。
由此,我们可以得到刚刚打印出来的信息:
- diff --git a/Readme b/Readme:这一行指示了文件的路径和名称,a/Readme 表示旧文件,b/Readme 表示新文件。
- index 6972ae3..1139197 100644:这一行显示了文件索引信息,其中 6972ae3 是旧文件的索引,1139197 是新文件的索引。100644 表示文件的权限和类型。
- --- a/Readme 和 +++ b/Readme:这两行指示了旧文件和新文件的路径和名称。
- @@ -1,2 +1,3 @@:这一行提供了修改的上下文信息。-1,2 表示旧文件中从第 1 行开始的连续 2 行内容,+1,3 表示新文件中从第 1 行开始的连续 3 行内容。
- Hey~~~ 和 Long time no see!!!:这两行是旧文件中的内容,表示被修改之前的内容。
- +This is the first change~:这一行是新文件中的内容,表示新增的内容。根据 + 符号,可以看出这是一个新增的行,内容是 This is the first change~。
知道了对 ReadMe 做了什么修改后,再把它提交到本地仓库就放心多了。

- Changes to be committed:这一行表明有一些修改已经被添加到了暂存区,即这些修改已经准备好被提交到版本库中。
- (use "git restore --staged <file>..." to unstage):这是一个提醒,告诉我们如果需要取消暂存区的修改,可以使用 git restore --staged <file> 命令来将文件恢复到未暂存的状态。

版本回退
在Git中,版本回退是一项重要的功能,它允许我们将代码库中的状态恢复到历史上的某个特定版本。当我们发现之前的工作出现了严重的问题,或者需要重新开始某个特定的历史版本时,版本回退功能就变得至关重要了。而git reset命令正是用于实现版本回退的关键命令。
通过执行git reset命令,就可以将当前的工作区、暂存区以及版本库中的状态回退到我们指定的某个提交版本。这个提交版本可以是通过提交号、分支名、相对于当前版本的偏移量等方式指定。
git reset命令的基本语法格式如下:
git reset [--soft | --mixed | --hard] [commit]
当执行 git reset 命令用于版本回退时,其本质是将版本库中的内容进行回退。
具体回退到哪个版本以及是否影响工作区或暂存区的内容则由命令参数决定:
- --mixed:默认选项,可以省略参数。该参数将暂存区的内容回退为指定提交版本的内容,但工作区的文件保持不变。换句话说,这个选项会将暂存区的状态回退到指定版本,但不会影响工作区的文件。这意味着,工作区中的文件保持未变化,我们需要手动撤销或修改工作区中的文件。
- --soft:这个参数对工作区和暂存区的内容都不做改变,只是将版本库回退到某个指定版本。换句话说,暂存区和工作区的内容保持不变,只有版本库中的指针移动到了指定的提交版本。因此,使用这个参数可以让我们“虚拟”地回到过去的某个版本,而不会影响当前的工作区和暂存区。
- --hard:这个参数会将暂存区和工作区都回退到指定版本。使用这个参数时需要格外小心,因为它会丢弃暂存区和工作区中的所有变更,将它们都恢复到指定版本的状态。如果工作区中有未提交的代码修改,执行这个命令后这些修改都将丢失。因此,在使用这个参数时要非常慎重,确保不会丢失重要的工作。
HEAD 说明:
- HEAD 可以直接指定为 commit id,表示要回退到的具体提交版本。
- HEAD 表示当前版本。
- HEAD^ 表示上一个版本。
- HEAD^^ 表示上上一个版本。
- 以此类推...
数字表达式:
可以使用数字来表示相对于当前版本的偏移量。
- HEAD~0 表示当前版本。
- HEAD~1 表示上一个版本。
- HEAD^2 表示上上一个版本。
- 以此类推...
总之,git reset 命令是一个强大的工具,允许我们在需要时回退到任何一个历史版本,但需要根据具体情况选择合适的参数以及版本,以避免意外丢失工作成果。

那么如果我们回退完成之后又后悔了咋办?

