提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
关于深度学习目标检测,有许多概念性的东西需要先了解一下。这里主要以基于深度学习的目标检测算法的部署实现来学习。
一、基于深度学习的目标检测需要哪些步骤?
以yolov5为例:
使用YOLOv5进行车辆和行人的目标检测通常涉及以下步骤:
数据准备:准备包含车辆和行人的训练数据集,确保数据集中包含足够数量和多样性的车辆和行人的图像,并标注它们的位置信息。
模型选择:选择适合目标检测任务的YOLOv5模型,根据任务需求选择不同的模型大小(如YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x)。
模型训练:使用准备好的数据集对选定的YOLOv5模型进行训练。在训练过程中,模型会学习识别车辆和行人等目标的特征。
模型优化:根据训练过程中的验证结果,调整模型的超参数、学习率等,以优化模型的性能。
模型评估:使用测试数据集对训练好的模型进行评估,评估模型在车辆和行人目标检测任务上的准确率、召回率等指标。
模型部署:将训练好的YOLOv5模型部署到实际应用中,用于车辆和行人的目标检测任务。可以将模型集成到自动驾驶系统、智能监控系统等中。
实时检测:在部署后,可以利用YOLOv5模型进行实时的车辆和行人目标检测,识别图像或视频流中的车辆和行人,并提供相应的输出结果。
我逐步介绍这里面涉及到的一些内容。
二、数据准备(即准备数据集)
1.目标检测的数据集如何获取?
获取目标检测的数据集通常可以通过以下几种途径:
公开数据集:有许多公开的目标检测数据集可供使用,如COCO(Common Objects in Context)、PASCAL VOC(Visual Object Classes)、ImageNet等。这些数据集包含了各种类别的图像和相应的标注信息,可以用于训练和评估目标检测模型。
自行标注:如果需要特定领域或特定任务的数据集,可以自行收集图像数据并进行标注。标注可以包括物体的边界框、类别信息等。可以使用标注工具如LabelImg、LabelMe等进行标注工作。
第三方数据提供商:有些数据提供商提供各种类型的标注数据集,可以根据需求购买或获取这些数据集。一些公司和组织也提供定制的数据集收集和标注服务。
数据增强:除了获取现有的数据集外,还可以通过数据增强技术来扩充数据集规模,增加数据的多样性。数据增强包括旋转、翻转、缩放、亮度调整等操作,可以提高模型的泛化能力。
合作伙伴和社区:与合作伙伴、学术界或开发者社区合作,共享数据集或参与共同构建数据集,可以获得更多的数据资源和支持。
2.数据集包括训练集和验证集吗?
数据集通常包括训练集和验证集。在机器学习和深度学习任务中,训练集用于训练模型的参数,而验证集用于评估模型的性能和调整超参数。
训练集是模型用来学习特征和参数的数据集,通常包含大量的标注数据,用于训练模型进行目标检测、分类、分割等任务。训练集的目的是让模型学习到数据集中的模式和规律,以便对新的数据进行预测和分类。
验证集是用来评估模型在训练过程中的性能和泛化能力的数据集。在训练过程中,可以使用验证集来监控模型的性能,并根据验证集的表现调整模型的超参数,防止模型过拟合或欠拟合。
通常,数据集会被划分为训练集和验证集两部分,比例可以根据具体任务和数据量来确定。常见的划分比例是将数据集的大约80%用作训练集,20%用作验证集。
3.如何训练自己的数据集?
这里的方法CSDN上有许多博主都在介绍,大致的流程是:
练自己的数据集通常涉及以下步骤:
数据收集标注——对收集到的图像数据进行预处理——将数据集划分为训练集和验证集——选择适合目标检测任务的模型,如YOLOv5、Faster R-CNN、SSD——使用训练集对选定的模型进行训练
——使用验证集对训练好的模型进行评估——根据评估结果调整模型的超参数、学习率等——将训练好的模型部署到实际应用中,用于目标检测任务,可以将模型集成到自动驾驶系统、智能监控系统等中。
有一位博主利用yolov5进行训练的过程如下:
4.环境配置中的python、pycharm、numpy、panda、anaconda、tensorflow、pytorch都是什么?
