长短时记忆网络(LSTM)和门控循环单元(GRU)
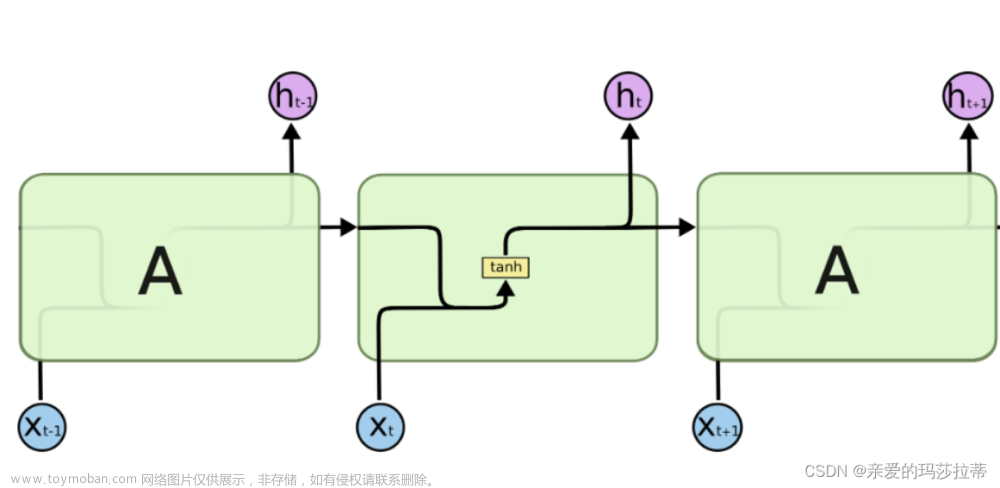
长短时记忆网络(LSTM)和门控循环单元(GRU)都是为了解决传统循环神经网络(RNN)在处理长序列数据时遇到的梯度消失问题而设计的。它们通过引入门控机制,有效地保持长期依赖信息,同时避免了梯度在时间反向传播过程中消失的问题。
一、长短时记忆网络(LSTM)
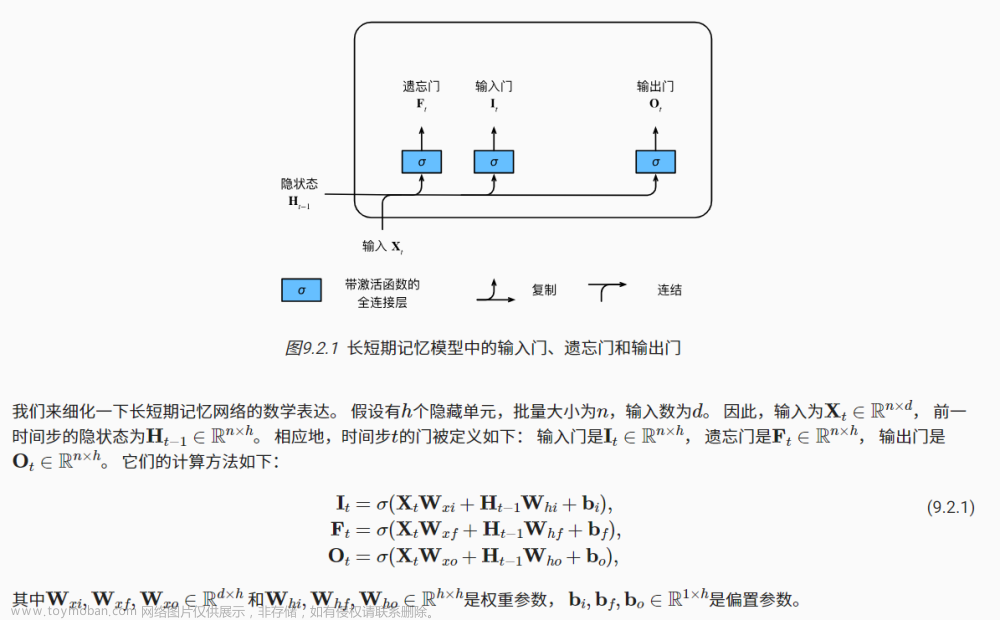
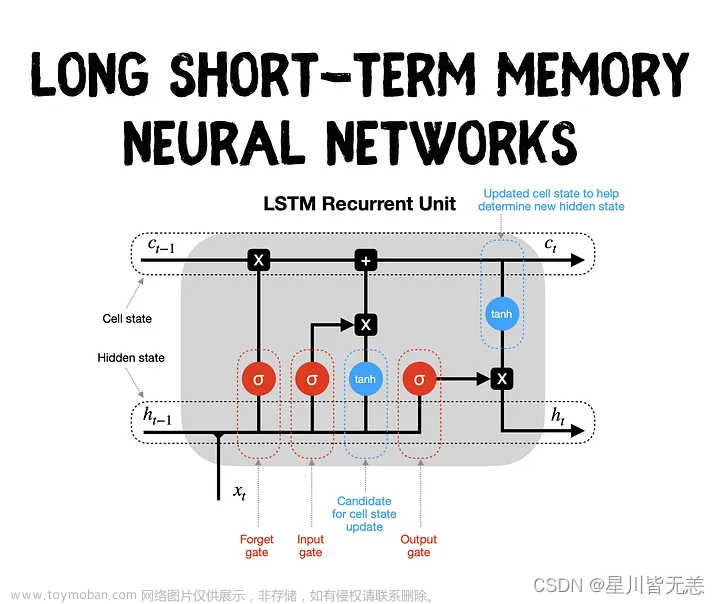
LSTM通过使用三个门(输入门、遗忘门、输出门)和一个细胞状态来解决梯度消失问题。细胞状态在网络中贯穿始终,允许信息以几乎不变的形式长时间流动。只要遗忘门允许,信息就可以在细胞状态中保留,这意味着LSTM能够保留长期依赖信息,缓解梯度消失问题。
- 输入门控制新输入信息的量,决定了有多少新信息被加入到细胞状态。
- 遗忘门决定细胞状态中有多少旧信息被遗忘。
- 输出门控制从细胞状态到隐藏状态的输出量。
LSTM的设计确保了即使在长序列中,梯度也能够有效地流动,从而使模型能够学习到长距离的依赖关系。
二、门控循环单元(GRU)
GRU是LSTM的一个变体,旨在简化LSTM的结构,同时保留其能够处理长期依赖的能力。GRU将LSTM中的遗忘门和输入门合并成一个单一的更新门,并且合并了细胞状态和隐藏状态,简化了模型的结构。
