XPath(XML Path Language)是XSLT标准的主要组成部分。它用于在XML文档中浏览元素和属性,提供了一种强大的定位和选择节点的方式。
XPath的基本特点

-
代表XML路径语言: XPath是一种用于在XML文档中导航和选择节点的语言。
-
路径样式语法: XPath使用路径表达式的“路径样式”语法来标识和导航XML文档中的节点。
-
包含200多个内置函数: XPath包含200多个内置函数,可用于处理字符串、数值、布尔值、日期和时间等。
-
XSLT的主要组成部分: XPath是XSLT(可扩展样式表语言转换)标准的主要组成部分,用于在XML文档中选择和操作数据
XPath路径表达式
XPath使用路径表达式来选择XML文档中的节点或节点集。这些路径表达式类似于在传统计算机文件系统中使用的路径表达式。
例如,/bookstore/book/title 是一个XPath路径表达式,表示选择根元素是bookstore的子元素book的子元素title。
XPath标准函数
XPath包括200多个内置函数,用于处理不同类型的数据。这些函数涵盖了字符串值、数值、布尔值、日期和时间比较、节点操作、序列操作等。
XPath表达式也可以在多种编程语言中使用,如JavaScript、Java、XML Schema、PHP、Python、C和C++等。
XPath用于XSLT
XPath是XSLT标准的主要组成部分,它与XSLT一起用于对XML文档进行转换和样式处理。具有XPath知识可以充分发挥XSLT的强大功能
XPath节点
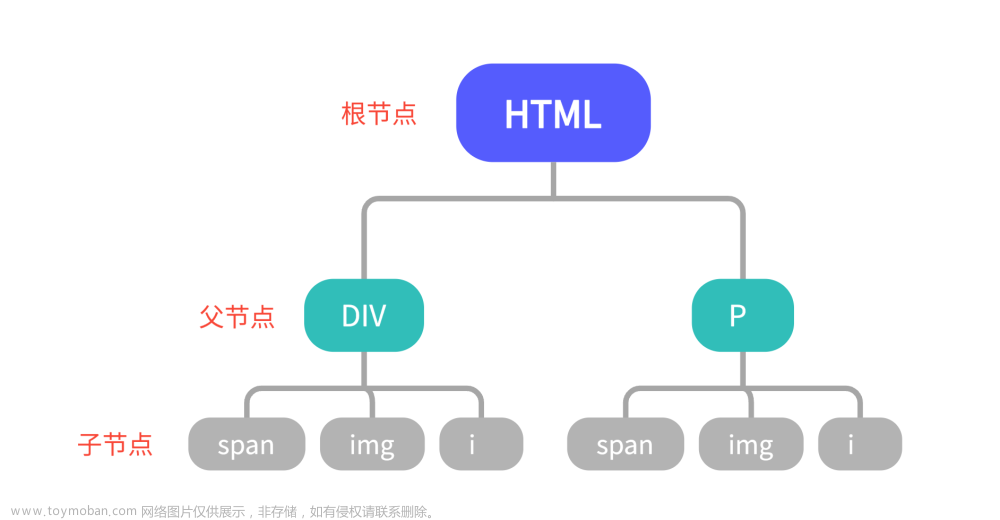
在XPath中,有七种节点:元素、属性、文本、命名空间、处理指令、注释和根节点。XML文档被视为节点树,树的最顶层元素称为根元素。
XPath术语
-
节点(Node): 在XPath中,有七种节点,包括元素、属性、文本、命名空间、处理指令、注释和根节点。XML文档被视为节点树,树的最顶层元素称为根元素。
-
原子值(Atomic Value): 原子值是没有子节点或父节点的节点。例如,字符串或数字。
-
项目(Item): 项目可以是原子值或节点。
节点之间的关系
在XPath中,节点之间有不同的关系:
-
父节点(Parent Node): 每个元素和属性都有一个父节点。
-
子节点(Child Node): 元素节点可以有零、一个或多个子节点。
-
同级节点(Sibling Node): 具有相同父节点的节点。
-
祖先节点(Ancestor Node): 节点的父节点、父节点的父节点等。
-
后代节点(Descendant Node): 节点的子节点、子节点的子节点等。
XPath语法
XPath使用路径表达式在XML文档中选择节点。以下是一些常用的XPath路径表达式:
-
nodename:选择所有名称为 "nodename" 的节点。 -
/:从根节点选择。 -
//:选择文档中与选择匹配的当前节点的位置无关的节点。 -
.:选择当前节点。 -
..:选择当前节点的父节点。 -
@:选择属性。
XPath示例文档
以下是我们将在下面的示例中使用的XML文档:
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="en">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
选择节点示例
以下是一些XPath路径表达式的示例及其结果:
-
/bookstore:选择所有名称为 "bookstore" 的节点。 -
/bookstore/book:选择根元素bookstore的子元素book。 -
//title[@lang='en']:选择所有具有值为 "en" 的 "lang" 属性的title元素。
选择未知节点
XPath通配符可用于选择未知的XML节点:
-
*:匹配任何元素节点。 -
@*:匹配任何属性节点。 -
node():匹配任何类型的节点。
例如,/bookstore/* 选择 bookstore 元素的所有子元素节点。
选择多个路径
通过在XPath表达式中使用 | 运算符,您可以选择多个路径:
-
//book/title | //book/price:选择所有book元素的title和price元素。 -