在我们的操作中,我们通过 git reset --hard 命令将 HEAD 指针移动到了之前的某个特定的提交版本,这个版本就是我们指定的 commit id。在第一次使用 git reset --hard 命令时,我们将 HEAD 指针移动到了 ff1e0bb3153ae267f9249567a057e1520383a3bc 这个提交版本,这是我们指定的历史版本。
然后,我们再次使用 git reset --hard 命令将 HEAD 指针移动到了另一个提交版本 93bca23be22103a1ce0c57ec75d253658ace91e1。这意味着我们又将 HEAD 指针重新指向了另一个历史版本。
通过这两次 git reset --hard 操作,我们实际上是在版本历史中来回移动 HEAD 指针,指向不同的提交版本。这种操作并不是将版本库中的内容进行恢复,而是在版本控制系统中移动 HEAD 指针,以指向不同的历史版本,因此我们可以多次进行版本回退。
那么如果我们回退之后不小心把服务器关了,或者屏幕清了:


此时我们怎么“吃后悔药”呢?

git reflog 是 Git 中的一个命令,用于查看本地仓库的引用日志(reference logs)。引用日志记录了本地仓库中 HEAD 和分支的移动历史,即使在重置或回退后,也可以通过引用日志找到之前的提交状态。
- 引用日志是什么?引用日志是 Git 中的一种记录机制,用于追踪本地仓库的引用(如 HEAD、分支、标签等)的移动历史。每次引用发生变化时,Git 将会更新引用日志。
- 引用日志中包含的信息:引用日志会显示每次引用变动的提交哈希(commit hash)、引用(如 HEAD、分支名)、变动操作(如提交、分支切换)、时间戳等信息。
- 引用日志的作用:引用日志可以帮助我们查找历史操作记录,特别是在执行了诸如重置(reset)、回退(checkout)、合并(merge)等改变分支状态的操作后,可以使用引用日志找回之前的状态。
注意事项:
- 引用日志只在本地存在,不会被推送到远程仓库中。
- 引用日志中的信息并不是永久保存的,会随着时间和 Git 命令的执行而被覆盖。
通过使用 git reflog,我们可以更好地理解和管理本地仓库的引用状态,同时在需要时进行版本恢复或调整。

我们照样可以使用commitID的一部分进行回退:

再次强调,Git 版本回退的速度之所以如此迅速,是因为 Git 在内部维护了一个指向当前分支(通常是 master 分支)的 HEAD 指针,并且保存了当前 master 分支的最新提交的 commit id 在 refs/heads/master 文件中。因此,当我们执行版本回退操作时,Git 实际上只需修改 refs/heads/master 文件,将其指向特定的提交版本即可,而无需对整个仓库的文件进行复杂的操作。这种简洁高效的机制使得 Git 能够在瞬间完成版本回退,让开发人员能够快速、轻松地管理代码历史。

撤销修改
如果我们在工作区写了很长时间的代码,但又觉得写的代码实在是很不理想,想要恢复到上一个版本。
情况一:对于工作区的代码,还没有 add
我们先对Readme文件进行一些修改:

此时想要撤销这次修改,当然可以使用 vim 命令直接编辑我们的文件内容。
然而,如果我们已经写了很长时间的代码,但尚未进行提交,要撤销这些修改就变得更加困难,因为我们可能已经忘记了我们到底修改了哪些内容。在这种情况下,我们可以使用 git checkout -- [file] 命令来让工作区的文件回到最近一次添加或提交时的状态。
具体而言,git checkout -- [file] 命令会将指定文件恢复到最近一次添加或提交时的状态,丢弃工作区中的任何未提交修改。这样可以避免手动编辑文件或使用 git diff 命令查看差异并手动删除,节省了时间和精力。
需要注意的是,git checkout -- [file] 命令中的双横线 -- 非常重要,不能省略。因为如果省略了双横线,这个命令就会变成另外一个意思,可能会产生意想不到的结果。

因此,通过使用 git checkout -- [file] 命令,我们可以快速、高效地撤销工作区中未提交的修改,不需要手动比较和删除代码,避免了潜在的错误和麻烦。
情况二:已经 add ,但没有 commit
add 后还是保存到了暂存区呢?怎么撤销呢?