①python是一门编程语言。
②pycharm是一个IDE,即集成了解释、编译、调试等各种功能的开发平台。
③numpy是Python中用于科学计算的基础库,提供了多维数组对象(ndarray)和各种数学函数。
④Pandas是建立在NumPy之上的数据处理库,提供了高级数据结构和数据分析工具,如Series和DataFrame,用于处理和分析结构化数据
⑤Anaconda 是包管理工具,也是一个解释器。
⑥TensorFlow 是由Google开发的开源深度学习框架,提供了丰富的API和工具,支持各种深度学习任务,如图像识别、自然语言处理、目标检测等
⑦PyTorch 是由Facebook开发的开源深度学习框架,也用于构建和训练深度学习模型
⑧yolo是一种深度学习的算法,可以在TensorFlow或者PyTorch构建的框架下实现。
三、目标检测性能指标
分为检测速度和检测精度。
1.检测精度
准确率(Precision):指检测出的目标中真正为目标的比例,即检测为目标且确实为目标的数量与所有检测为目标的数量的比值。即
召回率(Recall):指所有真正为目标的样本中被检测出的比例,即检测为目标且确实为目标的数量与所有真正为目标的数量的比值。
F1分数:综合考虑准确率和召回率,是准确率和召回率的调和平均值,可以帮助评估模型在准确率和召回率之间的平衡。
平均精度均值(mAP):是目标检测任务中常用的评估指标,综合考虑了不同类别的准确率和召回率,计算出每个类别的AP(平均精度),然后取所有类别AP的平均值作为最终的mAP。
交并比(IoU):指预测框与真实框之间的重叠程度,通常用于衡量目标检测算法的定位准确性。
漏检率(Miss Rate):指未检测到的目标数量与所有真实目标数量的比值,是召回率的补数。
误检率(False Alarm Rate):指被错误检测为目标的数量与所有未真实目标数量的比值,是准确率的补数。
2.检测速度
前传耗时:指模型进行一次前传(从输入到输出的计算过程)所花费的时间。前传耗时直接影响模型的推理速度,通常希望前传耗时越短越好,特别是在实时应用中,如视频分析、自动驾驶等。
FPS(Frames Per Second):指模型每秒能够处理的帧数,即模型每秒能够进行多少次推理。FPS是衡量模型推理速度的重要指标,通常希望模型的FPS越高越好,以实现实时的目标检测和识别。
FLOPS(Floating Point Operations Per Second):指模型每秒执行的浮点运算次数。FLOPS是衡量模型计算复杂度的指标,可以用来评估模型的计算资源消耗和效率。通常情况下,FLOPS越低表示模型计算效率越高。
四、YOLO目标检测系列的发展史

YOLO(You Only Look Once)是一种流行的目标检测算法,以其简单、快速和高效而闻名。以下是YOLO的发展历程:
YOLO v1:YOLO v1是于2015年由Joseph Redmon等人提出的第一个YOLO版本。YOLO v1采用单个神经网络模型,将目标检测任务转化为回归问题,通过在图像中预测边界框的坐标和类别来实现目标检测。YOLO v1的特点是速度快,但在小目标检测和定位精度上存在一定问题。
YOLO v2:YOLO v2(也称为YOLO9000)是于2016年提出的改进版本,引入了一些新的技术和优化,如使用更深的网络、多尺度训练、Batch Normalization等,提高了检测精度和泛化能力。YOLO v2还引入了目标类别的多标签预测,使得模型可以同时检测多个类别。
YOLO v3:YOLO v3是于2018年发布的最新版本,进一步改进了检测精度和速度。YOLO v3采用了更深的Darknet-53网络作为基础网络结构,引入了多尺度预测、特征融合和更细粒度的边界框预测,提高了模型的检测性能。YOLO v3还支持多种不同尺寸的输入图像,适应不同场景的需求。
YOLO v4:YOLO v4是YOLO系列的最新版本,于2020年发布。YOLO v4引入了一系列新技术和优化,如CSPDarknet53网络、Mish激活函数、SAM模块等,进一步提高了检测精度和速度。YOLO v4还支持混合精度训练、模型剪枝等技术,使得模型更加高效和灵活。
①one-stage和two-stage的区别?