/bookstore/book/title | //price:选择bookstore元素的book元素的title元素 和 文档中的所有price元素。
XPath Axes(轴)
XML示例文档
以下是我们将在下面的示例中使用的XML文档:
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="en">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
XPath轴
在XPath中,轴表示与上下文(当前)节点的关系,并用于在树上相对于该节点定位其他节点。以下是常用的XPath轴及其描述:
-
ancestor: 选择当前节点的所有祖先(父、祖父等)。
-
ancestor-or-self: 选择当前节点的所有祖先(父、祖父等)以及当前节点本身。
-
attribute: 选择当前节点的所有属性。
-
child: 选择当前节点的所有子节点。
-
descendant: 选择当前节点的所有后代(子、孙等)。
-
descendant-or-self: 选择当前节点的所有后代(子、孙等)以及当前节点本身。
-
following: 选择当前节点结束标签之后的文档中的所有内容。
-
following-sibling: 选择当前节点之后的所有同级节点。
-
namespace: 选择当前节点的所有命名空间节点。
-
parent: 选择当前节点的父节点。
-
preceding: 选择文档中在当前节点之前出现的所有节点,但不包括祖先、属性节点和命名空间节点。
-
preceding-sibling: 选择当前节点之前的所有同级节点。
-
self: 选择当前节点。
位置路径表达式
位置路径可以是绝对的或相对的。绝对位置路径以斜杠(/)开头,而相对位置路径则不是。位置路径由一个或多个步骤组成,每个步骤之间用斜杠分隔。
以下是一些XPath位置路径表达式的示例及其结果:
-
/child::book:选择所有作为当前节点子元素的book节点。 -
/attribute::lang:选择当前节点的lang属性。 -
/child::*:选择当前节点的所有元素子节点。 -
/attribute::*:选择当前节点的所有属性。 -
/child::text():选择当前节点的所有文本节点子节点。 -
/child::node():选择当前节点的所有子节点。 -
/descendant::book:选择当前节点的所有book后代。 -
/ancestor::book:选择当前节点的所有book祖先。 -
/ancestor-or-self::book:选择当前节点的所有book祖先,如果当前节点本身是一个book节点,也选择当前节点本身。 -
/child::*/child::price:选择当前节点的所有price孙子节点。
XPath运算符
XPath表达式返回一个节点集、一个字符串、一个布尔值或一个数字。以下是XPath表达式中可用的运算符列表:
-
|:计算两个节点集。 -
+:加法。 -
-:减法。 -
*:乘法。 -
div:除法。 -
=:等于。 -
!=:不等于。 -
<:小于。 -
<=:小于或等于。 -
>:大于。 -
>=:大于或等于。 -
or:或。 -
and:与。 -
mod:取模(除法余数)。
最后
为了方便其他设备和平台的小伙伴观看往期文章:
微信公众号搜索:Let us Coding,关注后即可获取最新文章推送文章来源:https://www.toymoban.com/news/detail-844780.html
看完如果觉得有帮助,欢迎点赞、收藏、关注文章来源地址https://www.toymoban.com/news/detail-844780.html
到了这里,关于XML文档节点导航与选择指南的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[Java学习日记]日志、类加载器、XML、DTD与schema、XML解析、XPath、单元测试、Assert、BeforeAfter、注解、自定义注解、注解案例](https://imgs.yssmx.com/Uploads/2024/02/766853-1.png)
![[ tool ] Xpath选择器和selenium工具基本使用](https://imgs.yssmx.com/Uploads/2024/01/811824-1.png)