让我们来回忆一下学过的 git reset 回退命令:
git reset 是一个用于回退版本的重要命令。当使用 git reset --mixed 参数时,它可以将暂存区的内容退回到指定的版本内容,同时保持工作区文件不变(此时就回到了我们的情况一)。当然,也可以选择 --hard 参数对工作区和暂存区同时进行回退。
另外,git reset 还可以用来回退到当前版本。
具体来说:
- 使用 git reset --mixed <commit> 命令可以将暂存区的内容退回到指定的 <commit> 版本内容,但工作区的文件不会受到影响。这意味着,指定版本之后的修改内容会被移动到工作区,并保留在未暂存的状态下。
- 另外,如果我们想回退到当前版本(也就是和版本库保持一致的版本),可以使用 git reset --mixed HEAD 命令。这将取消暂存区的所有内容,并将它们移动到工作区,但不会影响工作区的文件。这样可以撤销暂存区的所有更改,让我们重新开始添加和提交更改。

情况三:已经 add ,并且也 commit 了
同理,我们可以使用 git reset --hard HEAD^ 命令来回退到上一个版本的情景。这个命令会将当前分支的 HEAD 指针移动到上一个提交,同时将工作区和暂存区的内容都回退到上一个版本。
但是,这种回退方式有一个重要的前提条件:我们的本地版本库尚未推送到远程版本库。
由于Git是一种分布式版本控制系统,每个开发者都有自己的本地版本库,而远程版本库是共享的中央仓库。
如果我们已经将我们的本地提交push推送到远程版本库,并且其他开发者也已经在远程版本库中工作了,那么使用 git reset --hard 命令将会带来一些问题:
- 我们的本地工作将会被彻底覆盖,所有未提交的修改都将丢失。
- 如果我们尝试将这些丢失的提交推送到远程版本库,可能会导致合并冲突和代码丢失。
因此,在使用 git reset --hard 命令时,务必确保我们的本地提交尚未推送到远程版本库,以免造成不可挽回的损失。

删除文件
在 Git 中,删除也是一个修改操作,我们实战一下。
如果要删除 file1 文件,怎么做?

但是这只是对工作区中的文件进行了删除:

此时,工作区和版本库已经不一致了,因为我们只删除了工作区的文件,而版本库中的文件仍然存在。如果要彻底删除文件,需要同时清除工作区和版本库中的文件。
为了完成这个任务,我们可以使用 git rm 命令将文件从暂存区和工作区中删除,并且随后运行 git commit -m "Remove [file]" 命令,提交删除操作,以记录这一变更。

还有一种更简略的命令方式:

git rm 命令可以更简便地完成删除文件的操作,而不需要分成两步骤。
分支管理
理解分支
绍 Git 的杀手级功能之一就是分支。
我们通过一个简单的例子来理解一下什么是分支。
当你在做一次旅行计划时,你可以将每个目的地看作是旅行计划的一个分支。
假设你计划进行一次穿越欧洲的旅行。你的旅行计划可能包括巴黎、伦敦和罗马等多个目的地。你可以将每个目的地看作是旅行计划的一个分支。
- 分支就像旅行目的地:每个分支就像是旅行计划中的一个目的地,你可以在每个目的地停留一段时间,探索当地的风土人情和景点。就像旅行中选择不同的目的地一样,每个分支都代表了旅行计划中的一个独立部分。
- 互不干扰的探索:当你在巴黎的分支上计划行程时,你的行程安排和计划只会影响到巴黎这个目的地的探索,而不会影响其他目的地。同样地,当你在伦敦的分支上计划行程时,你的活动也只会影响到伦敦这个目的地。
- 分支合并:然而,在某个时刻,当你已经完成了每个目的地的探索后,你可能会将这些分支合并在一起,形成整个旅行计划。这就像是将不同的目的地合并成一个完整的旅行计划。在合并后,你会发现自己已经完成了一次穿越欧洲的旅行,而每个目的地的探索成果都汇聚在了一起,这就是分支合并的结果。
在版本回退的概念中,我们已经了解到,每次在Git中进行提交操作时,Git会将这些提交串联起来形成一个时间线,这个时间线可以被理解为一个分支。目前为止,我们只有一条时间线,在Git中,这个分支被称为主分支,即master分支。
-
理解主分支(master):主分支(master)是Git中的默认分支,它是版本控制历史的主要线索。所有的提交都沿着主分支进行,形成一个线性的历史记录。在开始项目时,通常会在主分支上进行开发和提交。
-
理解HEAD指针:严格来说,HEAD指针并不直接指向提交,而是指向当前分支。也就是说,HEAD指针指向当前活动的分支,而该分支则指向最新的提交。因此,当我们在Git中查看HEAD时,我们实际上是在查看当前所在的分支。
-
主分支的移动:每次进行提交操作,主分支(master)都会向前移动一步,指向最新的提交。这意味着随着我们不断地进行提交,主分支的线性历史记录也会不断地延长。而HEAD指针则会随着主分支的移动而保持指向当前分支的位置,这样即使主分支在提交后移动,HEAD也会跟随着当前分支移动。

