优化Elasticsearch数据存储有助于提升系统性能、降低成本、提高数据查询效率以及增强系统的稳定性和可靠性。通常我们再优化Elasticsearch数据存储会遇到一些问题,导致项目卡壳。以下是优化Elasticsearch数据存储的一些重要作用:

1、问题背景
在某些场景中,我们可能会考虑绕过数据库,直接使用Elasticsearch存储数据,并在Python应用程序中实时构建这些数据。这种方式可以带来一些优势,例如简化架构、提高性能等。然而,我们可能会遇到这样一个问题:数据生成速度非常快,同时发送大量请求到Elasticsearch,而Elasticsearch可能无法及时处理这些请求。因此,我们想知道是否可以使用队列缓冲系统,作为应用程序与Elasticsearch之间的中介。应用程序将数据发送到队列,队列再将数据发送到Elasticsearch,如果发送失败,队列会重试。我们不确定这种方法是否最合理、最有效的。希望了解队列缓冲系统,以及是否需要使用它来解决这个问题。
2、解决方案
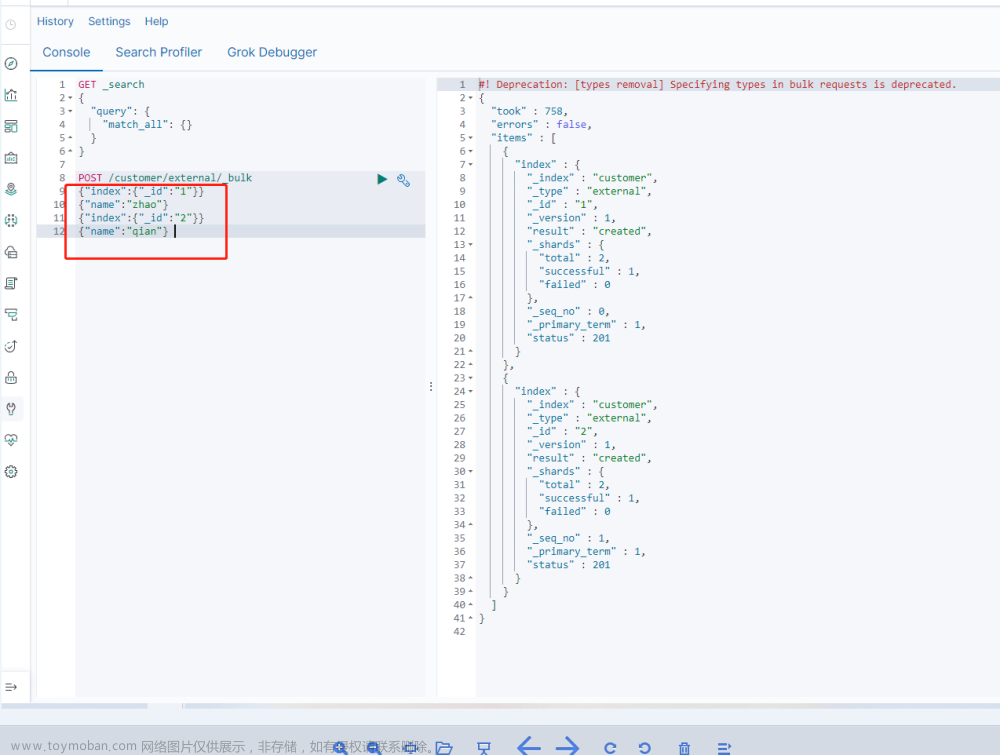
使用Elasticsearch批量索引API
Elasticsearch的批量索引API具有很高的效率,可以处理大量的数据。具体性能会根据源文档和分析器的复杂性有所变化。用户需要对不同大小的批量进行测试,以确定最适合的批量大小。
使用Elasticsearch河流概念
Elasticsearch河流概念是一种将数据从外部系统导入到Elasticsearch中的机制。河流运行在集群中的单个节点上,监听某种消息代理(如Redis、RabbitMQ、CouchDB等)。应用程序将文档推送到消息代理,河流以批量的形式拉取这些数据,再使用批量索引API将数据索引到Elasticsearch中。
直接批量索引
如果系统的性能要求不高,那么可以使用直接批量索引的方法。这种方法不需要额外的队列缓冲系统,只需要应用程序直接将数据发送到Elasticsearch即可。但是,如果数据量很大,或者数据生成速度非常快,那么这种方法可能会导致Elasticsearch无法及时处理数据,从而导致性能问题。
使用队列缓冲系统
如果系统的性能要求很高,或者数据量很大,那么可以使用队列缓冲系统。这种方法可以将应用程序与Elasticsearch解耦,使得应用程序能够以自己的速度生成数据,而Elasticsearch可以以自己的速度处理数据。队列缓冲系统可以自动重试发送失败的数据,确保数据最终能够被成功处理。
使用消息代理
可以使用消息代理来实现队列缓冲系统。消息代理是一种中间件软件,它可以存储和转发消息。应用程序将数据发送到消息代理,消息代理将数据转发到Elasticsearch。如果Elasticsearch无法及时处理数据,那么消息代理会将数据存储起来,等到Elasticsearch能够处理数据时再转发给Elasticsearch。
代码示例文章来源:https://www.toymoban.com/news/detail-845391.html
from elasticsearch import Elasticsearch
# 创建Elasticsearch客户端
client = Elasticsearch()
# 创建一个索引
client.indices.create(index='my-index')
# 准备批量索引数据
actions = [
{
'_index': 'my-index',
'_type': 'my-type',
'_id': '1',
'_source': {
'title': 'Elasticsearch Tutorial'
}
},
{
'_index': 'my-index',
'_type': 'my-type',
'_id': '2',
'_source': {
'title': 'Elasticsearch Tutorial 2'
}
}
]
# 执行批量索引
client.bulk(actions)
综上所述,优化Elasticsearch数据存储可以帮助提升系统性能、降低成本、提高数据查询效率,同时增强系统的稳定性和可靠性。这些优化措施有助于提升用户体验,提高系统的可用性,并为业务的发展提供更好的支持。所以,企业要根据自己得业务范围调整适合得代码。文章来源地址https://www.toymoban.com/news/detail-845391.html
到了这里,关于Elasticsearch数据存储优化方案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!