- 更新门类似于LSTM的遗忘门和输入门的结合,它决定了有多少旧的隐藏状态应该被保留,以及有多少新的信息应该被加入。
- 重置门决定了有多少过去的信息需要被忘记,它允许模型决定在计算新的输出时忽略多少历史信息。
通过这种设计,GRU能够以更少的参数实现与LSTM相似的功能,这有助于减少计算资源的需求,同时在某些任务中还可以减少过拟合的风险。文章来源:https://www.toymoban.com/news/detail-845430.html
三、比较
- 参数数量:GRU相对于LSTM来说,参数更少。这是因为GRU合并了输入门和遗忘门,并且没有细胞状态。较少的参数意味着GRU在某些情况下可能更快训练,并且需要的计算资源更少。
- 性能:尽管GRU参数更少,但在很多任务中,GRU和LSTM的性能是相似的。某些情况下,LSTM可能表现更好,而在其他情况下,GRU可能有优势。
- 选择使用哪一个:选择使用LSTM还是GRU通常取决于特定任务的性能要求、计算资源的限制以及实验结果。
总的来说,LSTM和GRU都是高效的序列模型,能够处理长期依赖问题。文章来源地址https://www.toymoban.com/news/detail-845430.html
到了这里,关于【长短时记忆网络(LSTM)和门控循环单元(GRU)】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!