通过查看当前的版本库,我们也能清晰的理出思路:



创建分支
Git 支持我们查看或创建其他分支。
首先我们可以看看当前仓库中有哪些本地分支:

需要明确的一点就是,除了指向主分支master之外,HEAD也可以指向其他分支,被指向的分支就是当前正在工作的分支。
这意味着我们可以在不同的分支之间切换,使得我们可以在不同的工作环境中进行开发,并且保持每个分支的独立性。例如,我们可以在开发一个新功能时切换到一个专门的功能分支,完成后再切换回主分支进行合并操作。通过这种方式,我们可以更加灵活地管理我们的项目,并且更好地控制版本和功能的开发进度。
在这里,我们来创建第一个自己的分支,命名为 dev。创建新分支的命令如下:

创建新的分支后,Git会新建一个指针,称为dev,此时的 * 号表示当前HEAD指向的分支是主分支master。

此外,通过目录结构可以发现,新的dev分支已经创建:


而且可以观察到,目前dev和master指向了相同的提交记录。

切换分支
那如何切换到 dev 分支下进行开发呢?
使用 git checkout 命令即可完成切换:

注意,我们先前强调过 git checkout进行回退操作的时候一定要加上“ -- ”,现在你可以理解了。
在 Git 中,git checkout 命令有多种用法,省略了 -- 时,Git 可能会将 [file] 解释为分支名、提交哈希值或者其他引用,而不是文件名。
比如我们现在执行 git checkout [branch],Git 将会切换到指定的分支,并将工作区和暂存区的内容更新为该分支的最新状态。

接下来,在 dev 分支下修改 ReadMe 文件,新增一行内容,并进行一次提交操作:

现在再切换回master分支:

切换回 master 分⽀后,发现ReadMe⽂件中新增的内容不见了!!!
在 dev 分支上,内容还在。为什么会出现这个现象呢?我们来看看 dev 分支和 master 分支指向,发现两者指向的提交是不⼀样的:

合并分支
为了在 master 主分支上能看到新的提交,就需要将 dev 分支合并到 master 分支:

git merge 命令用于合并指定分支到当前分支。通过合并分支,我们可以将不同分支的工作成果整合在一起,使得项目的功能得以完善和增强。合并分支时,Git会尝试将两个分支的更改合并到一起,并解决任何可能的冲突。最终,合并操作会生成一个新的提交,其中包含了两个分支的所有更改,这样我们就可以在当前分支上继续开发和工作。
"Fast-forward" 是 Git 在执行合并操作时的一种情况,表示当前分支可以简单地移动到要合并的分支的最新提交,而无需进行实际的合并操作。
具体来说,当我们执行 git merge 命令时,如果要合并的分支是当前分支的直接上游(即当前分支是要合并的分支的祖先),并且没有新的提交产生,那么 Git 就会执行 "Fast-forward" 合并。这种情况下,Git 只需要将当前分支移动到要合并分支的最新提交,从而完成合并操作。


删除分支
合并完成后, dev 分⽀对于我们来说就没⽤了, 那么dev分支就可以被删除掉,注意如果当前正处于这个要被删除的分支下,就不能删除当前分支:

可以在其他分支下删除当前分支:


因为创建、合并和删除分支在Git中都非常迅速,所以Git鼓励你使用分支来完成某个任务,然后在合并后再删除分支。这种做法与直接在主分支(master)上工作的效果是一样的,但是使用分支的方式更为安全。
综上,我们总结一下整个流程:
-
创建分支: 首先,我们可以创建一个新的分支来专门处理某个任务或功能。这样做的好处是,我们可以在不影响主分支的情况下进行工作,并保持主分支的稳定性。创建分支的过程非常快速,并且不会影响其他分支或主分支的状态。
-
在分支上进行工作: 接着,我们可以在新创建的分支上进行工作,完成我们的任务或功能开发。在这个分支上进行的所有提交都将仅影响到这个分支,不会对其他分支产生影响。这样可以确保我们的工作在不干扰其他人或项目的情况下进行。
-
合并分支: 当我们完成了任务或功能开发后,我们可以将这个分支合并回主分支。这个过程也非常快速,特别是如果合并过程中没有冲突的话。一旦合并完成,我们的工作成果就会整合到主分支中,这样其他人也可以访问和使用你的代码。
-
删除分支: 最后,一旦我们确认工作已经合并到了主分支,并且不再需要这个分支了,我们就可以安全地删除这个分支。这样可以保持仓库的整洁,并避免分支过多导致管理上的混乱。
总之,使用分支来完成任务并在合并后删除分支是一种安全且有效的工作流程。这样可以保持主分支的稳定性,同时允许我们在不影响其他人或项目的情况下进行独立的开发工作。
合并冲突
在实际的分支合并过程中,有时候可能会遇到代码冲突的问题。这种情况发生在两个分支修改了同一个文件的同一部分,Git 不知道应该保留哪一种修改,因此需要人为干预来解决冲突。
在 dev2 分支下修改 ReadMe 文件,更改文件内容如下,并进行一次提交:

补充一点,我们也可以使用第二种方式创建并直接切换到新的分支上。
切换至 master 分支,此时在 master 分支上,我们对 ReadMe 文件再进行一次修改,并进行提交,如下:

现在, master 分支和 dev1 分支各自都分别有新的提交,变成了这样:

这种情况下,Git 只能试图把各⾃的修改合并起来,但这种合并就可能会有冲突:


当出现代码冲突时,Git 会标记出冲突的文件,并在文件中显示冲突的部分。此时,我们需要手动编辑这些文件,解决冲突,并手动标记哪些修改需要保留,哪些需要丢弃。解决冲突后,我们需要将文件标记为已解决冲突,然后提交合并结果。
我们此时手动调整冲突代码,并再次提交修正后的结果!(再次提交很重要,切勿忘记!!!)



到这⾥冲突就解决完成,此时的状态变成了:


虽然代码冲突可能会稍微增加合并分支的复杂性,但这也是 Git 强大的一面,因为它能够帮助我们发现代码之间的潜在冲突,并促使我们及时解决。通过解决冲突,我们可以确保合并后的代码是高质量、可用的,从而提高项目的稳定性和可维护性。
因此,虽然在合并分支时可能会遇到代码冲突的问题,但通过适当的解决方法,我们可以有效地处理这些冲突,并最终成功地合并分支,使得项目得以顺利进行。
另外,我们可以使用日志画出当前图:

git log --graph --abbrev-commit命令用于查看提交历史,并以图形化方式展示分支与合并情况,以及每个提交的简短哈希值。
执行该命令后,将显示一个图形化的提交历史,其中每个提交都由其哈希值表示,并且通过图形化的方式展示了分支和合并的关系。这种图形化的展示有助于更清晰地理解项目的版本控制历史,以及各个分支之间的关系。
最后,不要忘记 dev2 分支使用完毕后就可以删除了:

分支管理策略
通常情况下,当合并分支时,如果可能,Git会采用Fast-forward模式。

还记得如果我们采用 Fast forward 模式之后,形成的合并结果是什么呢?回顾一下 :


在这种Fast-forward模式下,如果我们在合并后删除了分支,查看提交历史时会丢失分支信息,因此无法准确知道最新提交是通过合并进来的还是正常提交的。
但是你应该还有印象,在合并冲突时,Git会创建一个新的合并提交,其中包含了解决冲突后的更改,并且可以清晰地看到这个合并提交是由哪个分支的哪个提交所触发的。这种情况下,就不再是Fast-forward模式了。
这种方式的好处是,在提交历史中可以清晰地看到合并的细节,包括哪个分支的哪些提交被合并了进来,以及在合并冲突时是如何解决的。这样做可以让我们更容易地理解项目的演变过程,并追踪到各个提交的来源。
即使在合并完成后删除了分支,我们仍然可以通过提交历史来看出实际的合并情况。这种方式不仅提供了更多的历史信息,还能够帮助我们更好地理解和管理项目的版本控制历史。

