关注小庄 顿顿解馋๑ᵒᯅᵒ๑

引言:上回我们讲解了单链表(单向不循环不带头链表),我们可以发现他是存在一定缺陷的,比如尾删的时候需要遍历一遍链表,这会大大降低我们的性能,再比如对于链表中的一个结点我们是无法直接访问它的上一个结点,那有什么解决方法呢?这里就得请出我们今天的主角----双链表。
一. 🏠 什么是双链表
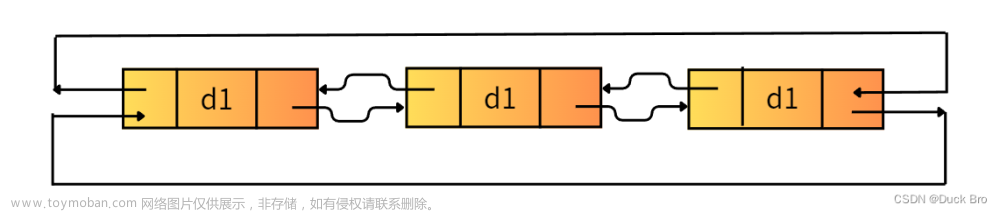
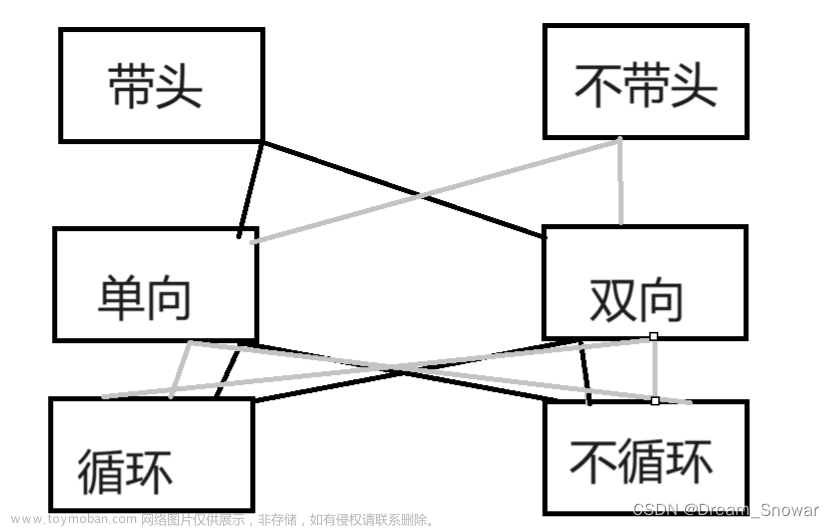
在这里我们讲的双链表有三个特点 :双向 , 循环 , 带头 。我们分别理解这三个特点~
-
双向 循环

优势:1.每一个结点都能很方便访问它的后一个结点和前一个结点 2.方便找到尾节点,提高了效率。 -
带头

图中的head就是哨兵位
- 这里的
带头跟我们之前所说的头节点有所不同,这里的带头,不存储有效数据起到一个哨兵的作用。- 哨兵位的作用:
遍历循环链表避免死循环,其次涉及到头节点的删除和插入时,无需考虑NULL的问题。
双链表的这三个特点将会使得实现它比实现单链表更简单~
二. 🏠 双链表的实现
👿 双链表结点
为了能循环和双向,我们双链表的一个结点需要两个指针。
typedef int Datatype;
typedef struct ListNode
{
struct ListNode* next;
struct ListNode* pre;
Datatype x;
}ListNode;
👿 双链表哨兵位的创建
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
if (NULL == newnode)
{
perror("malloc failed");
return;
}
newnode->x = x;
newnode->next = newnode;
newnode->pre = newnode;
1.注意next指针和pre指针都要指向自己。
2.由于插入数据也要创建新结点,所以我们可以直接创建一个申请结点的接口方便复用。
//申请新结点的接口
ListNode* BuyNode(Datatype x)
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
if (NULL == newnode)
{
perror("malloc failed");
return;
}
newnode->x = x;
newnode->next = newnode;
newnode->pre = newnode;
return newnode;
}
// 创建返回链表的头结点.
ListNode* ListCreate()
{
ListNode* phead = BuyNode(-1); //哨兵位
return phead;
}
👿 双链表插入数据
- 尾插
双链表的尾插指的是将新节点插入到哨兵位之前
1.黄色箭头和蓝色箭头是我们要修改的指针指向
2.注意:要先改变蓝色箭头的对应关系,如果先让head的pre变成newnode话,后边newnode->pre = plist就会指向自己
3.小技巧:不管三七二十一,插入直接先改newnode的next和pre
// 双向链表尾插 尾插是插到plist的前面
void ListPushBack(ListNode* plist, Datatype x)
{
assert(plist);
ListNode* newnode = BuyNode(x);
newnode->next = plist;
newnode->pre = plist->pre;
plist->pre->next = newnode;
plist->pre = newnode;
}
- 头插