Two-stage(两阶段):代表-- Fsater-rcnn Mask-rcnn系列
One-stage(单阶段):代表-- Yolo系列
简单地说,单阶段相比多阶段,更加一步到位,把图像直接输入单个神经网络后就能直接输出结果,但是两阶段算法必须先将图像生成一个可能含有目标对象的候选区域,再进一步处理。
所以,
One-stage
优势:速度非常快,适合做实时检测任务
劣势:效果通常不会太好
Two-stage
优势:效果通常比较好
劣势:速度较慢,不适合做实时检测任务
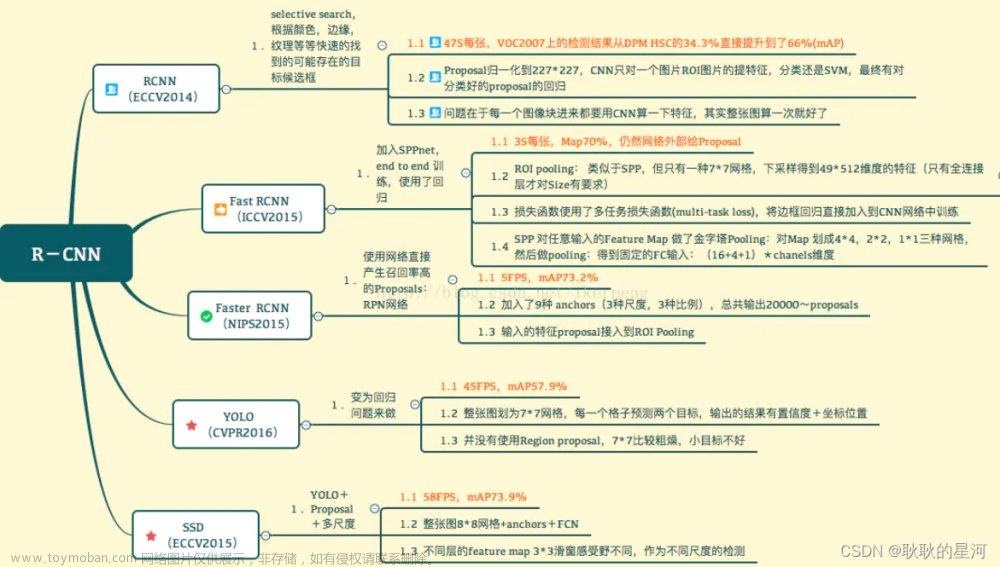
②yolo系列算法的特点

这个图可以看出,yolo系列算法的mAP(即检测精度)没有快速线性卷积神经网络(RCNN)高,但是其FPS却非常高,所以处理实时性要求高的场景比较合适。
五、YOLOV5算法的实现原理


总结就是:
①将输入图像分割成网格:YOLO5将输入图像分成S×S个网格,每个网格负责检测一个目标。如果一个目标的中心点在某个网格内,那么就会在该网格内拟合出一个边界框。
②提取特征向量:使用卷积神经网络提取每个网格的特征向量,该特征向量代表了该网格内目标的特征。
③预测边界框和类别:对于每个网格,使用全连接层来预测一个或多个边界框,以及每个边界框可能的类别和置信度得分。
④预测结果的后处理:对于每个目标,选择置信度最高的边界框。然后,根据非极大值抑制(NMS)算法去掉重复边界框并选择最终的目标框。
5.1 分割网格的作用
主要起四个作用:
减少计算量:相比于对整张图像进行目标检测,只对每个网格进行检测可以大大提高算法的运行速度。
定位目标:通过将图像分割成网格,可以更精确地定位目标的位置。每个网格负责检测其中的目标,减少目标位置的搜索范围
适应不同尺寸的目标:分割成多个网格可以更好地适应不同尺寸和比例的目标。每个网格可以独立地检测目标,无需对整个图像进行缩放或调整,从而提高了算法的鲁棒性。
多尺度检测:通过将图像分割成多个网格,可以实现多尺度的目标检测。不同大小的目标可能出现在不同大小的网格中,这样可以更全面地检测图像中的目标。
5.2 对划分出来的每个网格都使用一次卷积神经网络来提取特征向量吗?