Git支持我们在合并分支时强制禁用Fast-forward模式,这样在合并时就会生成一个新的合并提交,即使没有发生冲突。这种方式确保了在合并操作后能够保留分支信息,使得从分支历史上可以清晰地看出各个分支的合并情况。
通过禁用Fast-forward模式,每次合并都会生成一个新的合并提交,即使在没有冲突的情况下也会如此。这样做的好处是,可以在提交历史中准确地追踪到每个分支的合并情况,了解每个提交的来源和影响。
通过这种方式,我们可以更好地管理项目的版本控制历史,保留各个分支的信息,使得项目的演变过程更加清晰可见。这对于团队协作和项目维护都非常有帮助,因为可以更容易地理解和追踪代码的变化和来源。
下面我们实战一下 --no-ff 方式的 git merge。首先,创建新的分支 dev4,并切换至新的分支。接着,修改 ReadMe 文件,并提交一个新的 commit:


切回 master 分支,开始合并:

注意,使用 --no-ff 参数可以禁用Fast-forward模式,在合并分支时创建一个新的提交,即使没有发生冲突。而且,结合 -m 参数可以在合并时添加一条描述信息,以便记录这次合并的目的或内容。
合并后,查看分支历史:

可以看到,不使用 Fast forward 模式,merge 后就像这样:

这样就成功地使用 --no-ff 方式进行了合并,并且创建了一个新的 commit 来保留分支的历史信息。
分支策略
在实际开发中,分支管理是非常重要的,它可以帮助我们组织和管理项目的代码,确保团队成员可以独立地进行工作,并且在需要时可以轻松地将各自的工作集成到主代码库中。以下是一些基本的分支管理原则:
-
稳定的主分支(master): 主分支应该是非常稳定的,主要用于发布新版本。在日常开发中,我们不应该直接在主分支上工作,以免影响已经发布或即将发布的版本的稳定性。
-
开发活动在开发分支(dev)上: 实际的开发活动应该在开发分支上进行。开发分支通常被认为是不稳定的,因为它是用来集成各种开发工作的地方。开发人员可以在这个分支上自由地添加新功能、修复bug等。
-
版本发布通过合并到主分支: 当开发工作完成,一个稳定的版本要发布时,我们可以将开发分支合并到主分支上。这意味着开发的新功能和修复的bug将被集成到主分支中,准备发布为新版本。
-
个人分支(feature branches): 每个开发人员通常都有自己的个人分支,用于开发特定的功能或解决特定的问题。这些个人分支可以从开发分支(如dev)上创建,并在完成工作后合并回开发分支。
总的来说,团队成员在开发过程中应该遵循以上原则,将主要的开发工作集中在开发分支上,保持主分支的稳定性,然后定期将开发工作合并到主分支上发布新版本。这样可以有效地组织团队的工作流程,确保项目的稳定性和可维护性。

所以,团队合作的分⽀看起来就像这样:

bug 分支
假设我们当前正在dev4分支上进行开发,但在开发过程中却突然发现了主分支master上存在一个bug需要立即解决。在Git中,我们可以采取一种有效的方式来解决这个问题:针对每个bug,我们可以创建一个新的临时分支来进行修复。一旦修复完成,我们将这个临时分支合并回主分支,然后安全地将其删除,以保持项目的整洁和可维护性。
可现在 dev4 的代码在工作区中开发了一半,还无法提交,怎么办?

我们现在已经对dev4中Readme文件进行了修改,此时如果我们直接切换回master分支:

可以看到工作区中已经进行了相应的修改。
但是此时我们并不希望在本来稳定的master分支上看到我们其他分支修改过的内容。
Git提供了git stash命令,用于将当前工作区的修改暂存起来,这样我们就可以在未来的某个时候恢复这些被暂存的内容。需要注意的是,stash中存储的是已经被我们追踪管理的文件的修改。换句话说,如果文件尚未被Git追踪,那么对该文件的修改不会被stash存储。


用 git status 查看⼯作区,就是干净的(除非有没有被 Git 管理的文件),因此可以放心地创建分 支来修复bug:
储藏 dev4 工作区之后,由于我们要基于master分支修复 bug,所以需要切回 master 分支,再新 建临时分支来修复 bug:


修复完成后,切换到 master 分支,并完成合并,最后删除 fix_bug 分支:

至此,bug 的修复工作已经做完了,我们还要继续回到 dev4 分支进行开发。
我们切换回 dev4 分支:

工作区是干净的,刚才的工作现场存到哪去了?用 git stash list 命令看看:

当我们需要恢复之前存储在stash中的工作现场时,可以使用git stash pop命令。这个命令会从stash中恢复最近一次存储的工作现场,并将其应用到当前工作区中。同时,这个命令也会将这个恢复的stash从stash列表中删除,这意味着我们恢复的同时也将其移出了stash堆栈。


再次查看的时候,我们已经发现已经没有现场可以恢复了:

另外,恢复工作现场也可以采用git stash apply命令。不同于git stash pop命令,恢复后,stash中的内容并不会自动删除,需要我们手动使用git stash drop命令来删除。这样就可以保留stash中的内容,以备将来再次恢复使用。
同时,我们可以多次使用stash来保存不同的工作现场。当需要恢复时,我们可以先使用git stash list命令来查看stash堆栈中保存的所有工作现场,然后根据需要选择要恢复的stash。例如,我们可以使用git stash apply stash@{0}命令来恢复指定的stash。
恢复完代码之后我们便可以继续完成开发,开发完成后便可以进行提交。


但我们注意到了,修复 bug 的内容,并没有在 dev4 上显示。
此时的状态图为:

Master分支目前最新的提交领先于新建dev4分支时基于的master分支的提交,因此在dev4分支中我们当然看不到修复bug的相关代码。
我们的最终目标是要让master分支合并dev4分支的内容,通常情况下我们可以切换回master分支直接进行合并。然而,这种方式存在一定的风险。合并分支时可能会出现冲突,而解决代码冲突需要我们手动干预(在master分支上解决)。我们无法保证一次性解决所有的冲突问题,因为在实际项目中,代码冲突可能涉及数十行甚至数百行,解决过程中可能会出现错误,导致错误的代码被错误地合并到master分支上。
因此,在这种情况下,我们的状态是:

解决这个问题的一个好的建议就是:最好在自己的分支上先合并master分支,然后再让master分支去合并dev4分支。这样做的目的是,如果存在冲突,我们可以在本地分支上解决,并进行测试,而不会影响主分支master的稳定性。








删除临时分支
在软件开发中,我们经常面临着无穷无尽的新功能需求,这些新功能需要不断地添加进项目中以满足用户的需求。
当我们要添加一个新功能时,我们肯定不希望因为一些实验性质的代码而破坏主分支的稳定性。因此,每当添加一个新功能时,最好的做法是新建一个分支,通常我们将这个分支称为feature分支。在这个分支上进行开发工作,待功能完成后,再将其合并回主分支,最后可以删除这个feature分支,以保持项目结构的清晰和整洁。
然而,有时候我们可能会遇到这样的情况:我们正在某个feature分支上开发某个功能,但突然间产品经理叫停了这个功能的开发。尽管我们白干了一场,但这个feature分支仍然需要被删除,因为它已经变得无用了。然而,使用传统的git branch -d命令来删除分支是不行的。
使用传统的git branch -d命令来删除分支时,Git会检查该分支的commit历史是否完全合并到其他分支中。如果有任何未合并的更改,Git会阻止分支的删除,以防止数据丢失。这是为了保护用户不意外地删除尚未合并的重要更改,从而防止数据丢失或不一致的情况发生。因此,在上述情况下,由于我们的feature分支虽然被开发了一半,但在产品经理叫停后并没有被合并到其他分支中,因此使用git branch -d删除命令会失败。
 在这种情况下,如果确定要删除未合并的feature分支,可以使用强制删除分支的命令git branch -D。这个命令会强制删除分支,即使分支上有未合并的更改,但需要注意的是,使用这个命令会导致未合并的更改永久丢失,因此在使用之前,一定要确保已经备份或不再需要这些更改。
在这种情况下,如果确定要删除未合并的feature分支,可以使用强制删除分支的命令git branch -D。这个命令会强制删除分支,即使分支上有未合并的更改,但需要注意的是,使用这个命令会导致未合并的更改永久丢失,因此在使用之前,一定要确保已经备份或不再需要这些更改。
 文章来源:https://www.toymoban.com/news/detail-844497.html
文章来源:https://www.toymoban.com/news/detail-844497.html
 文章来源地址https://www.toymoban.com/news/detail-844497.html
文章来源地址https://www.toymoban.com/news/detail-844497.html
到了这里,关于Git学习(一)基于本地操作:Git初识、Git安装(Linux-ubuntu)、Git 基本操作、分支管理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!