// 双向链表头插 头插是插到哨兵位的后面
void ListPushFront(ListNode* plist, Datatype x)
{
ListNode* newnode = BuyNode(x);
ListNode* del = plist->next;
newnode->next = del;
newnode->pre = plist;
del->pre = newnode;
plist->next = newnode;
}
*是不是很easy,跟单链表比起来 ~ *
👿 双链表删除数据
- 尾删

对于尾删 只需要改它前面一个结点next和哨兵位的pre就好了,存好pre结点的位置
void ListPopBack(ListNode* plist)
{
assert(plist);
assert(plist->next != plist);
ListNode* ptail = plist->pre;
ListNode* pre = ptail->pre;
pre->next = plist;
plist->pre = pre;
free(ptail);
ptail = NULL;
}
- 头删

// 双向链表头删
void ListPopFront(ListNode* plist)
{
assert(plist);
assert(plist->next != plist);
ListNode* pNext = plist->next->next;
ListNode* pcur = plist->next;
plist->next = pNext;
pNext->pre = plist;
free(pcur);
pcur = NULL;
}
👿 双链表查找
遍历链表找到就停下,如果没找到循环到head停止,返回NULL。大大提现了哨兵位的好处
// 双向链表查找
ListNode* ListFind(ListNode* plist, Datatype x)
{
assert(plist);
ListNode* pcur = plist->next;
while (pcur != plist)
{
if (pcur->x == x)
{
return pcur;
}
pcur = pcur->next;
}
return NULL;
}
👿 pos结点前插入数据和删除pos结点数据
类似尾插尾删,头插头删,改变指针指向即可
// 双向链表在pos的前面进行插入
void ListInsert(ListNode* pos, Datatype x)
{
assert(pos);
ListNode* newnode = BuyNode(x);
ListNode* pre = pos->pre;
newnode->next = pos;
newnode->pre = pre;
pre->next = newnode;
pos->pre = newnode;
}
// 双向链表删除pos位置的结点
void ListErase(ListNode* pos)
{
assert(pos);
ListNode* pre = pos->pre;
ListNode* pNext = pos->next;
pre->next = pNext;
pNext->pre = pre;
free(pos);
pos = NULL;
}
👿 双链表打印和销毁
循环遍历到phead停止~
// 双向链表打印
void ListPrint(ListNode* plist)
{
assert(plist);
ListNode* pcur = plist->next;
while (pcur != plist)
{
printf("%d->", pcur->x);
pcur = pcur->next;
}
printf("\n");
}
// 双向链表销毁
void ListDestory(ListNode* plist)
{
ListNode* pcur = plist->next;
while (pcur != plist)
{
ListNode* del = pcur->next;
free(pcur);
pcur = del;
}
free(pcur);
pcur = NULL; //无效
}
注意:由于函数形参是实参的一份临时拷贝,所以要在函数外手动置空!
三. 🏠 双链表的分析
经过如上我们实现的双链表结构,我们不禁发现它比单链表功能的强大,那它是否是完美的呢?答案是否的,没有完美的人,也没有完美的数据结构。
优点:
1.双链表单次任意位置插入和删除效率较高,比单链表还要效率高
2.双链表不存在空间浪费,按需申请和释放空间
3.双链表的一个结点可以访问前后结点(相比于单链表)缺点:
1.和单链表一样,虽然双链表访问尾结点快,但是任然不支持随机访问
2.cpu高速缓存命中率低,因为结点地址可能是分散的。文章来源:https://www.toymoban.com/news/detail-844728.html
本次双链表的讲解就到此结束啦,各位看官能否与我双向奔赴来个三连呢! ! !文章来源地址https://www.toymoban.com/news/detail-844728.html
到了这里,关于【数据结构】双向奔赴的爱恋 --- 双向链表的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!