项目背景
- 某电商商城随着业务量的发展,积累了大量的用户手机销售订单数据。决策层希望能够通过对这些数据的分析了解更多的用户信息及用户的分布,从而可以指导下一年的市场营销方案以及更加精准的定位市场,进行广告投放。
数据说明
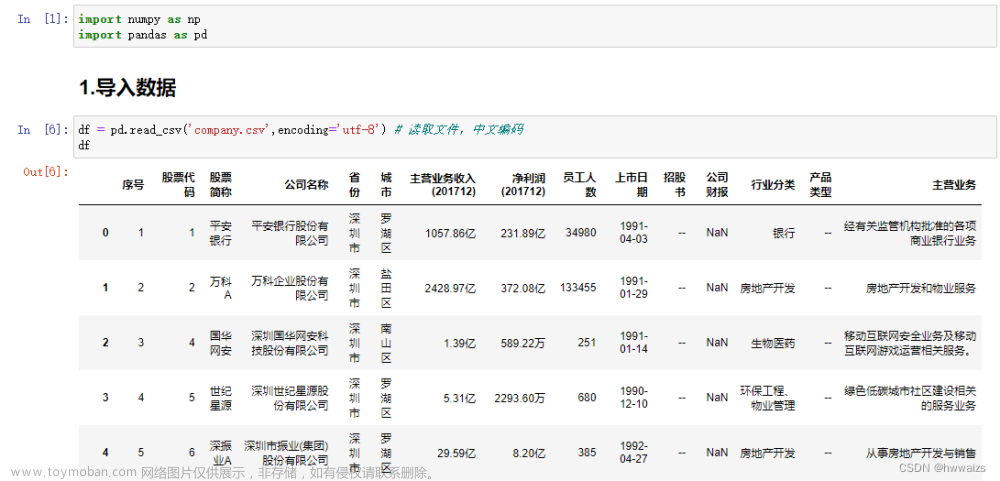
- 数据时间从 2017.01.01至2019.03.31 共41800 条,数据存储在 excel 文件 中(Phone.xlsx)。

import pandas as pd
data = pd.read_excel(‘./Phone.xlsx’)
data.head()
data.shape
(41800, 20)
- 查看缺失数据的个数和占比
#查看缺失数据
for col in data.columns:
null_count = data[col].isnull().sum()
if null_count > 0:
p = str(null_count / data[col].size * 100)+‘%’
print(col+‘:’+p)
年:100.0%
月:100.0%
年龄段:100.0%
- 缺失值处理
data[‘年’] = data[‘订单日期’].dt.year
data[‘月’] = data[‘订单日期’].dt.month
#数据分箱:
#[0-16,17-26,27-36,37-49]
data[‘年龄段’] = pd.cut(data[‘年龄’],bins=[0,16,26,36,49])
- 查看消费者对不同手机品牌的青睐程度
#查看不同品牌手机的累计销量和累计销售额,且对累计销量进行降序
data.groupby(by=‘品牌’)[[‘销售额’,‘数量’]].sum().sort_values(‘数量’,ascending=False)
- 查看不同品牌的不同型号数量
p_count_list = [] #品牌名称和品牌型号的数量
for p in data[‘品牌’].unique():
#可以将p表示品牌的行数据
p_df = data.loc[data[‘品牌’] == p]
p_count = p_df[‘型号’].nunique() #品牌对应不同型号的数量
p_count_list.append([p,p_count])
pd.DataFrame(p_count_list,columns=[‘品牌’,‘型号数量’])
#分组聚合
data.groupby(by=‘品牌’)[‘型号’].nunique()
#分类汇总
data.pivot_table(index=‘品牌’,values=‘型号’,aggfunc=‘nunique’)
- 查看不同品牌中价格最高和最低的型号是什么
data.groupby(by=[‘品牌’,‘型号’])[‘价格’].agg([‘max’,‘min’])
- 查看不同月份的销量情况,哪些月份销量比较高
data.groupby(by=‘月’)[‘数量’].sum().sort_values(ascending=False)
月
3 16582
1 16420
2 15561
12 11060
5 11026
7 10987
11 10960
8 10884
4 10863
10 10833
6 10733
9 10644
Name: 数量, dtype: int64
- 不同年龄段的购买力
data.groupby(by=‘年龄段’)[‘数量’].sum().sort_values(ascending=False)
年龄段
(16, 26] 74573
(26, 36] 68910
(0, 16] 1758
(36, 49] 1312
Name: 数量, dtype: int64
- 查看不同省份不同城市的购买力情况
data.pivot_table(index=[‘省份名字’,‘城市名字’],values=‘数量’,aggfunc=‘sum’).sort_values(‘数量’,ascending=False) 文章来源:https://www.toymoban.com/news/detail-845447.html
文章来源:https://www.toymoban.com/news/detail-845447.html
- 查看不同品牌的不同机身内存的订单量(只考虑订单量,不考虑一个订单中包含几个已购商品)
pd.crosstab(index=data[‘品牌’],columns=data[‘机身内存’])
内容来源于大数据分析课程。文章来源地址https://www.toymoban.com/news/detail-845447.html
到了这里,关于手机销量分析案例的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!