在YOLO算法中,每个网格都会经过一次卷积神经网络的前向传播过程,从而提取该网格内目标的特征向量。这些特征向量将用于后续的目标边界框和类别的预测。
至于如何用CNN进行特征提取的,这个就是先送入池化层减少复杂度,简单的卷积层进行滑动窗口的卷积操作得到一个特征矩阵,然后送入全连接层,进行特征映射、非线性变换和参数学习,最终得到输出特征图。
5.3 每个边界框的类别和置信度是怎么得出的?
在全连接层后,通常会使用softmax函数将网络输出转换为概率分布,以表示每个类别的可能性。
5.4 非极大值抑制(NMS)算法是什么?
非极大值抑制(Non-Maximum Suppression,NMS)是一种常用的目标检测算法后处理技术,用于去除重叠边界框并选择最终的目标框。其主要思想是在检测到的多个边界框中,保留置信度最高的边界框,同时抑制与该边界框重叠度较高的其他边界框。
NMS算法的步骤如下:
①按照置信度排序:首先,对所有检测到的边界框按照其置信度得分进行排序,置信度高的边界框排在前面。
②选择置信度最高的边界框:从排好序的边界框列表中选择置信度最高的边界框,并将其添加到最终的目标框列表中。
③计算重叠度:对于剩余的边界框,计算它们与已选中的最高置信度边界框的重叠度(如IoU,交并比)。
④去除重叠边界框:对于重叠度高于设定阈值的边界框,将其从列表中去除,只保留重叠度较低的边界框。
⑤重复操作:重复以上步骤,直到所有边界框都被处理完毕。
通过非极大值抑制算法,可以有效地减少重叠边界框,保留置信度最高的边界框,从而得到最终的目标检测结果。NMS算法在目标检测领域被广泛应用,能够提高检测结果的准确性和稳定性。
六、实现一个yolov5目标检测的项目,需要哪些基础的软件和环境配置呢?
要实现一个YOLOv5目标检测项目,需要以下基础的软件和环境配置:
Python环境:YOLOv5是基于Python实现的,因此需要安装Python环境。推荐使用Python 3.6及以上版本。
PyTorch:YOLOv5使用PyTorch作为深度学习框架,因此需要安装PyTorch。可以通过PyTorch官方网站提供的安装指南安装对应版本的PyTorch。
CUDA和cuDNN:如果要在GPU上加速训练和推理过程,需要安装相应版本的CUDA和cuDNN,并配置PyTorch以支持GPU加速。
YOLOv5代码库:下载YOLOv5的代码库,可以从GitHub上的ultralytics/yolov5仓库获取。可以使用git命令克隆代码库或直接下载zip文件。
依赖库:安装项目所需的依赖库,如NumPy、OpenCV、Matplotlib等。可以通过pip或conda安装这些库。
数据集:准备用于训练和测试的目标检测数据集。可以使用已有的数据集,也可以自行收集和标注数据集。
预训练模型:下载YOLOv5的预训练模型权重,可以从YOLOv5官方发布的权重文件中获取。文章来源:https://www.toymoban.com/news/detail-845523.html
配置文件:根据项目需求,可以修改YOLOv5的配置文件,如模型结构、超参数设置等。文章来源地址https://www.toymoban.com/news/detail-845523.html
到了这里,关于YOLOv5目标检测学习(1):yolo系列算法的基础概念的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!